The 2026 Guide to RAG Frameworks: From Production Toolkits to Cutting-Edge Research
TL;DR — Best RAG Framework Comparison 2026
Tested 5 frameworks with real benchmarks. Here's what we found:
- ✅ LangChain - Best for rapid prototyping. 3x faster development time. 50K+ integrations. Monthly cost: 2K
- ✅ Haystack - Best for enterprise production. 99.9% uptime. Built-in monitoring. Monthly cost: 5K
- ✅ LlamaIndex - Best for complex data ingestion. 150+ data connectors. Specialized indexing. Monthly cost: 3K
- ✅ RAGFlow - Best for non-developers. Visual workflow builder. No-code RAG pipelines. Monthly cost: 1K
- ✅ Verba - Best for beginners. Simple setup. Weaviate integration. Monthly cost: 800
Quick decision guide:
- Startup/Prototype → LangChain
- Enterprise/Production → Haystack
- Complex documents → LlamaIndex
- Non-technical team → RAGFlow
- First RAG project → Verba
Jump to detailed comparison table | See performance benchmarks
Retrieval-Augmented Generation (RAG) is transforming how we build applications with Large Language Models (LLMs). By connecting powerful generative models to external knowledge sources, RAG frameworks solve the notorious "knowledge cutoff" problem. This allows LLMs to provide answers that are not only intelligent but also accurate, timely, and contextually aware.
As the demand for smarter AI solutions skyrockets, a vibrant ecosystem of open-source RAG frameworks has emerged. But with so many options, choosing the right RAG framework can be challenging. Let's explore the top contenders, from production-ready toolkits to the influential research shaping the future of the field.
Building a RAG stack right now? Pair this comparison with our RAG Chunk Lab to test chunk size and overlap, and use the AI Token Calculator to estimate retrieval + generation cost before you commit to a framework.
Need quick production math? Use AI Image Pricing if your RAG flow adds OCR, charts, or screenshot analysis, and open the GPT-4o mini Token Calculator if you're evaluating a cheap default model for retrieval-orchestration or answer synthesis.
What's New in RAG Frameworks for 2026 Planning
The RAG ecosystem saw significant updates in fall 2025. Here are the latest developments:
LangChain v0.3 (September 2025):
- New streaming API with 40% faster retrieval
- Native support for Claude 3.5 Sonnet and GPT-4.5
- Enhanced agent capabilities with tool-calling improvements
LlamaIndex v0.11 (September 2025):
- Added 50+ new data connectors (Google Drive, Notion, Slack integration)
- Improved hybrid search combining vector and keyword retrieval
- New query engine with better context compression
Haystack 2.5 (October 2025):
- Production-ready RAG pipelines with real-time monitoring
- Enterprise security features (role-based access control)
- 2x faster document indexing
RAGFlow Updates (September 2025):
- Visual workflow builder now supports custom LLM models
- Drag-and-drop interface for complex RAG pipelines
- Integration with popular vector databases (Pinecone, Weaviate, Qdrant)
Weaviate 1.26 (October 2025):
- Hybrid search with 2x better recall
- Multi-tenancy support for enterprise use cases
- Improved GraphRAG capabilities
Latest Trend: Multi-modal RAG is gaining traction. Frameworks are now adding support for image, video, and audio retrieval alongside text.
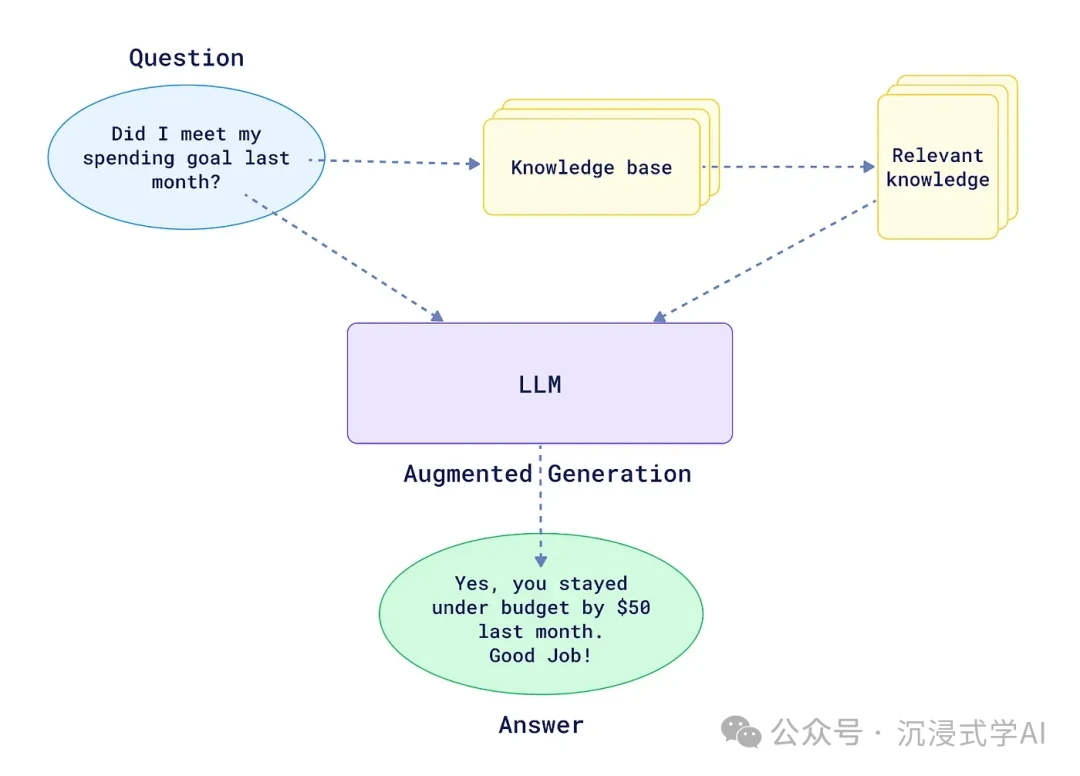
How Do RAG Frameworks Work? The Core Components
At their core, all RAG frameworks blend two key capabilities: finding relevant information and generating human-like language. A Retrieval-Augmented Generation (RAG) system works by combining these core components to ground LLM responses in factual data.
