The release of Kimi K2, a 1.04 trillion-parameter open-source Mixture-of-Experts (MoE) large language model, marks a significant milestone in the AI landscape. While its scale is notable, the true innovation lies in the engineering detailed in its accompanying technical report. The Kimi team has provided the AI community with a comprehensive look at the model's architecture and training methodology, offering a potential blueprint for future large-scale AI development and agentic intelligence.
Kimi K2's development showcases several advances in AI engineering. These include the MuonClip optimizer, which enabled a stable 15.5 trillion token training run without loss spikes; a large-scale synthetic data pipeline for training AI agents; and a sophisticated reinforcement learning framework that combines verifiable rewards with self-critique. This review will analyze the Kimi K2 technical report to unpack the innovations that position it as a noteworthy model in the field.
How powerful is this trillion-parameter open-source model? How might it reshape the AI landscape? And what does the future of the 'Agentic Intelligence' it champions look like? Let's examine the technical details.
Read the full technical report: https://github.com/MoonshotAI/Kimi-K2/blob/main/tech_report.pdf
What is Kimi K2? A New Architecture for Agentic AI
Artificial intelligence is shifting from static imitation learning toward Agentic Intelligence, a key concept for the next generation of AI. Agentic Intelligence is the ability for an AI to autonomously perceive, plan, reason, and interact with complex, dynamic environments. We are at a turning point where AI is evolving from a system that mimics human data into an active learner—an AI agent that can acquire new skills through interaction and, ultimately, may surpass human capabilities on the path to Artificial General Intelligence (AGI).
However, the road to agentic intelligence presents significant hurdles. During pre-training, high-quality data is becoming a scarce resource, making it critical to maximize the learning efficiency of every token. In the post-training phase, teaching the model complex skills like multi-step reasoning, long-term planning, and tool use—abilities rarely found in natural data—is even more challenging.
This is the challenge Kimi K2 was built to solve. It is a Mixture-of-Experts (MoE) large language model with 1.04 trillion total parameters and 32 billion activated parameters per token. Its core design goal is to tackle the central challenges of building agentic AI and redefine what is possible.
Kimi K2's Core Innovations: MuonClip, Data Synthesis, and RL
Kimi K2's breakthroughs span the entire model development lifecycle, from pre-training to post-training:
- Innovative MuonClip Optimizer: The Kimi team developed a novel optimizer called MuonClip. It fuses the token-efficient Muon algorithm with a stability-enhancing technique called QK-Clip, solving the instability issues that can plague ultra-large-scale training. As a result, Kimi K2 achieved a stable training curve over 15.5 trillion tokens with zero loss spikes—a remarkable feat of engineering.
- Large-Scale Agent Data Synthesis Pipeline: To teach the model how to use tools, the team built a powerful data synthesis system. This system simulates real-world environments to systematically generate massive, diverse, and high-quality data showing how to use tools to complete tasks. This pipeline is a key component behind Kimi K2's agent skills.
- Universal Reinforcement Learning Framework: Kimi K2's post-training uses a joint reinforcement learning (RL) framework. It learns from tasks with definitive right-or-wrong answers (like code compilation and math) while also using a self-critique mechanism to improve on open-ended, subjective tasks (like creative writing). This allows for a holistic alignment and refinement of the model's capabilities.
