Retrieval-Augmented Generation (RAG) has significantly enhanced AI systems by enabling them to access external knowledge. However, as applications grow in complexity, the limitations of traditional, linear RAG pipelines are becoming apparent. The next evolution in this domain is Agentic RAG, which transforms the process from a rigid workflow into a dynamic, intelligent system capable of adapting its strategy based on the user's query.
This guide explores the complete Agentic RAG implementation, a sophisticated approach that integrates agent-like decision-making into the retrieval and generation process. We will construct a complete Agentic RAG system using LangGraph and the Qwen model, demonstrating how to implement dynamic query analysis and robust self-correction mechanisms. First, let's define the core principles of this advanced architecture.
What is Agentic RAG? The Next Evolution
Agentic RAG is the next generation of retrieval-augmented systems, built on two key upgrades: dynamic query analysis and a self-correction mechanism. It represents a major advance based on a simple but powerful idea: not all questions are created equal. As research shows, the complexity of real-world queries varies dramatically.
🔧 Build Better RAG Systems: Before implementing complex agentic architectures, ensure your document chunking strategy is optimized. Use our RAG Chunk Lab to experiment with different chunking approaches and find the optimal configuration for your use case.
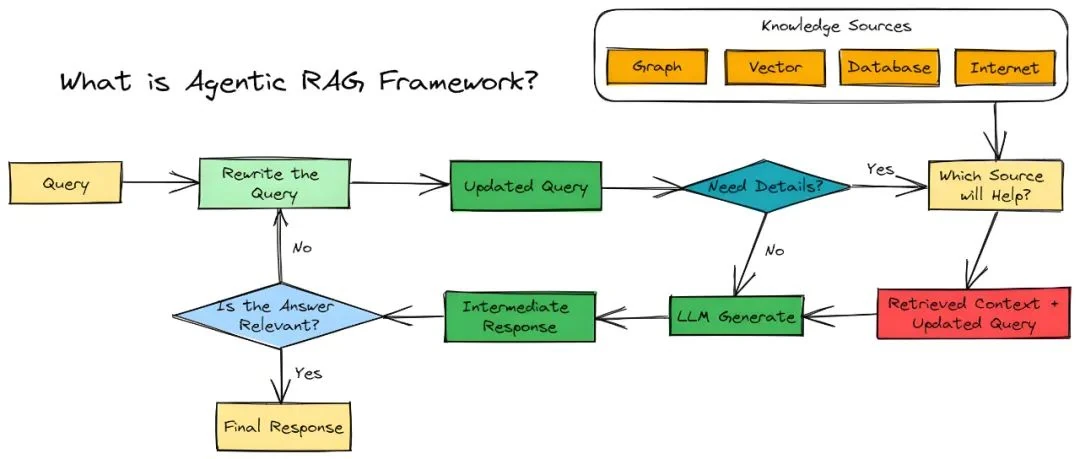
An Agentic RAG system does not treat every query identically. Instead, it follows a more intelligent, multi-step process:
-
Intelligent Query Analysis: First, it intelligently dissects the incoming query using a trained complexity classifier. This is not simple keyword matching but a deep semantic assessment to ascertain the query's true intent.
-
Adaptive Strategy Selection: Based on this analysis, it dynamically chooses the optimal tool for the task:
- Simple Queries: For straightforward questions with clear answers in the local knowledge base, it performs a direct vector search for maximum efficiency.
- Complex or Timely Queries: For questions requiring up-to-the-minute information or those too broad for the local database, it routes the query to a web search engine.
- Ambiguous Queries: If a query is unclear, it can request clarification instead of proceeding with a guess.
-
Multi-layered Self-Correction: The system continuously self-corrects throughout the generation process to ensure the final answer is accurate and reliable:
- Relevance Grading: After retrieving documents, it grades them for relevance. If the retrieved information is a poor match, it can trigger a new search or adjust its strategy.
- Hallucination Detection: Before finalizing an answer, it cross-references the generated text against the source documents to ensure it is factually grounded and free of hallucinations.