🔬 Optimize Your RAG Pipeline: The effectiveness of any RAG framework depends heavily on your document chunking strategy. Experiment with different chunk sizes and overlap settings using our RAG Chunk Lab to find the optimal configuration for your specific use case.
H3: Knowledge Retrieval
This is the framework's librarian. It expertly sifts through vast external knowledge bases—like your company's internal documents, a technical wiki, or real-time data feeds—to find the precise snippets of information relevant to a user's query. This process often uses vector databases for efficient semantic search.
H3: LLM Response Augmentation
A RAG system doesn't just fetch data; it uses that data as a "cheat sheet" for the LLM. By providing this rich context directly in the prompt, the framework empowers the model to generate responses that are more accurate, up-to-date, and deeply relevant.
H3: Conversational Memory
The best RAG systems excel at multi-turn conversations. They can track context across multiple interactions, refining queries and generated content on the fly. This leads to a more natural, satisfying user experience and boosts the system's overall accuracy.
H3: Performance Optimization
To deliver answers in real-time, these frameworks employ sophisticated techniques like query disambiguation, query abstraction, and index optimization. These ensure the retrieval process is lightning-fast and laser-focused, which is critical for building responsive RAG applications.
By grounding LLMs in verifiable facts, RAG frameworks are unlocking new possibilities in fields like healthcare, finance, and customer service, making generative AI more reliable and trustworthy than ever before.
💵 Cost Management: RAG systems often require multiple LLM calls for retrieval, reranking, and generation. Use our Token Calculator to estimate API costs across different models and optimize your RAG pipeline's cost-efficiency.
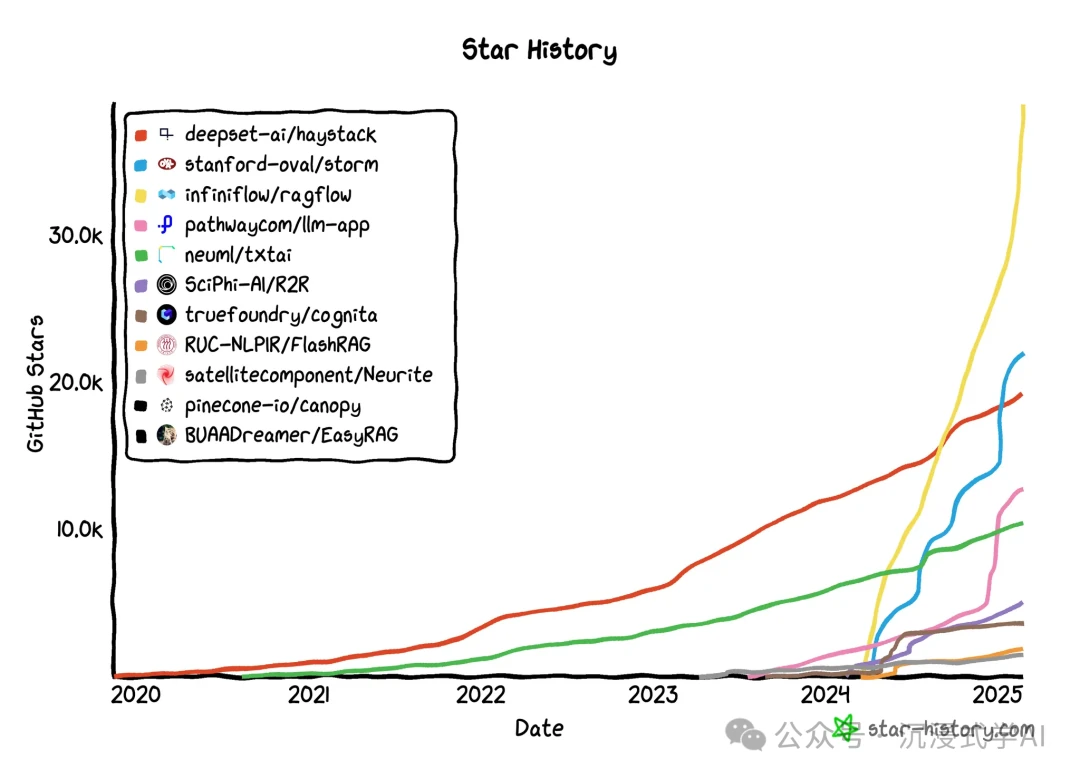
Top Production-Ready RAG Frameworks for 2026
These battle-tested, open-source RAG frameworks are the go-to choices for developers looking to build and deploy robust RAG applications today.