Kimi K2 Performance: Benchmarks vs. GPT-4o & Claude 3.5
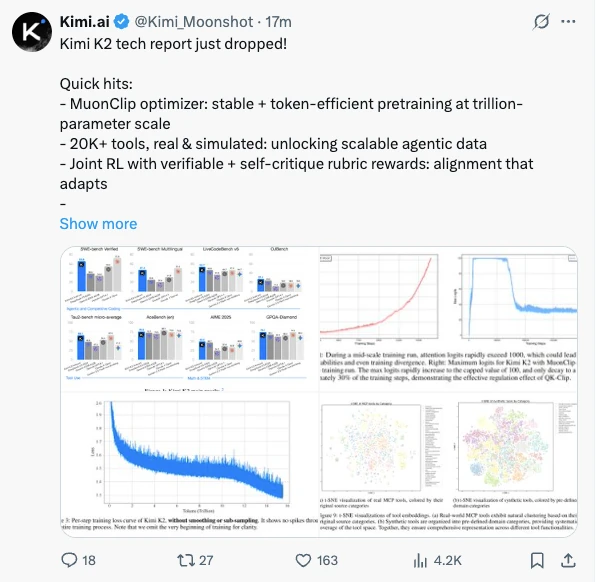
While qualitative descriptions are useful, benchmarks provide a clear performance narrative. A single chart from the technical report illustrates Kimi K2's lead across numerous evaluations.
Across key benchmarks for agent, coding, and reasoning capabilities, Kimi K2 not only surpasses existing open-source models but, in many zero-shot evaluations, its performance approaches or exceeds top-tier closed-source models like Claude 3.5 Sonnet.
Specifically, Kimi K2 has set new records for open-source models in multiple domains:
- Agents & Tool Use: On Tau2-Bench and ACEBench, which test complex, multi-turn tool interactions, it scored 66.1 and 76.5, respectively, outperforming all competitors.
- Software Engineering & Code: On SWE-Bench Verified, a challenging coding benchmark, Kimi K2 achieved 65.8. On the multilingual version, SWE-Bench Multilingual, it reached 47.3, closing the gap with the top-performing closed-source model, Claude 4 Opus.
- Math & Reasoning: In challenging reasoning tasks like AIME 2024 (49.5) and GPQA-Diamond (75.1), Kimi K2 demonstrated top-tier capabilities.
- User Preference: On the LMSYS Arena, a blind chatbot benchmark driven by global user votes, Kimi K2 ranked first among all open-source models and fifth overall as of July 17, 2024, with over 3,000 user votes.
To accelerate progress in agentic AI, the Kimi team has open-sourced the full weights for both the Kimi K2 base model and the instruction-tuned model, a significant contribution to AI developers and researchers worldwide.
Kimi K2 Pre-training: Achieving Trillion-Parameter Stability
A large model's pre-training is its foundation. The story of Kimi K2's pre-training is one of innovation, tackling two of the biggest hurdles in large-scale training: data efficiency and training stability.
MuonClip Optimizer: The Key to Stable LLM Training
As model and data sizes increase, maximizing the value of every token has become paramount. The Kimi team opted for the Muon optimizer, known for its superior token efficiency compared to the traditional AdamW optimizer.
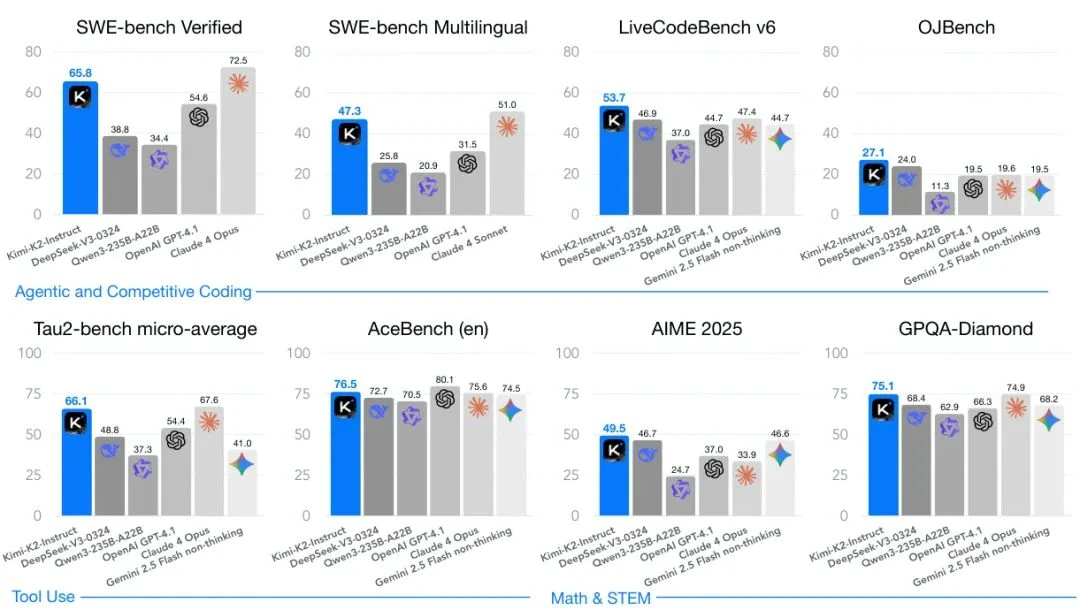
However, at Kimi K2's scale, Muon became prone to causing attention logits to explode, leading to loss spikes or training collapse. To address this, the Kimi team developed the QK-Clip technique.