- Answer Quality Check: Finally, it evaluates whether the answer directly addresses the user's original question, ensuring it is not just accurate but also useful.
Ready to build one? This guide will walk you through implementing an adaptive Agentic RAG system that analyzes user queries, intelligently routes them, and prioritizes robust, scalable engineering. This implementation demonstrates:
- Fine-grained Query Analysis: The ability to understand the nuances of a user's question.
- Intelligent Routing: Dynamically choosing between local knowledge retrieval and real-time web search.
- Self-Correction and Validation: Using multiple checks to ensure high-quality, trustworthy answers.
This implementation focuses on readability, maintainability, and the overall developer experience. Our technology stack includes:
- Framework: LangGraph
- LLM: Qwen
💵 Cost Optimization Tip: When building Agentic RAG systems with multiple LLM calls, costs can add up quickly. Use our Token Calculator to estimate and optimize your API costs across different models like GPT-4, Claude, and Qwen.
- Embedding Model: BAAI/bge-large-en-v1.5
- Vector Database: ChromaDB
- Web Search: Tavily
Let's begin. We will build our Agentic RAG system component by component, explaining the role and implementation of each to provide a clear understanding of the entire workflow.
Step 1: Setting Up the State Management in LangGraph
In any Agentic RAG system built with LangGraph, state management is the central nervous system. It tracks the current context, completed actions, and next steps, allowing the system to make informed, context-aware decisions.
First, let's import the necessary libraries.
# [Code block for library imports]
Next, we'll use TypedDict to define our graph's state. This provides type safety for robust code and the flexibility needed for a dynamic workflow.
# [Code block for TypedDict state definition]
Finally, we'll define constants for the names of the nodes in our graph.
# [Code block for node name constants]
Defining these as constants is a best practice that prevents typographical errors and simplifies refactoring by centralizing all node references.
Step 2: Initializing the Qwen LLM and Embedding Models
With our state defined, it's time to load the core models of our system: the Large Language Model (LLM) and the embedding model. These components will power our system's semantic understanding and text generation capabilities.
# [Code block for initializing LLM and embedding models]
Step 3: Implementing Dynamic Query Routing
The query router acts as the system's intelligent switchboard. It is the first decision point in our workflow, responsible for analyzing the user's query and directing it down the most efficient path.
At this stage, the system classifies the query and chooses one of three routes:
- Vector Store: For queries that can likely be answered by the internal knowledge base.
- Web Search: For queries that require real-time data, news, or information not present locally.
- LLM Fallback: For conversational queries or tasks that do not require external knowledge retrieval.
# [Code block for building the query router]
This intelligent routing strategy allows our Agentic RAG system to strike a balance between knowledge depth, real-time accuracy, and conversational flexibility. It can deliver fast, high-quality answers from its local knowledge base, supplement them with the latest information from the web, and generate coherent responses when no retrieval is needed.
Step 4: Building the Vector Retrieval Node with ChromaDB
This node is the heart of our system's long-term memory. It is responsible for fetching the most relevant documents from our local knowledge base to provide context for the final answer.
The process involves several key steps:
- Vectorization: The user's query is converted into a vector embedding.
- Similarity Search: The system searches the vector database (ChromaDB) for documents with embeddings that are most similar to the query's embedding.
- Contextual Snippets: The most relevant document snippets are retrieved and passed to the next stage.
# [Code block for the vector retrieval node]
This process provides our RAG system with a powerful and reliable semantic search capability. When paired with our grading mechanisms, it can effectively filter out noise and retain only the most relevant documents, dramatically improving the accuracy of the final generated answer.
Step 5: Integrating a Real-Time Web Search Node
When the local knowledge base lacks an answer, the web search node is engaged. This component gives our system the ability to access the vast, real-time information available on the internet.
# [Code block for the web search node]
This hybrid "local-first, web-second" strategy ensures our RAG system is both deep and broad. It can leverage the curated accuracy of its internal knowledge while retaining the flexibility to answer questions about current events or niche topics, making it far more versatile than a standard RAG setup.