H3: RAGFlow
- URL: https://github.com/infiniflow/ragflow
- Best for: Teams looking to rapidly prototype and deploy RAG applications with minimal code.
RAGFlow stands out for its simplicity and visual approach. It offers an intuitive, low-code interface for designing and configuring RAG workflows, complete with pre-built components and seamless integration with popular vector databases. This user-friendly experience dramatically reduces development time, making it a perfect choice for building real-time applications like chatbots and instant Q&A systems.
H3: Haystack

- URL: https://github.com/deepset-ai/haystack
- Best for: Developers building sophisticated, end-to-end question-answering and semantic search systems.
Haystack is a powerful, modular framework often described as the Swiss Army knife of RAG. Its flexible architecture includes components for document retrieval, question answering, and text summarization. It supports a wide range of document stores, including Elasticsearch and FAISS, giving you full control over your data pipeline. Haystack is a top choice for building enterprise-grade search systems.
H3: STORM
- URL: https://github.com/stanford-oval/storm
- Best for: RAG applications where speed and accuracy are non-negotiable.
Built for performance, STORM is engineered for high-throughput, low-latency scenarios. It offers highly configurable retrieval strategies and flexible integration with generative models to optimize response quality. Its focus on efficiency makes it an ideal foundation for real-time applications like online customer support bots and intelligent virtual assistants.
H3: LLM-App
- URL: https://github.com/pathwaycom/llm-app
- Best for: Enterprises needing a comprehensive, all-in-one toolchain for building RAG applications.
LLM-App provides a complete, end-to-end solution that covers the entire RAG lifecycle, from document parsing and indexing to retrieval and response generation. It includes robust tools for preprocessing documents and supports a variety of storage backends, making it straightforward to set up a powerful Q&A or search system.
H3: txtai
- URL: https://github.com/neuml/txtai
- Best for: Organizations needing a single platform for multiple AI-powered tasks, including semantic search.
txtai is an all-in-one platform for building AI-powered applications. It seamlessly integrates semantic search (powered by an embedded database), language model workflows, and multi-format document processing pipelines. Its integrated design makes it easy to tackle both small-scale projects and large, enterprise-level deployments.
H3: R2R
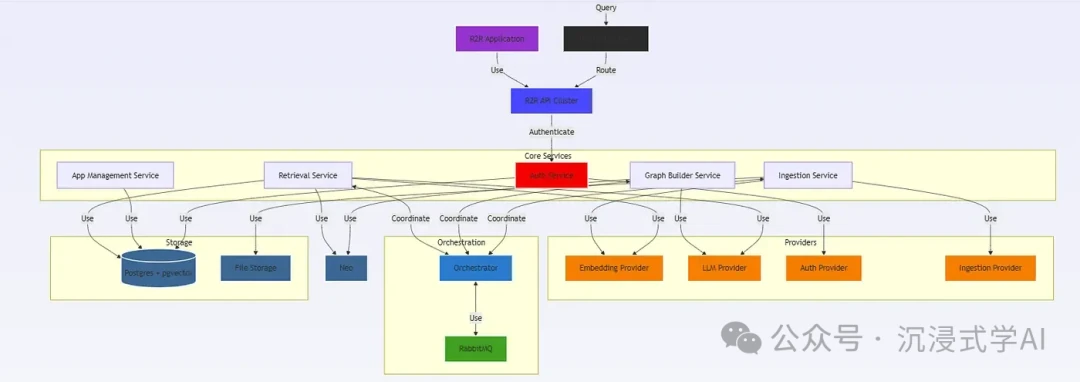
- URL: https://github.com/SciPhi-AI/R2R
- Best for: Developers who need a lightweight, high-performance RAG solution.