What is QK-Clip? QK-Clip functions as an intelligent regulator. During each training step, it monitors the dot product values (logits) between the Query and Key vectors in the attention mechanism. If a value exceeds a predefined safety threshold (e.g., 100), QK-Clip scales down the weights (Wq, Wk) of the specific attention head causing the issue, pulling the logits back into a safe range.
Its design is notable for its:
- Precision: It intervenes only with the few problematic attention heads, avoiding a broad approach that could disrupt learning.
- Dynamic Activation: It is most active in the early stages of training when logits are unstable and automatically becomes dormant as training stabilizes.
The Kimi team combined the Muon optimizer with QK-Clip and other techniques to create the new and robust MuonClip optimizer.
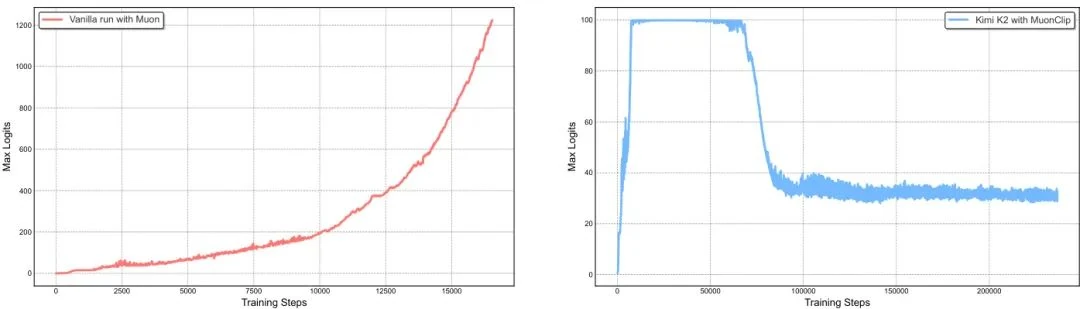
Ultimately, with MuonClip, Kimi K2's entire pre-training process was exceptionally stable. The raw, unsmoothed training loss curve below shows no loss spikes—a rarity in trillion-parameter model training.
Data Rephrasing: A Strategy for High-Quality Data Augmentation
High-quality human data is a finite resource. Simply repeating data (multi-epoch training) can lead to overfitting. The Kimi K2 team employed a more sophisticated approach: data rephrasing.
The core idea is to use a powerful teacher model to rewrite high-quality text from different perspectives while preserving its core meaning. This generates multiple new data points that are semantically consistent but stylistically diverse, reinforcing knowledge without encouraging rote memorization.
- Knowledge Data Rephrasing: For knowledge-dense documents like Wikipedia articles, the team designed a chunked autoregressive rephrasing pipeline. It slices a long text, rephrases each chunk sequentially while maintaining context, and then reassembles them into a new article.
