Overcoming AI Agent Limitations: Latency, Planning, and Reflection
Major technology firms are launching AI agent-building platforms, heralding a new era of automation. Yet, many of these advanced AI agents feel surprisingly similar to task bots from a decade ago, and in some cases, are less reliable. This is a symptom of critical issues plaguing today's agentic AI technology.
Key challenges for modern AI agents include:
- The Latency Lag: The planning phase for an AI agent can be painfully slow, as adding more tools often requires a slower, more powerful model to maintain accuracy.
- Brittle Planning: Unlike rigid workflows, AI agents improvise plans. This ad-hoc approach often fails on complex tasks where a structured plan would succeed.
- The Reflection Trap: An agent's ability to 'reflect' on mistakes can lead to unproductive, repetitive loops without proper guardrails.
Treating an AI agent as a simple 'LLM + tool-calling API' combination is not enough. This guide deconstructs these problems and explores robust engineering solutions to build more effective AI agents.
Solving the Latency Bottleneck in AI Agents
At its core, the speed problem in AI agents stems from the high computational overhead of dynamic tool discovery and parameter mapping. Unlike a pre-compiled workflow, an agent makes decisions at runtime, solving a massive combinatorial optimization problem to select the right tool from potentially hundreds of options. As the toolset grows, this search space explodes exponentially.
Here’s how to reduce AI agent latency:
1. Implement Hierarchical Tool Management
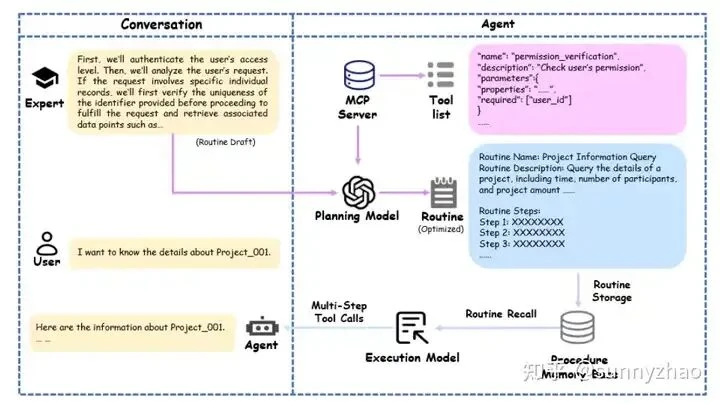
Instead of presenting a hundred tools at once, use a simple intent classifier to route requests to a specific domain, like 'data queries' or 'document processing.' Each domain then exposes a smaller, manageable set of 5-10 tools. This mirrors the principle of multi-agent systems, where specialized agents handle different tasks using a Multi-agent Communication Protocol (MCP).
2. Use Parallel Execution with DAGs
Many tool calls are not interdependent. Frameworks like LLMCompiler can compile a plan into a Directed Acyclic Graph (DAG), and OpenAI's Agents SDK supports parallel execution. This allows independent tasks to run simultaneously, significantly cutting pipeline latency. For example, switching from serial to parallel execution for independent search queries can reduce latency by over 20%.
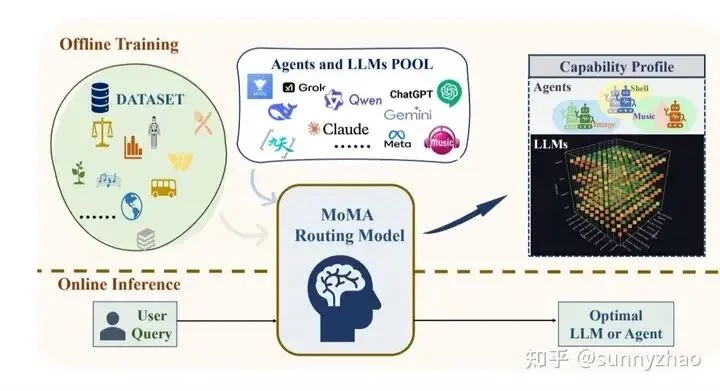
3. Leverage Smart Routing with SLMs
A router can send simple, standardized subtasks to a small, fast language model (SLM) or a dedicated script. The heavy lifting—complex planning and error handling—is reserved for a powerful flagship model. Research on RouteLLM and MoMA demonstrates this design's feasibility by establishing a clear boundary between simple and complex tasks.