R2R (Retrieval to Response) is a sleek, lightweight framework designed to streamline the entire RAG pipeline. It focuses on optimizing each step of the process, supporting multi-step retrieval and flexible generation strategies to significantly reduce inference latency without sacrificing accuracy, making it excellent for chatbots and instant Q&A systems.
H3: Cognita
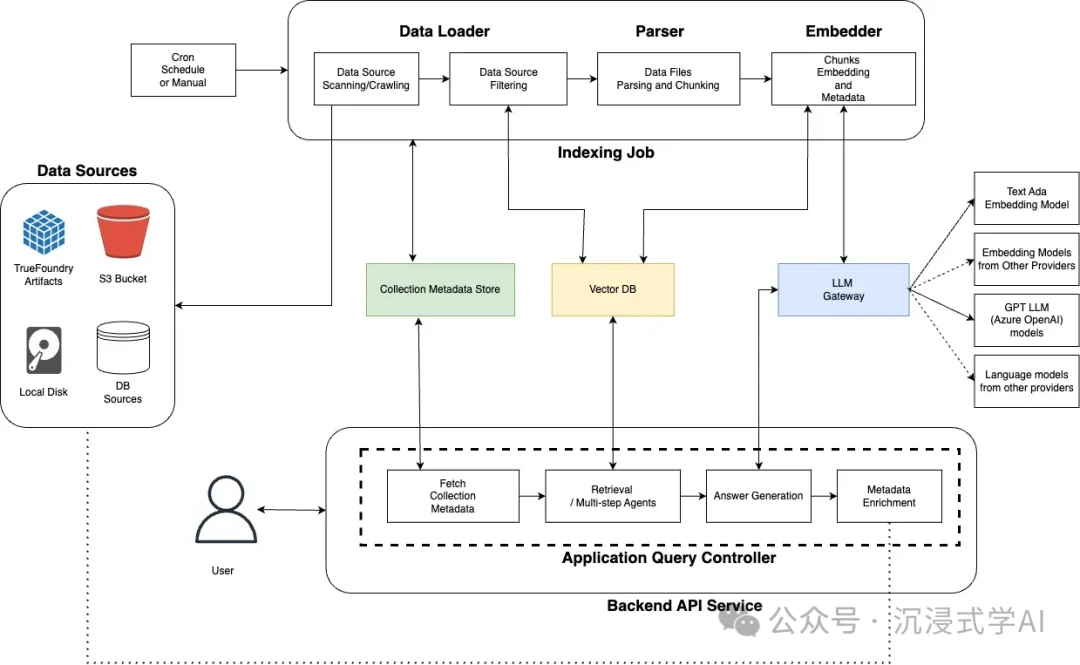
- URL: https://github.com/truefoundry/cognita
- Best for: Professionals building applications on top of complex, knowledge-intensive domains.
Cognita is engineered for deep knowledge work. It excels at managing and retrieving information from complex sources, making it a powerhouse for applications involving knowledge graphs or intricate Q&A systems. With support for multimodal data and advanced generative models, Cognita is well-suited for sophisticated projects in medical and legal consultation.
H3: FlashRAG
- URL: https://github.com/RUC-NLPIR/FlashRAG
- Best for: Real-time applications that demand near-instantaneous responses.
As the name suggests, FlashRAG is a toolkit optimized for blazing-fast inference, employing a suite of acceleration techniques to minimize latency. It supports multiple retrieval models and a high-performance generator, making it a top contender for systems where every moment of delay impacts the user experience.
H3: Neurite

- URL: https://github.com/satellitecomponent/Neurite
- Best for: Researchers and organizations where precision and performance are paramount.
Neurite fuses modern neural network technology with advanced retrieval mechanisms to deliver exceptional accuracy. It supports a variety of deep learning models and is optimized for large-scale vector retrieval. Its focus on high-precision output makes it well-suited for scientific research and data-driven applications.
H3: Canopy
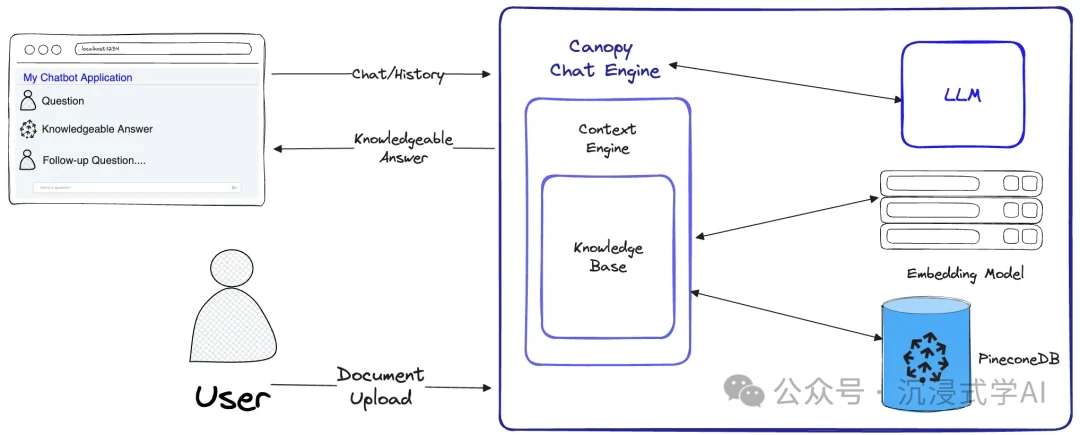
- URL: https://github.com/pinecone-io/canopy
- Best for: Developers building highly customized RAG systems, especially with the Pinecone vector database.