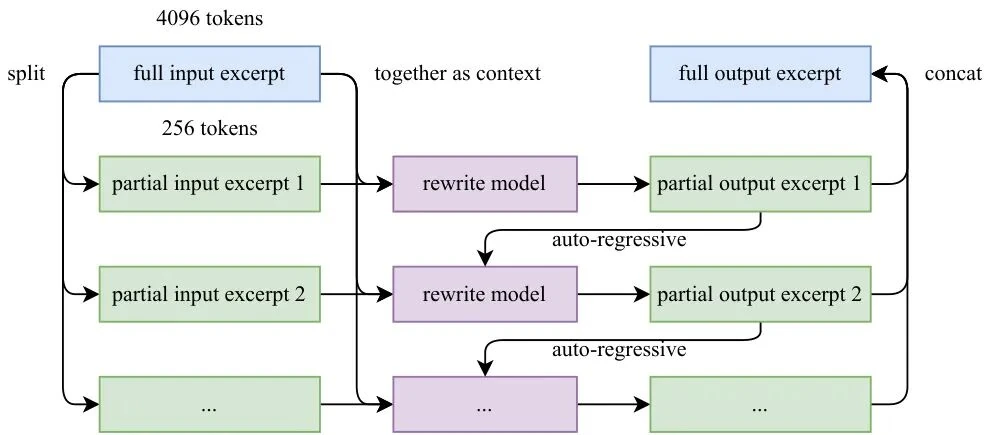
Experiments showed that training once on 10 different rephrased versions of the data produced better results than training 10 times on the original data.
- Math Data Rephrasing: To boost mathematical reasoning, the team rewrote high-quality math documents into a "study note" style and translated valuable math materials from other languages, significantly enriching the diversity of the math training data.
Thanks to this strategy, Kimi K2's 15.5 trillion token pre-training dataset—spanning web text, code, math, and knowledge—ensured that every token was used effectively.
Kimi K2 Architecture: A Sparse Mixture-of-Experts (MoE) Model
Kimi K2's scale is 1.04 trillion total parameters, yet it only activates 32.6 billion parameters during inference. This efficiency is achieved through its Mixture-of-Experts (MoE) architecture.
Through extensive experiments, the Kimi team identified a Sparsity Scaling Law: while keeping the number of activated parameters (and thus computational cost) constant, model performance improves as the total number of experts increases (i.e., as the model becomes sparser).
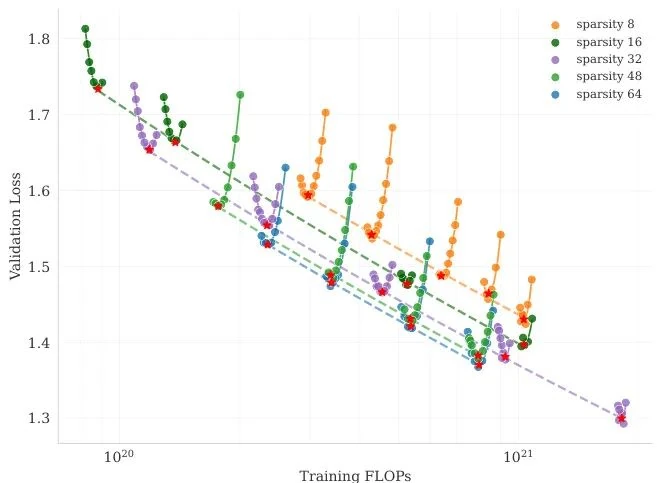
Guided by this finding, Kimi K2 was designed with an ultra-high sparsity of 384 experts, activating 8 of them during each forward pass. This strikes a balance between performance and engineering cost.
Table 2: Kimi K2 vs. DeepSeek-V2 Architecture Comparison
| DeepSeek-V2 | KimiK2 | △ | |
|---|---|---|---|
| #Layers | 61 | 61 | = |
| TotalParameters | 671B | 1.04T | ↑54% |
| ActivatedParameters | 37B | 32.6B | ↓13% |
| Experts (total) | 256 | 384 | ↑ 50% |
| ExpertsActiveper Token | 8 | 8 | = |
| SharedExperts | 1 | 1 | = |
| AttentionHeads | 128 | 64 | ↓50% |
| Number of Dense Layers | 3 | 1 | ↓ 67% |
| Expert Grouping | Yes | No |
Kimi K2 significantly increases total parameters and the number of experts while optimizing inference overhead by reducing attention heads and other components.
