Complex Reinforcement Learning (RL) workloads, from RLHF to model distillation, depend on a sophisticated orchestration of computation, data communication, and process control across multiple models. A typical Proximal Policy Optimization (PPO) setup, for instance, can involve up to five distinct modules—Actor, Rollout, Ref, Critic, and Reward—each performing specialized training, evaluation, or generation tasks.
Managing this complexity using a standard single-script, multi-process model launched with tools like deepspeed or torchrun presents significant limitations. Flexible task scheduling and dynamic resource allocation become intractable challenges.
This is where the Ray framework provides a powerful alternative for distributed RL.
Ray's remote asynchronous calls and Actor abstraction enable each module to operate as an independent execution unit. This decoupled architecture is ideal for scenarios demanding frequent collaboration between multiple models in a distributed RL training environment.
In this article, we will conduct a deep engineering analysis of two prominent RLHF frameworks, veRL[1] and OpenRLHF[2]. We will examine their features and architectural advantages, focusing on how they leverage a multi-Actor setup in the Ray framework to execute mixed training and inference tasks.
Our analysis will deconstruct these Reinforcement Learning frameworks from three key perspectives:
- Module Responsibilities: What role does each model play in PPO training, and what backends do they use?
- Ray Resource Allocation: How does Ray manage resources and implement GPU colocation?
- Execution Flow: How do data and control signals move through the distributed system?
This article contains numerous links to the source code, which we strongly encourage you to explore. Theoretical understanding is valuable, but diving into the code is the most effective way to build real-world expertise in distributed RL systems.
A Quick Primer on the Ray Framework
For those new to Ray, here is a summary of the core concepts required to understand this article.
How to Launch a Ray Cluster
While Ray offers APIs for multiple languages, the Python API is the most prevalent. Typically, a user starts a Python script and calls ray.init(), which automatically creates a local Ray cluster. The process running this script is known as the driver. Alternatively, a multi-node cluster can be started from the command line with ray start, allowing a script to connect to it.
Understanding Ray's Execution Logic
Under the hood, a Ray cluster is a pool of persistent worker processes. When a Python function or class is decorated with @ray.remote, it is transformed into a schedulable Task or Actor. It can then be invoked asynchronously using the .remote() method, which dispatches the Task[3] or Actor[4] to a worker process.
For the driver, these calls are non-blocking. To retrieve the results, one uses ray.get() to fetch the return value of the asynchronous operation.
Arguments and return values are serialized[5] into Ray Objects[6] and placed in the cluster's distributed object store. From Ray's perspective, the memory across all nodes functions as a unified object store. Developers pass object references, and Ray automatically fetches the data when ray.get() is called.
Here is a simple example demonstrating how Ray Actors can be composed:
import ray
ray.init()
@ray.remote
class ChildActor:
def do_work(self):
return "Work done by child"
@ray.remote
class ParentActor:
def create_child(self):
# Create a child actor remotely
self.child_actor = ChildActor.remote()
def get_work(self):
# Remotely call the child and wait for the result
return ray.get(self.child_actor.do_work.remote())
# Create the parent actor
parent_actor = ParentActor.remote()
# Remotely call create_child and wait for it to complete
ray.get(parent_actor.create_child.remote())
# Remotely call get_work and print the final result
print(ray.get(parent_actor.get_work.remote())) # Output: Work done by child
This demonstrates that one Ray Actor can create and call another. Note that standard Python inheritance cannot be used to inherit methods from another Actor class; the @ray.remote decorator should only be applied to the final class.
Resource Scheduling with Placement Groups
When creating a Ray Actor, you can specify the resources[7] it requires (e.g., num_cpus, num_gpus). Ray's scheduler will then find a node with available resources to place the Actor. For more advanced scheduling, you can pre-define a placement group[8], which is a collection of resource bundles[9]. Actors can then be assigned to specific bundles, enabling both exclusive and shared resource patterns. This is the strategy adopted by both veRL and OpenRLHF for managing distributed RL workloads.
For instance, if an RLHF module uses a data parallelism (DP) degree of 4, one could create a placement group with 4 GPUs, define 4 bundles (each with 1 GPU), and then assign each DP worker to a unique bundle.
OpenRLHF Architecture: A Deep Dive into Distributed RL on Ray
From an engineering standpoint, OpenRLHF's code is clean and relatively straightforward. We will be examining the v0.5.9.post1 release, focusing on its Ray-based PPO training implementation.