Step 6: Implementing a Self-Correction Document Grader
The document retrieval grader is a critical quality control checkpoint. This step is crucial because vector similarity is not synonymous with true semantic relevance. A document might match keywords but be contextually incorrect.
Here's how it functions:
- Evaluation: The grader uses the LLM to assess whether each retrieved document is truly relevant to the user's query.
- Decision: Based on the relevance score, it decides whether to proceed with the documents, discard them and end the process, or trigger a new search (e.g., a web search if the local search failed).
# [Code block for the retrieval grader node]
This grading mechanism ensures our retrieval module strikes an optimal balance between speed and accuracy. It allows the system to respond quickly when it finds a good match and adaptively expand its search when initial results are insufficient, ensuring the user receives a complete and accurate answer.
Step 7: Generating Answers with the Qwen LLM
If the retrieval nodes are the researchers, the generation node is the author. It takes the user's original query and the rich context from the retrieved documents and synthesizes them into a final, human-readable answer.
Key features of this node include:
- Contextual Synthesis: It skillfully weaves together information from multiple sources.
- Prompt Engineering: It uses a carefully crafted prompt to guide the LLM in generating a high-quality response.
- Structured Output: The final answer is formatted and prepared for the last round of quality checks.
# [Code block for the generation node]
This node closes the loop, transforming retrieved facts into a coherent answer and setting the stage for our final validation steps: hallucination and quality grading.
Step 8: Creating a Hallucination Detection Grader
The hallucination grader is our system's fact-checker. Its purpose is to identify and flag "hallucinations"—content that sounds convincing but is factually incorrect or unsupported by the source documents.
The process is straightforward but vital:
- Cross-Reference: The grader compares the generated answer against the retrieved documents.
- Factual Verification: It checks if every claim in the answer is supported by the source material.
- Binary Decision: It outputs a simple "supported" or "not supported" verdict.
# [Code block for the hallucination grader]
This final check elevates the system from a clever text generator to a trustworthy information source. It is a non-negotiable component for any production-grade RAG application.
Step 9: Ensuring Relevance with an Answer Quality Grader
While the hallucination grader checks for factual accuracy, the answer quality grader assesses relevance. It asks a simple question: "Does this answer actually address the user's original question?"
This node evaluates the generated answer against the initial query to determine if it is helpful and on-topic. If the answer is factually correct but does not satisfy the user's intent, this grader will flag it.
# [Code block for the answer quality grader]
Together, these two grading steps ensure the final output is both accurate and genuinely helpful, dramatically improving the user experience and the system's overall reliability.
Step 10: Assembling the Agentic RAG Workflow in LangGraph
Now we will assemble the complete system. We'll use LangGraph to construct the workflow, connecting all the nodes we've built into a cohesive, intelligent agent.
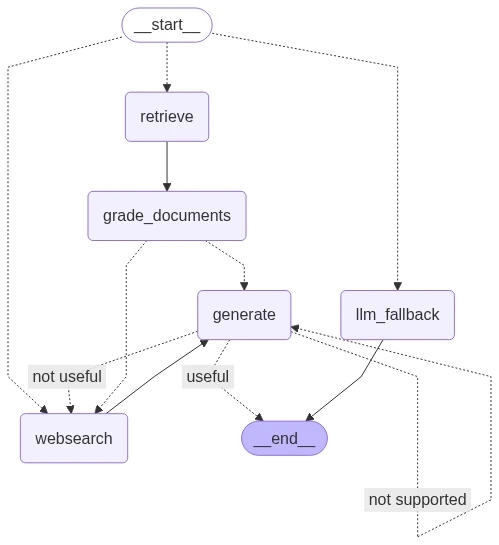
This graph defines the logic and flow of our system:
- Define Nodes: We add each of our components (retriever, grader, generator, etc.) as a node in the graph.
- Set the Entry Point: We specify the
route_querynode as the starting point for any new query. - Define Conditional Edges: This is where the "agentic" behavior comes alive. We create rules that direct the flow based on the output of each node. For example:
- If the
route_querynode outputs "web_search," the graph proceeds to theweb_search_node. - If the
grade_documentsnode finds the documents irrelevant, it can re-route back to the web search or end the process. - If the
grade_hallucinationsnode detects an issue, the system can attempt to re-generate the answer.