Furthermore, to boost inference efficiency in long-context scenarios, Kimi K2 reduced the number of attention heads from DeepSeek-V2's 128 to 64. Experiments confirmed this change had a negligible impact on performance but significantly cut the computational cost of long-context inference—a critical optimization for agentic applications.
Training Infrastructure for a Trillion-Parameter Model
Running on a cluster of NVIDIA H800 GPUs, the Kimi team built a highly flexible and efficient training system.
- Flexible Parallelism Strategy: By combining Pipeline Parallelism (PP), Expert Parallelism (EP), and ZeRO Data Parallelism (DP), Kimi K2 can be trained on any number of nodes that is a multiple of 32, improving R&D agility.
- Extreme Memory Optimization: To fit the massive model into limited GPU memory, the team used a suite of advanced techniques, including selective recomputation, FP8 activation storage, and CPU memory offloading.

This holistic innovation across the model, algorithms, data, and systems forged Kimi K2's powerful and stable base model.
Post-Training Kimi K2 for Advanced Agentic Intelligence
A powerful base model has raw potential. The post-training process refines that potential into real-world problem-solving proficiency. For Kimi K2, this process was focused on building a world-class AI agent.
Large-Scale Data Synthesis for AI Agent Training
A core capability of modern LLM agents is using unfamiliar tools to interact with the world. Generating massive amounts of high-quality training data for this is a challenge, as real-world experimentation is expensive and risky.
The Kimi team's solution was to build a simulated world that can generate high-quality training data at scale.
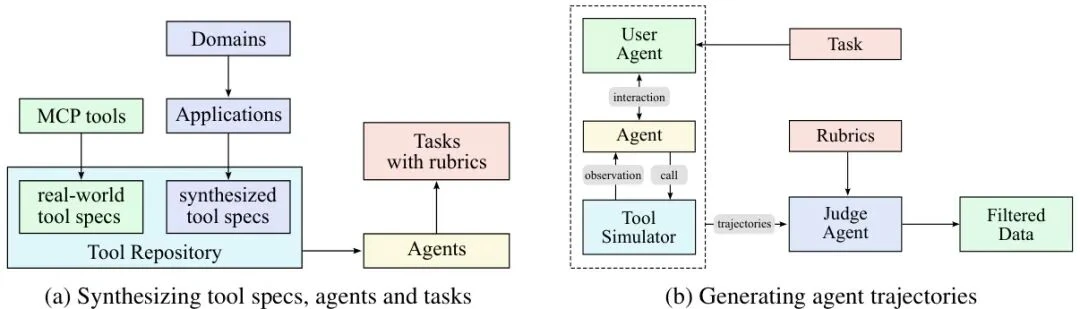
This data synthesis pipeline has several key features:
-
Massive and Diverse Tool Library: The team collected over 3,000 real tools (MCPs) from GitHub and used "domain evolution" techniques to synthesize over 20,000 virtual tools across fields like finance, software, and robotics.
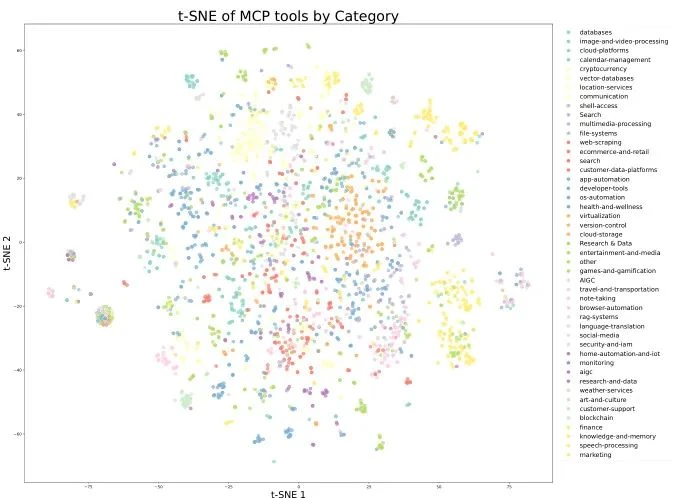
 The t-SNE dimensionality reduction plots show that real and synthetic tools cover complementary areas, together forming a comprehensive and diverse tool space, ensuring the model can learn a wide range of tool-use capabilities.