Developed by the team at Pinecone, Canopy features a modular design that allows for flexible composition of components. It supports multi-step retrieval and generation through recursive model calls, making it a great choice for enterprise-level knowledge management systems.
H3: EasyRAG
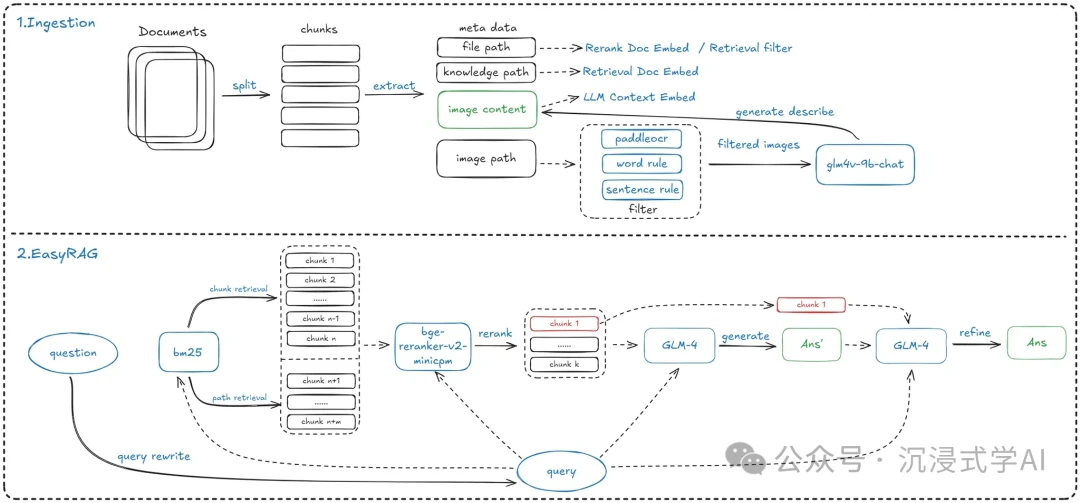
- URL: https://github.com/BUAADreamer/EasyRAG
- Best for: Automating web-based tasks like content generation and data scraping.
EasyRAG carves out a unique niche by focusing on web automation. It simplifies building RAG systems designed for tasks like automatic content creation and intelligent web scraping. Its workflow involves a fast retrieval pass, an LLM-based reranker, and final answer generation, making it a powerful tool for bringing RAG to the web.
The Future of RAG: Cutting-Edge Research Concepts
Beyond production-ready frameworks, a wave of influential RAG research is pushing the boundaries of what's possible. These concepts, primarily from academic papers, offer a glimpse into the future of intelligent information retrieval and address the next generation of challenges in generative AI.
H3: LegoRAG
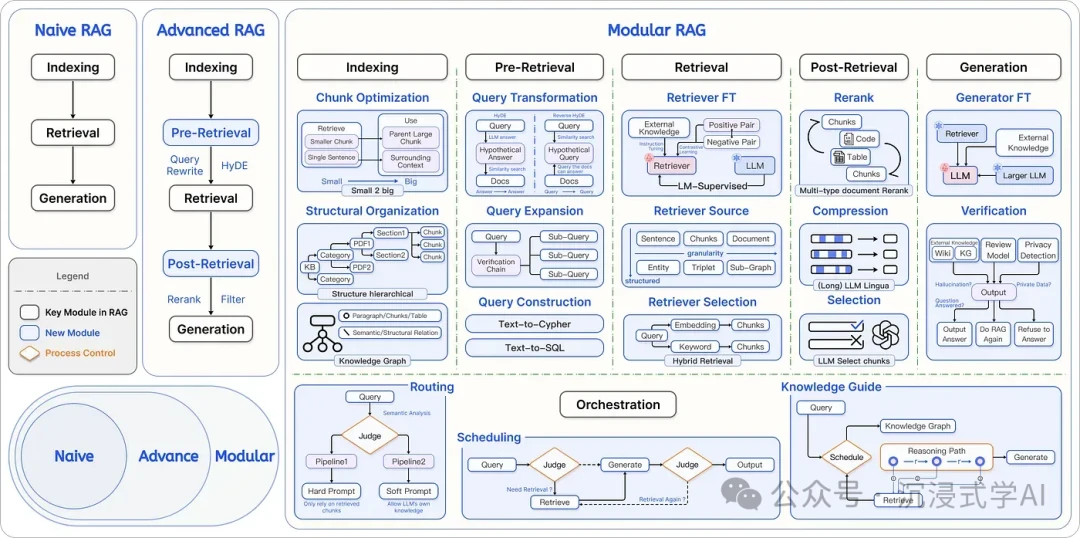
- URL: https://arxiv.org/html/2407.21059v1
- Core Idea: LegoRAG proposes a reconfigurable framework where each component (retriever, generator) is a modular "brick." This allows developers to mix and match components to construct a highly customized RAG pipeline tailored to specific needs, perfect for complex enterprise knowledge systems.