First, let's visualize the overall OpenRLHF architecture:
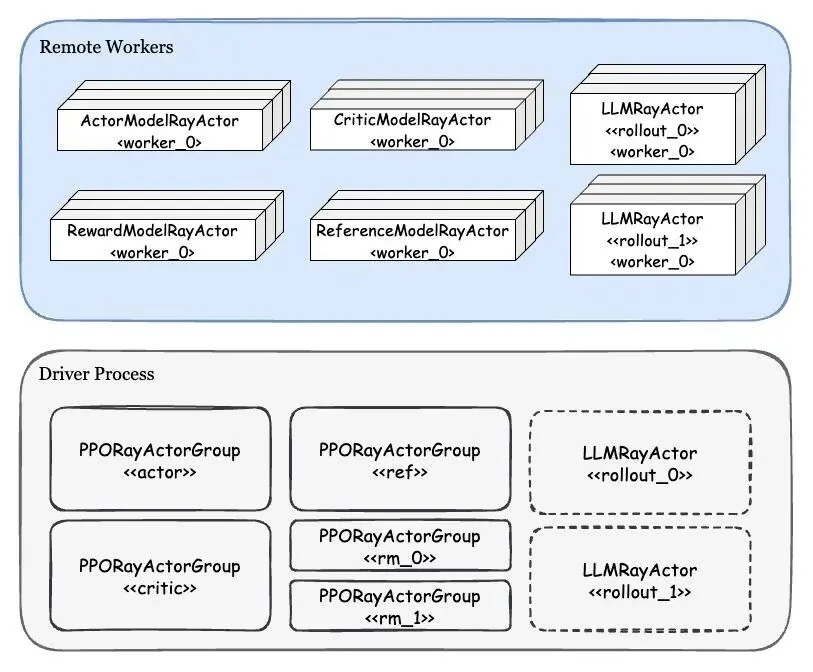
The diagram separates components on the driver process from those on remote Ray workers. The driver manages PPORayActorGroup[10] instances for each module (Actor, Critic, etc.). Each Group represents a complete logical model, while the remote workers are its data-parallel (DP) shards. For the Rollout module, the driver holds handles to one or more LLMRayActors, each representing a vLLM engine.
Workers[12] within a group are created sequentially. The rank 0 worker (master) establishes the communication backend address[13], and subsequent workers connect to it. Communication is isolated between different groups, making each group's training process equivalent to a standard multi-process job.
Ray's abstractions elegantly hide low-level details, allowing each module to operate like an independent distributed task and simplifying the logic for complex, multi-model systems.
Training and Inference Backends: DeepSpeed and vLLM
Let's clarify the roles of each module in the PPO algorithm:
- Actor: A training module that updates its weights.
- Critic: A training and evaluation module that also updates weights.
- Rollout: A batch inference module for generating samples, synchronized with the Actor.
- RM & Ref: Evaluation-only modules performing forward passes.
For training, any engine like PyTorch DDP, Megatron, or DeepSpeed works. For inference, vLLM or SGLang are popular. OpenRLHF uses DeepSpeed for its training modules and vLLM for inference, which supports both data and tensor parallelism.
Ray Resource Scheduling and GPU Colocation
GPU Colocation is the practice of having multiple Ray Actors share the same physical GPU. In OpenRLHF, this means placing shards from different modules (e.g., an Actor shard and a Critic shard) on the same GPU. They take turns using the hardware, often employing offloading strategies.
OpenRLHF supports three colocation modes: colocate_actor_ref, colocate_critic_reward, and colocate_all_models. A placement group is created, and workers for the colocated modules are assigned to its resource bundles. For example, to colocate five workers on one GPU, you could specify num_gpus_per_actor=0.2.
Modules that are not colocated get their own placement groups with exclusive GPU access.
The colocation of the Actor (DeepSpeed) and Rollout (vLLM) modules is particularly interesting. Since they must keep weights synchronized but cannot use NCCL on the same GPU, OpenRLHF uses CUDA IPC (Inter-Process Communication)[17]. After an all_gather within the Actor workers, the Actor's rank 0 worker broadcasts the complete weights to all Rollout instances.
Data and Control Flow in a Distributed Model
OpenRLHF lacks a central controller, meaning the overall execution logic is scattered. The process kicks off in the launch script[18] and passes control to the Actor group via async_fit_actor_model[19]. This triggers the fit method on all Actor workers, which is effectively PPOTrainer.fit.
From here, the control logic lives inside each Actor worker's trainer. Each Actor worker orchestrates data flow for its slice of the computation, communicating with a corresponding group of Ref, Critic, and RM workers[20] using a round-robin policy[21].