The t-SNE dimensionality reduction plots show that real and synthetic tools cover complementary areas, together forming a comprehensive and diverse tool space, ensuring the model can learn a wide range of tool-use capabilities. -
Diverse Agents and Tasks: By creating different "personas" (system prompts) and assigning various tool combinations, the team generated thousands of agents with distinct capabilities. They then created tasks of varying complexity for each agent, complete with clear success criteria (Rubrics).
-
High-Fidelity Trajectory Generation: The pipeline includes a user simulator to mimic multi-turn conversations, a tool execution environment to simulate real feedback (including success, failure, and errors), and an LLM referee to evaluate trajectory quality.
-
Hybrid of Simulation and Reality: For high-fidelity tasks like software engineering, the team combined the simulated environment with real execution sandboxes. Code is run in a real development environment, and objective metrics like unit test pass rates provide direct feedback.
This hybrid data pipeline gave Kimi K2 a solid and generalizable foundation in tool use during the Supervised Fine-Tuning (SFT) phase.
Joint Reinforcement Learning (RL) with Self-Critique
If SFT is learning from a teacher, then reinforcement learning (RL) is practicing independently. Kimi K2's RL framework combines two types of tasks for unified training.
A. Verifiable Reward Tasks (RLVR)
For tasks with clear right or wrong answers, Kimi K2 trains in a "Verifiable Rewards Gym." This virtual environment is equipped with specialized modules:
- Math, STEM, and Logic Problems: A massive collection of math competition problems and logic puzzles. The system can automatically verify the model's answer and provide a reward.
- Complex Instruction Following: Tasks with complex constraints (e.g., "Write a four-line poem about the moon that includes the word 'frost' but not 'sadness'"). The system automatically checks if all constraints are met.
- Code & Software Engineering: In a sandbox containing real GitHub issues, the model's generated code is run against unit tests. The pass rate serves as a direct reward signal.
- Safety: An automated red-teaming pipeline continuously generates "jailbreak" prompts to challenge the model. If the model maintains its safety protocols, it receives a reward.
B. Self-Critique Reward Tasks
For subjective tasks without a standard answer, such as creative writing, Kimi K2 uses a self-critique mechanism for reinforcement learning.
This process is called the Self-Critique Rubric Reward mechanism.
- K2 Actor Generates Answers: For an open-ended prompt, the K2 model (the "actor") generates several different responses.
- K2 Critic Scores the Answers: The K2 model (now in the "critic" role) uses a complex set of internal scoring criteria (a Rubric) to compare the responses and select the best one. This rubric includes general principles like clarity and relevance, as well as specific rules designed by human experts.
- Feedback Loop: The "better answer" selected by the critic is used as a positive signal to optimize the actor model.
The critic's ability is not static; it transfers the objective judgment skills learned from verifiable reward tasks to the evaluation of subjective tasks, making its evaluations increasingly reliable over time.
By combining these two task types and adding RL techniques like budget control (to prevent verbosity) and PTX loss (to avoid forgetting SFT data), Kimi K2 dramatically improved its problem-solving abilities in complex domains while maintaining its general capabilities.
Kimi K2 Benchmark Analysis: An In-Depth Performance Review
In the technical report, Kimi K2 was evaluated against today's strongest open-source and closed-source models. All evaluations were conducted using zero-shot prompting to test the models' raw, out-of-the-box intelligence.
Kimi-K2-Instruct vs. Closed-Source Models
This is the user-facing version of the model, so its performance is what matters most to end-users.