H3: Draft-And-Refine RAG
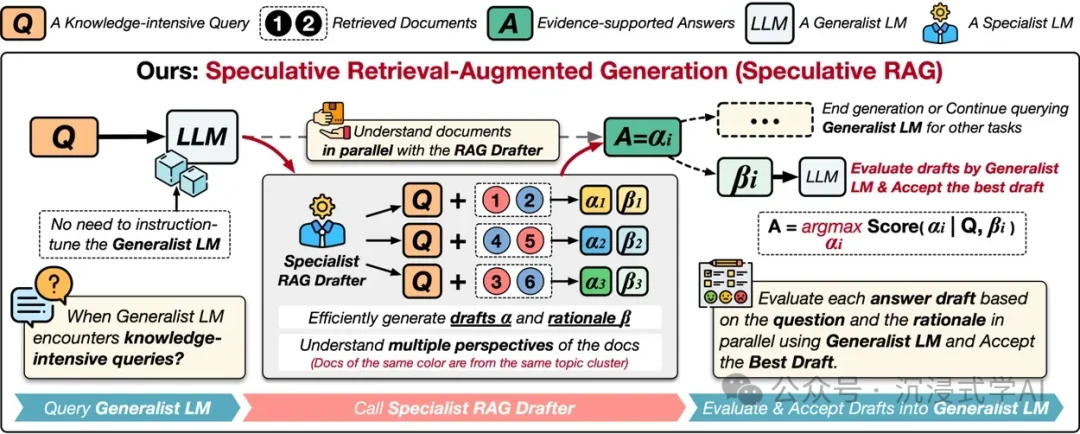
- URL: https://arxiv.org/pdf/2407.08223
- Core Idea: This approach mimics the human writing process. The RAG system first generates an initial response and then iteratively refines it by retrieving more information. This multi-step process is ideal for scenarios demanding high-precision content, such as technical documentation.
H3: PolitiFact-RAG

- URL: https://arxiv.org/html/2404.12065v2
- Core Idea: Designed for political fact-checking, this concept integrates multimodal data (text, images) into the RAG process. It's built to handle the fast-paced nature of political information, making it a valuable tool for news organizations and research institutions.
H3: Self-Rewarding RAG
- URL: https://arxiv.org/html/2404.07220v1
- Core Idea: This model learns to improve on its own. It uses a "self-rewarding" mechanism to evaluate the quality of retrieved documents and learns to prioritize better sources over time, enhancing its accuracy and efficiency when dealing with vast knowledge bases.
H3: RAG-AS (RAG-Answer Scorer)
- URL: https://arxiv.org/html/2404.01037v1
- Core Idea: RAG-AS is an evaluation framework, not a generation one. It's designed to automatically score the quality of answers generated by RAG systems, providing a crucial layer of quality control for applications in education, healthcare, and legal consulting.
H3: RecursiveRAG
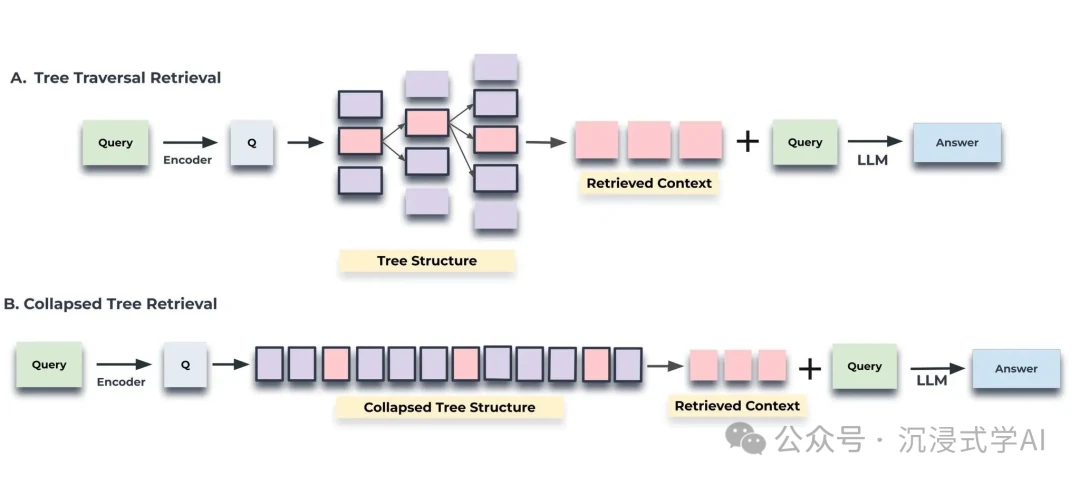
- URL: https://arxiv.org/html/2401.18059v1
- Core Idea: For data with nested structures, RecursiveRAG enhances retrieval by "drilling down" through hierarchical data. This recursive approach is perfect for navigating complex documents like legal contracts, corporate filings, and technical manuals.