The core training loop is highly dispersed. A simplified representation is:
# In `PPOTrainer.fit`
for episode in range(num_episodes):
# Generate experience samples
sample_and_generate_rollout()
make_exps()
put_in_replay_buffer()
# In `ActorPPOTrainer.ppo_train`
for epoch in range(num_epochs):
for exps in replay_buffer:
train(exps) # This calls train_actor() and train_critic()
clear_replay_buffer()
Crucially, all of this control logic is executed by the Actor workers. This design places a heavy computational and communication burden on the Actor workers, suggesting they could become a performance bottleneck in this distributed RL architecture.
veRL Architecture: A Centralized 'Single Controller' on Ray
The open-source code for veRL[22] features layers of abstractions, extracted from a mature internal codebase. Its standout feature is its thorough decoupling of modules, which makes extension easy. The framework also uses clever Python metaprogramming to allow a single Ray Actor to switch between multiple roles.
We'll examine version v0.2.0.post2, focusing on its Ray + FSDP implementation.
First, let's look at the veRL framework's composition:
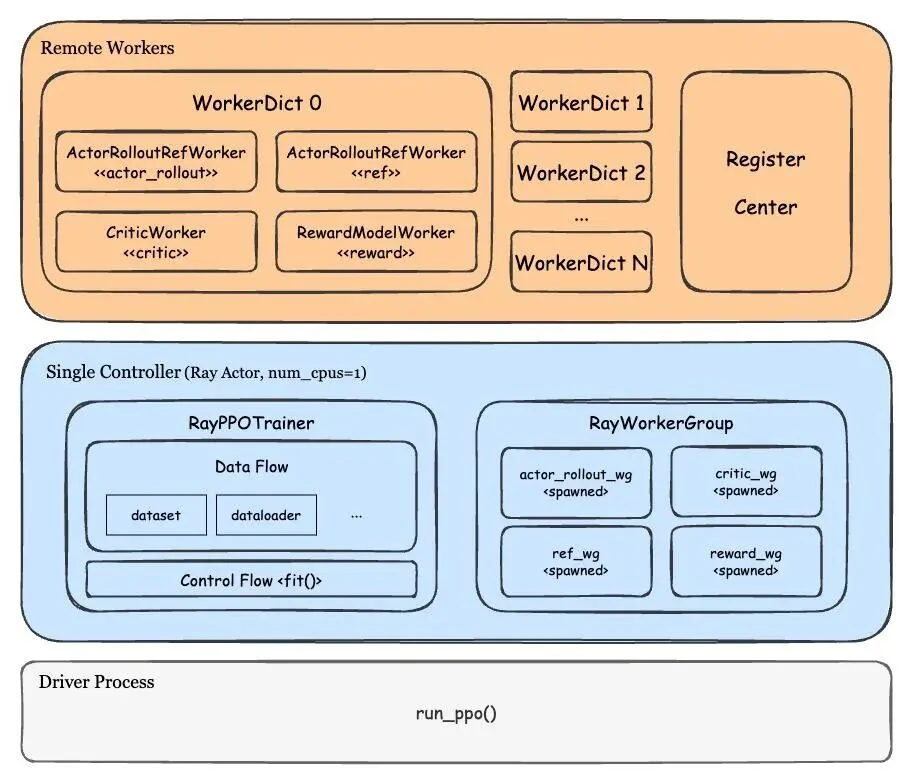
Unlike OpenRLHF, veRL centralizes its main logic in a single Ray Actor[23] called a "single controller." This CPU-only controller acts as the system's brain, managing data flow, control flow, and resource initialization. It remotely creates and calls WorkerDicts, orchestrating all data transmission.
The most ingenious component is the WorkerDict. It's a base class for a Worker (a single model shard) designed to bind the public methods of all modules (Actor, Critic, etc.). This allows a WorkerDict instance to dynamically switch roles, becoming a universal, multi-personality Worker.
Layered on top is the RayWorkerGroup[24], which acquires resources from a placement group, configures a WorkerDict for a specific role, creates the WorkerDict instances, and dispatches tasks to them[25].
Training Backends and the Hybrid Engine Concept
In veRL, the training backend can be FSDP/HSDP or Megatron, while the inference module is vLLM. veRL also supports GPU colocation, but its primary strategy is to colocate all modules.
veRL heavily emphasizes its Hybrid Engine capability. Different modules share the same underlying WorkerDict data structure and resource group, allowing the WorkerDict to flexibly switch between different roles and engines. This is similar to the architecture of DeepSpeed-Chat[26].