Table 3: Performance Comparison of Kimi-K2-Instruct with Top-Tier Models (Bold indicates the best overall, _underlined_ indicates the best among open-source models)
| Benchmark | Kimi-K2- Instruct | DeepSeek- V2-0324 | Qwen2.5- 235B- | Claude 3.5 Sonnet | Claude 3 Opus | GPT-4o | Gemini 1.5 Flash |
|---|---|---|---|---|---|---|---|
| Coding Tasks | |||||||
| LiveCodeBench v6 (Pass@ 1) | 53.7 | 46.9 | 37.0 | 48.5 | 47.4 | 44.7 | 44.7 |
| OJBench (Pass @1) | 27.1 | 24.0 | 11.3 | 15.3 | 19.6 | 19.5 | 19.5 |
| MultiPL-E (Pass@ 1) | 85.7 | 83.1 | 78.2 | 88.6 | 89.6 | 86.7 | 85.6 |
| SWE-bench Verified (Agentic-Single-Attempt) | 65.8 | 38.8 | 34.4 | 72.7* | 72.5* | 54.6 | |
| SWE-bench Multilingual (Pass@1) | 47.3 | 25.8 | 20.9 | 51.0 | 31.5 | 14.0 | |
| Tool Use Tasks | |||||||
| ToolBench v2 (Overall Avg@4) | 66.1 | 48.8 | 37.3 | 61.2 | 66.3 | 56.0 | 41.2 |
| AceBench (Acc.) | 76.5 | 72.7 | 70.5 | 76.2 | 75.6 | 80.1 | 74.5 |
| Math & STEM Tasks | |||||||
| AIME 2024 (Avg@64) | 69.6 | 59.4* | 40.1* | 43.4 | 48.2 | 46.5 | 61.3 |
| AIME 2025 (Avg@64) | 49.5 | 46.7 | 24.7* | 33.1* | 33.9* | 37.0 | 46.6 |
| GPQA-Diamond (Avg@8) | 75.1 | 68.4* | 62.9* | 70.0* | 74.9* | 66.3 | 68.2 |
| General Tasks | |||||||
| MMLU (EM) | 89.5 | 89.4 | 87.0 | 91.5 | 92.9 | 90.4 | 90.1 |
| MMLU-Redux (EM) | 92.7 | 90.5 | 89.2* | 93.6 | 94.2 | 92.4 | 90.6 |
| IFEval (Prompt Strict) | 89.8 | 81.1 | 83.2* | 87.6 | 87.4 | 88.0 | 84.3 |
The key takeaways from this table are clear:
- Unrivaled Code and Agent Capabilities: In tests for coding and tool use, Kimi K2 decisively outperforms all other open-source models. On real-world software engineering tasks like SWE-bench, it is competitive with the strongest closed-source models, showcasing its potential as an AI agent.
- Leads the Open-Source Pack in Math and Reasoning: On highly challenging math and science benchmarks like AIME and GPQA-Diamond, Kimi K2 also achieves the best scores among open-source models, even surpassing some closed-source competitors.
- Comprehensive Lead in General Capabilities: In general knowledge tests like MMLU, Kimi K2 is firmly in the top tier of open-source models. On IFEval, which measures instruction-following ability, it achieved the highest score of any model tested.
Kimi-K2-Base: SOTA Performance for Open-Source LLMs
The performance of the base model is a direct reflection of its pre-training quality. Here too, Kimi K2's base model demonstrates impressive raw capabilities.