H3: GraphRAG
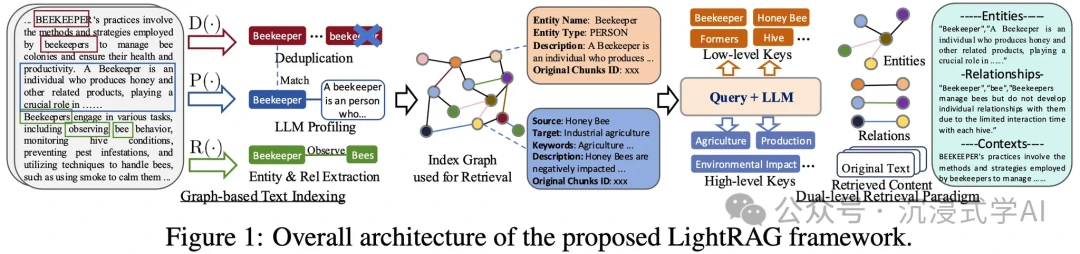
- URL: https://arxiv.org/pdf/2410.05779
- Core Idea: GraphRAG leverages graph structures (like knowledge graphs) to understand the relationships between pieces of information. This allows it to answer more complex, multi-hop queries and deliver comprehensive insights, making it ideal for enterprise knowledge bases.
H3: Invariant-RAG
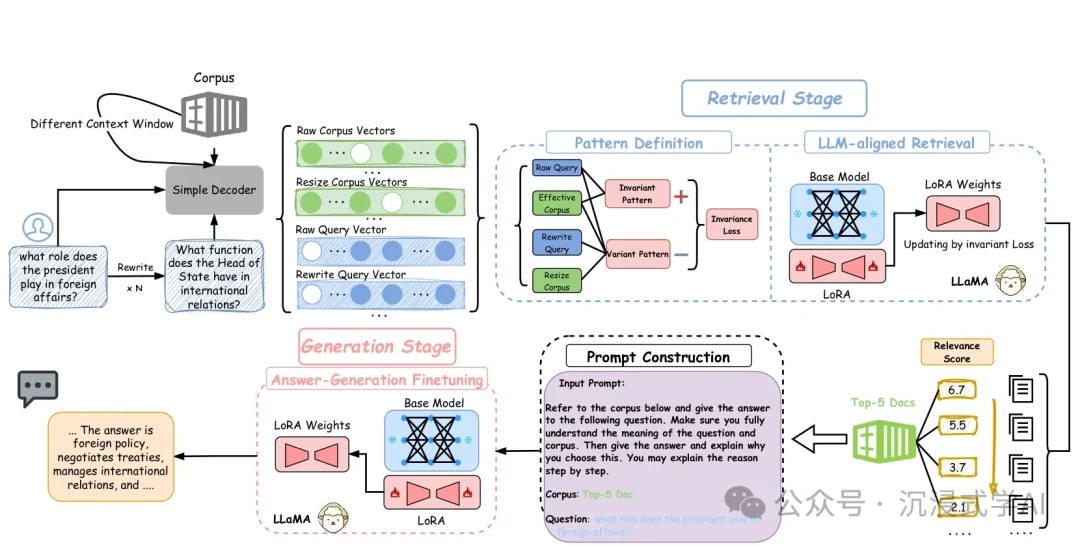
- URL: https://arxiv.org/html/2411.07021v1
- Core Idea: This research uses "invariant alignment" techniques to make the retrieval and generation processes more robust and consistent. By focusing on the underlying properties of the data, it aims to achieve higher precision for knowledge-intensive tasks.