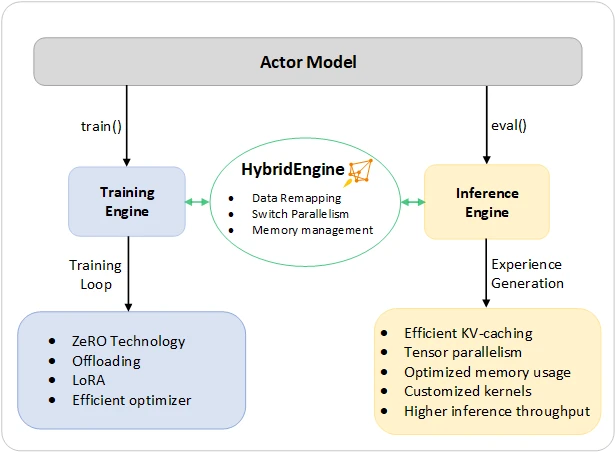
A critical design choice in veRL is that the Actor and Rollout modules share the same model weights in memory[27]. This eliminates the need for explicit weight synchronization via CUDA IPC, unlike OpenRLHF. Since the Actor and Rollout components live in the same process, direct memory access replaces network communication. This is more memory-efficient but required extensive patching of vLLM.
Dynamic Workers and Resource Scheduling in Ray
The magic behind the dynamic WorkerDict starts with the create_colocated_worker_cls function. It dynamically creates a new class, WorkerDict, that instantiates all module classes (e.g., CriticWorker) and stores them internally. Then, it binds the public methods of these module instances directly to the WorkerDict instance, adding a prefix like critic_.
A debugging session reveals the result:
(Pdb) p dir(self.workers[0])
['__init__', ...
'actor_rollout_compute_log_prob', 'actor_rollout_generate_sequences', ...
'critic_compute_values', 'critic_init_model', 'critic_update_critic', ... ]
The WorkerDict instance now has methods like critic_init_model that proxy calls to the internal CriticWorker instance[31].
This WorkerDict class is then passed to a RayWorkerGroup, which binds these prefixed methods to itself[32], adding powerful dispatch logic. When a method is called on the RayWorkerGroup (e.g., critic_wg.compute_values()), it knows how to distribute data, execute the remote call on its WorkerDict Actors, and aggregate the results.
Centralized Data and Control Flow
Thanks to its single controller design, veRL's control logic is neatly centralized in RayPPOTrainer. The init_workers[37] method sets up the WorkerDicts, and the fit method contains the main PPO algorithm. This centralized approach improves code readability and extensibility compared to a distributed control model.
OpenRLHF vs. veRL: A Head-to-Head Architectural Comparison
To conclude, let's summarize the architectural trade-offs between these two Reinforcement Learning frameworks.
Module Design and Backend
Both frameworks deconstruct PPO into distinct modules. The key difference is veRL's flexible, multi-backend architecture, which allows for arbitrary combinations like FSDP + vLLM. This modularity is a powerful paradigm for advanced RLHF frameworks, though unifying APIs across backends is a significant challenge.
Ray Scheduling and Resource Management
The frameworks diverge significantly here. OpenRLHF launches a dedicated group of workers for each model and colocates them by rank. In contrast, veRL creates a single, universal WorkerDict that houses all models, naturally sharing resources.
OpenRLHF's approach is simpler, while veRL's 'symbiotic' WorkerDict is more efficient but required substantial engineering. Both GPU Colocation and a Hybrid Engine are essential features for maximizing hardware ROI in large-scale RL training.
Data Flow and Control Flow
The location of the control flow has a major impact on performance. OpenRLHF concentrates its control logic on the Actor workers, making them a potential system-wide bottleneck.
veRL's centralized 'single controller' appears to be a more scalable design. It acts as a hub for control and data flow, leading to cleaner code from a readability and extensibility perspective.
One final observation is that both frameworks rely heavily on Ray's Object Store for data transfer. For large tensors, the overhead of serialization and memory copies can be a bottleneck. There is potential for optimization by replacing some transfers with direct NCCL or IPC communication, paving the way for even more efficient and scalable distributed AI systems.
Key Takeaways
• OpenRLHF and veRL enhance scalability for complex RLHF workloads using the Ray framework. • Proximal Policy Optimization (PPO) setups require managing multiple specialized modules efficiently. • Standard multi-process models face limitations; consider using advanced orchestration tools for better performance.
Further Reading
If you found this distributed RLHF architecture analysis helpful, explore these related resources:
Core RLHF Concepts:
- Reinforcement Learning for LLMs: RLHF & DPO Explained (2025) - Master the fundamentals of RLHF, DPO, and PPO algorithms that power both OpenRLHF and veRL frameworks.
Large-Scale Training:
- Train 671B DeepSeek V3: RLHF Guide (10x Faster with GRPO) - Learn how to train massive LLMs with reinforcement learning at scale, including Megatron setup and 1000+ GPU coordination strategies.
Pre-Training Foundation:
- Supervised Fine-Tuning: A Guide to LLM Reasoning - Understand the SFT pipeline that precedes RLHF, covering the complete DeepSeek R1 process from fine-tuning to knowledge distillation.
Related Topics:
- Knowledge Hub: Reinforcement Learning - Explore all RL-related articles, including RLHF techniques, DPO methods, and distributed training strategies for LLMs.