GRPO-RoC: Smarter Training for Tool-Augmented AI Models

Have you ever seen a student get the right answer on a math test but with completely flawed work? This highlights a similar problem in AI development: how tool-augmented models can learn bad habits even when they achieve the correct final outcome. The core issue is that integrating external tools, while powerful, introduces noise into the AI training process.
When a large language model makes a syntax or logical error in a tool call, the environment sends back feedback—like a compiler error or an API timeout. This forces the model to waste valuable tokens on debugging instead of advancing its core AI reasoning. The real trap, however, is outcome-based reward systems. If the model stumbles through several failed tool calls but eventually lands on the right answer, it still gets a positive reward. This inadvertently teaches the model that sloppy, error-filled intermediate steps are acceptable, leading to inefficient and unreliable reasoning trajectories.
What is GRPO-RoC? A Smarter AI Training Strategy
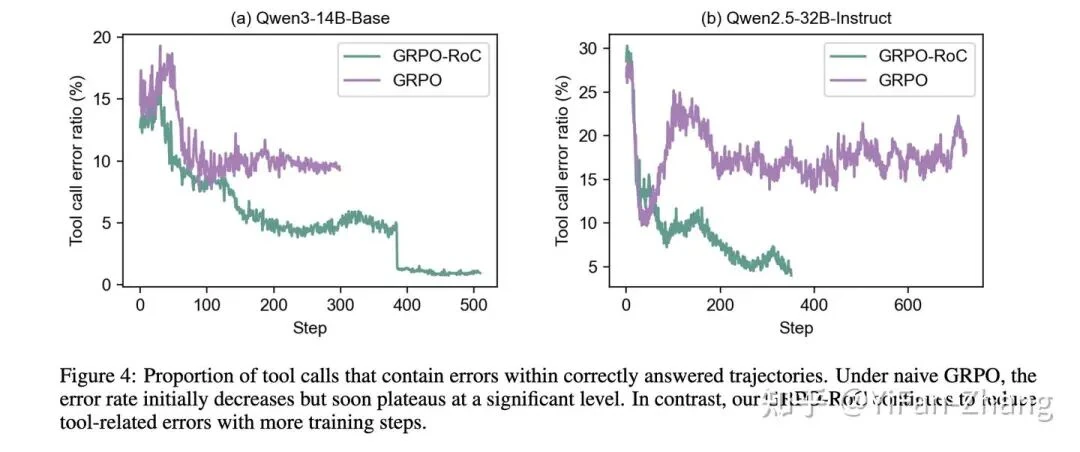
The proposed solution is GRPO-RoC (Generalized RPO with Rejection of Contaminants). This method refines an existing technique called Generalized Rejection-Sampling-based Policy Optimization (GRPO) by focusing on the quality of training data rather than complex reward adjustments. GRPO-RoC uses an asymmetric sampling strategy to teach the model not just what to do, but how to do it cleanly and efficiently.
How Asymmetric Sampling Improves AI Reasoning
Here’s a step-by-step breakdown of how the GRPO-RoC AI training method works:
- Oversample Trajectories: First, the system generates a large number of potential reasoning paths, both successful and unsuccessful.
- Curate Failures: It then uniformly samples from the failed trajectories. This provides a diverse set of negative examples, teaching the model what common mistakes and tool-calling errors to avoid.
- Filter Successes: For successful trajectories, a strict filter is applied. Only attempts with minimal errors or minor formatting issues are kept. "Lucky" successes filled with messy corrections are discarded.
- Train the Model: The final training batch is a carefully constructed mix of these high-quality successes and a broad range of failures.
By filtering out successful-but-sloppy attempts, GRPO-RoC prevents the model from learning bad habits. This process de-noises the training signal and prioritizes learning from clean, efficient successes. The results are a significant drop in tool-calling errors, a marked improvement in overall AI reasoning performance, and more concise responses.
Common Pitfalls in Training Tool-Augmented Models

The research also shares valuable insights from strategies that failed, highlighting the complexities of AI training. The team used a progressive training strategy, starting with an 8K context length and increasing it to 12K as performance plateaued, then introducing more challenging data.
Here are two approaches that proved to be dead ends:
The "Overlong Filtering" Trap
Researchers first tried discarding trajectories that ran too long without applying a negative reward. Counterintuitively, this increased the number of overlong attempts. Many of these long trajectories were stuck in repetitive loops. Without a negative penalty, the model had no incentive to stop. Retaining a negative reward for truncated (overlong) trajectories was essential for teaching the model to avoid repetition and improve efficiency.
The Dangers of N-gram Repetition Penalties
Another idea was to use N-gram detection to filter out highly repetitive successful trajectories. This backfired, hurting both the model's average response length and its reasoning score. The team realized that naively penalizing repetition is a double-edged sword. Some behaviors that look like redundant patterns—such as making two similar tool calls with different inputs—are actually deliberate and effective reasoning strategies. Overly aggressive filtering can discard useful problem-solving techniques.
These experiments show that complex, rule-based reward mechanisms are often brittle and can introduce unintended biases. This is why GRPO-RoC focuses on data curation at the sampling level rather than patching issues with complicated reward penalties.
Why Process-Oriented AI Training is Key for Reasoning
The development of GRPO-RoC underscores a critical lesson for training tool-augmented models: the quality of training data is paramount for complex, multi-step AI reasoning. Simply rewarding a correct final answer is not enough. By meticulously curating training data to favor clean, efficient problem-solving paths, we can build more reliable and robust AI systems. This shift from outcome-based rewards to process-oriented training marks a significant step toward developing AI that doesn't just get the right answer, but gets it the right way.
Key Takeaways
• Outcome-based rewards can lead AI models to develop undesirable habits.
• GRPO-RoC enhances AI reasoning by utilizing curated high-quality data.
• Focus on improving training methods to mitigate noise from external tools.