- If the
# [Code block for building and compiling the LangGraph]
This graph is the core of our Agentic RAG system. It transforms a linear pipeline into a dynamic, self-correcting loop, ensuring every query is handled with the most appropriate and effective strategy.
Step 11: Creating the Application Entry Point
This final component is the user-facing entry point—a simple command-line interface (CLI) that allows us to interact with our newly built agent.
Its function includes:
- Argument Parsing: It takes a user's query as a command-line argument.
- Graph Invocation: It passes the query into our compiled LangGraph app.
- Streaming Output: It streams the final, validated answer back to the user in real-time.
# [Code block for the main application entry point]
With this entry point, our system is complete and ready for testing. We can now run it from the command line and observe its intelligent, adaptive question-answering capabilities.
How to Run Your Agentic RAG System
With all components in place, let's test our Agentic RAG system. You can start the application by running:
python main.py "What is the weather like in Tianjin tomorrow?"
Here, the system executed its full adaptive reasoning process.
First, it intelligently analyzed the query. Recognizing that "weather tomorrow" requires real-time information, it bypassed the local knowledge base and routed the query directly to the web search node.
Next, the system synthesized this information, generating a natural language answer based on the fresh meteorological data. This answer then passed through our quality gates—the hallucination and relevance graders—to ensure it was both factually accurate and directly addressed the user's question.
Finally, the system delivered a verified, reliable answer:
Tomorrow in Tianjin, there will be showers in the morning, becoming partly cloudy in the afternoon. South wind 3-4 becoming a light breeze, with temperatures between 23 and 27 degrees Celsius.
This entire process showcases the power of Agentic RAG. It flexibly chose the right information source, rapidly integrated data, and guaranteed the answer's trustworthiness through multiple layers of validation.
Cost Optimization for Agentic RAG
When implementing Agentic RAG systems, token costs can quickly accumulate due to multiple LLM calls involved in planning, retrieval, and generation. Use our GPT-5 token calculator or Grok 4 token calculator to estimate your API costs accurately. For detailed comparisons between models, check our GPT-5 vs Grok 4 pricing guide.
Choosing the Right RAG Framework
Before diving into implementation, it's essential to choose the right RAG framework for your needs. Our comprehensive RAG frameworks comparison analyzes the top 5 options (LangChain, LlamaIndex, Haystack, RAGFlow, Verba) with benchmarks, code examples, and decision matrices. This will help you select the framework that best matches your team's skills and project requirements.
Conclusion: The Future of Agentic RAG
We have journeyed from the core concepts of Agentic RAG to a fully functional implementation, building a stateful workflow with LangGraph that combines the Qwen model, local vector search, and real-time web access. The result is an intelligent system that can dynamically route queries, make context-aware decisions, and self-correct to deliver answers that are accurate, reliable, and timely.
The road ahead for Agentic RAG points toward two significant research frontiers: multimodal fusion and autonomous learning.
- Multimodal RAG: The next generation of systems will need to comprehend and retrieve information from diverse data types, including images, charts, and videos. The challenge lies in creating unified retrieval models that can reason across this multimodal landscape to solve increasingly complex problems.
- Autonomous Learning: Future agents will move beyond pre-programmed logic. By integrating mechanisms like Reinforcement Learning from Human Feedback (RLHF), these systems will learn and improve from every interaction, continuously refining their decision-making policies and answer quality.
Furthermore, by leveraging large-scale knowledge graphs and distributed retrieval architectures, Agentic RAG is poised to achieve unprecedented efficiency and scale. This is not merely an incremental improvement; it represents a critical leap toward building truly intelligent, adaptable, and reliable AI applications.
Key Takeaways
• Agentic RAG enhances traditional RAG by introducing adaptive, intelligent decision-making.
• Utilize LangGraph and the Qwen model to build an effective Agentic RAG system.
• Transition from linear workflows to dynamic systems for improved AI application performance.