Improving Brittle Planning in Agentic AI
The root cause of brittle planning is that plans generated by LLMs are often high-level intentions, not rigorous, executable programs. A traditional workflow has explicit branching, loops, and error handling. An LLM's plan, by contrast, is often a simple to-do list that breaks down when faced with real-world complexity. To make agent planning more robust, consider these strategies:
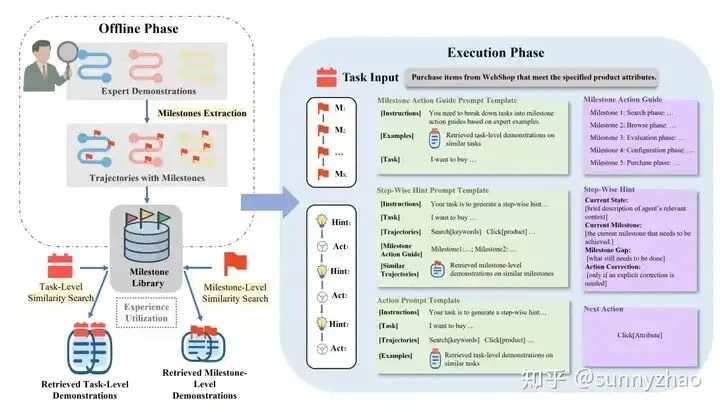
1. Deconstruct Tasks with Hierarchical Planning
The HiPlan approach splits planning into two layers: high-level 'milestones' and low-level 'prompts.' A master planner focuses on strategic goals, while a subordinate executor handles tactical details. This decoupling makes the overall plan more stable and allows milestones to be saved and reused.
2. Enforce Structure with a Domain-Specific Language (DSL)
Instead of letting the model generate free-form text, provide a structured planning framework using a Domain-Specific Language (DSL). This forces the model to output a plan that follows a valid, machine-readable syntax, which has been shown to improve tool-calling accuracy by over 20 percentage points in enterprise scenarios.
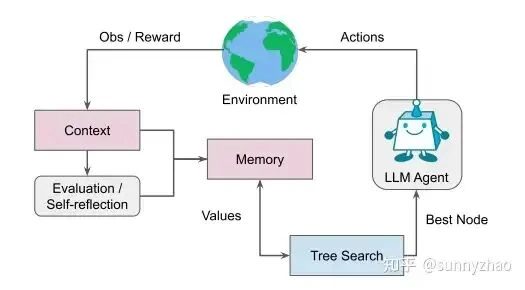
3. Explore Paths with Language Agent Tree Search (LATS)
Frameworks like LATS (Language Agent Tree Search) integrate Monte Carlo Tree Search (MCTS) into the agent's decision-making. The agent explores multiple potential paths, uses a 'Verifier' to score them, and proceeds with the most promising one. HyperTree and Graph-of-Thoughts extend this concept to support more complex planning structures.
4. Improve Success Rates with Reinforcement Learning (RL)
Multi-turn training with reinforcement learning (RL) has emerged as a powerful method for improving agent performance. Studies like RAGEN and LMRL-Gym show that RL training leads to significant improvements in success rates on complex, multi-step tasks.
Avoiding the Reflection Trap in AI Agent Loops
AI agents get stuck in endless reflection cycles because the feedback they rely on is often ambiguous and lacks a clear termination signal. A vague signal like, 'I think something went wrong,' can cause the model to double down on a flawed assumption. More structured approaches are needed to learn from failure.
Use Unary Feedback for Self-Correction
The UFO (Unary Feedback as Observation) technique uses the simplest feedback possible: 'Try again.' By pairing this unary signal with multi-turn RL, the model learns to self-correct without needing a detailed error report, simply by being told its last attempt failed.
Implement Structured Reflection and Trainable Correction
The Tool-Reflection-Bench framework transforms the 'error-to-correction' process into a trainable skill. It teaches the model to (1) diagnose the error based on concrete evidence and (2) propose a new, valid tool call. This optimizes the entire 'reflect → call → complete' policy.

Set Practical Guardrails for Production
While RL offers a long-term solution, practical engineering guardrails are essential today. Implement simple limits like max_rounds (a hard cap on attempts), no-progress-k (stop after k rounds with no improvement), state-hash deduplication (exit if returning to a previous state), and a cost-budget. Frameworks like AutoGen and the Agents SDK provide programmable termination hooks for this purpose.
The Future of AI Agent Technology: End-to-End Learning
The path forward for AI agent technology requires a paradigm shift from assembling modular components to training holistic, end-to-end systems. The most promising research integrates reinforcement learning, allowing an agent to function as a single policy network that learns directly from environmental feedback. In this model, capabilities like planning, tool use, and reflection emerge naturally.
The fusion of large language models with reinforcement learning is what makes AI agents finally practical and scalable. While challenges of latency, planning, and reflection remain, success will demand robust engineering and continuous human-in-the-loop optimization. By training agents on simulated, real-world problems, we are on the cusp of creating truly autonomous AI systems.
Key Takeaways
• AI agents currently face significant latency issues during the planning phase.
• Planning processes can become brittle, limiting the effectiveness of AI agents.
• Advanced engineering and reinforcement learning are essential for building robust AI agents.