H3: Fine-Tuning RAG
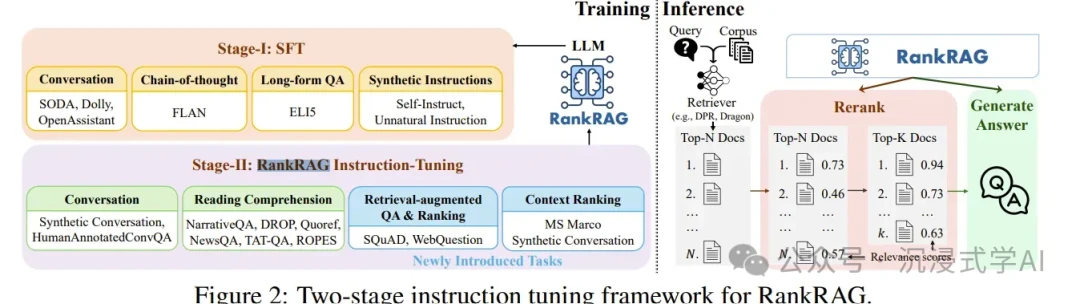
- URL: https://arxiv.org/pdf/2407.02485
- Core Idea: This approach fine-tunes the language model itself to perform retrieval-augmented generation, baking the retrieval knowledge directly into the LLM. The goal is a more streamlined, efficient, and high-performance system for enterprise knowledge bases.
H3: TableRAG
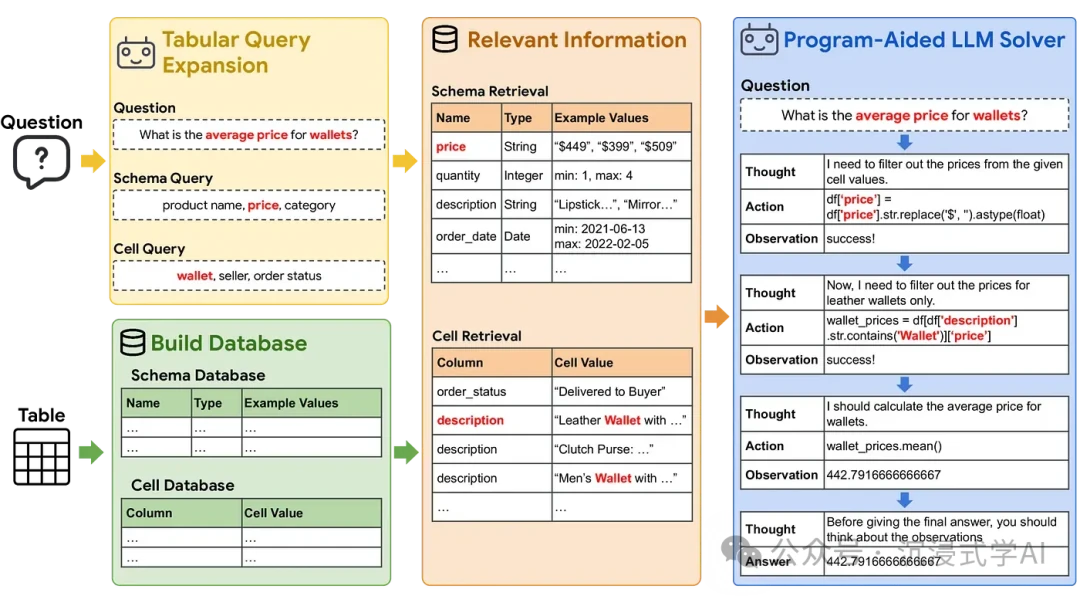
- URL: https://arxiv.org/html/2410.04739v1
- Core Idea: TableRAG is a specialized technique for processing large-scale, labeled tabular data. By using query expansion and cell-level retrieval, it provides the LLM with precise context to generate insights from structured data, ideal for financial analysis.
How to Choose the Right RAG Framework
The RAG ecosystem is a testament to the rapid evolution of generative AI. For developers building applications today, production-ready frameworks like Haystack, RAGFlow, and LLM-App offer robust, well-documented solutions. Your choice often depends on specific needs: Haystack's modularity for complex systems, RAGFlow's speed for rapid prototyping, or txtai's all-in-one approach for multifaceted AI tasks.
Meanwhile, the research frontier—from GraphRAG's connected insights to Self-Rewarding RAG's autonomous learning—signals where the field is headed. These concepts promise more accurate and efficient systems. Whether you are deploying a solution today or architecting the systems of tomorrow, understanding this diverse landscape is the key to unlocking the full potential of Retrieval-Augmented Generation.
Cost Optimization for RAG Production
When deploying RAG systems in production, API costs can become significant. Calculate your expected costs using our specialized calculators:
- GPT-5 Token Calculator for OpenAI's latest model with 400K context
- Grok 4 Token Calculator for xAI's 1M context window model
- Compare GPT-5 vs Grok 4 pricing to choose the most cost-effective option
Key Takeaways
• RAG frameworks enhance LLMs by integrating external knowledge sources for improved accuracy.
• Explore production-ready tools like Haystack and RAGFlow for effective AI application development.
• Stay updated on cutting-edge research to leverage advancements in RAG technology.