Table 4: Performance Comparison of Kimi-K2-Base with Mainstream Open-Source Base Models
| Benchmark(Metric) | Kimi-K2-Base (32B/1043B) | DeepSeek-V2-Base (37B/671B) | Llama3.1-405B-Base (17B/400B) | Qwen2-72B-Base (Dense 72B) |
|---|---|---|---|---|
| English General | ||||
| MMLU | 87.79 | 87.10 | 84.87 | 86.08 |
| MMLU-pro | 69.17 | 60.59 | 63.47 | 62.80 |
| GPQA-Diamond | 50.51 | 49.43 | 48.11 | 40.78 |
| SimpleQA | 35.25 | 26.49 | 23.74 | 10.31 |
| Code | ||||
| CRUXEval-I-cot | 74.00 | 62.75 | 67.13 | 61.12 |
| LiveCodeBench(v6) | 26.29 | 24.57 | 25.14 | 22.29 |
| EvalPlus | 80.33 | 65.61 | 65.48 | 66.04 |
| Math | ||||
| MATH | 70.22 | 61.70 | 63.02 | 62.68 |
| GSM8k | 92.12 | 91.66 | 86.35 | 90.37 |
| Chinese | ||||
| C-Eval | 92.50 | 90.04 | 80.91 | 90.86 |
| CMMLU | 90.90 | 88.84 | 81.24 | 90.55 |
The takeaway is clear: Kimi-K2-Base achieves State-of-the-Art (SOTA) performance on the vast majority of benchmarks across four major domains—English general knowledge, code, math, and Chinese. This is a powerful validation of its pre-training methodology and provides an unparalleled foundation for downstream fine-tuning and agent development.
Safety and Robustness Evaluation
The Kimi team also conducted rigorous red-teaming to evaluate the model's robustness against harmful content, privacy violations, and security threats. The results show that Kimi K2 exhibits good safety in most scenarios, with a particularly high pass rate against basic attacks. Like all large models, it still has room for improvement against complex, iterative "jailbreak" attacks.
Current Limitations and Future Outlook for Kimi K2
The technical report is also transparent about Kimi K2's current limitations:
- The model can be overly verbose when tackling very difficult reasoning tasks or when tool definitions are unclear.
- It sometimes attempts to use tools when it is not necessary, which can degrade performance.
- When building complete software projects from scratch, its one-shot success rate is lower than when operating within an agentic framework.
The Kimi team stated they are actively working to address these issues and welcome community feedback to help the model continue to improve.
Conclusion: Kimi K2's Blueprint for Open-Source Agentic AI
The release of Kimi K2 represents a significant contribution to the open-source AI community. Its novelty lies not just in its scale but in its meticulously documented engineering, which provides a transparent blueprint for developing 'Agentic Intelligence.' From the MuonClip optimizer that ensures training stability to a sophisticated data synthesis and reinforcement learning framework, Kimi K2's architecture addresses key challenges in creating advanced AI agents.
Its benchmark performance, particularly in software engineering and tool use, validates this technical approach and demonstrates that open-source models can achieve parity with leading closed-source systems on the agentic frontier. By open-sourcing the model and its methodology, the Kimi team has provided a powerful foundation for researchers and developers, accelerating the exploration and deployment of agentic AI applications.
Kimi K2 is not an endpoint but a new baseline. It marks a step forward for open-source development, accelerating the collective journey toward more capable and general artificial intelligence.
References and Links
For your convenience, here are the expanded links to some of the important literature cited in the report:
- [1] Austin, J., et al. (2021). Program Synthesis with Large Language Models. https://arxiv.org/abs/2108.07732
- [6] Chen, C., et al. (2024). ACEBench: Who Wins the Match Point in Tool Learning? arXiv:2401
- [7] Chen, M., et al. (2021). Evaluating Large Language Models Trained on Code. https://arxiv.org/abs/2107.03374
- [10] DeepSeek-AI. (2024). DeepSeek-V2 Technical Report. https://arxiv.org/abs/2405.04434
- [32] Jimenez, C. E., et al. (2024). SWE-bench: Can Language Models Resolve Real-world Github Issues? https://openreview.net/forum?id=VTF8yNQM66
- [33] Jordan, K., et al. (2024). Muon: An optimizer for hidden layers in neural networks. https://kellerjordan.github.io/posts/muon/
- [35] Kimi Team. (2024). Kimi 1.5: Scaling reinforcement learning with llms. arXiv:2401.12599
- [58] Qin, Y., et al. (2023). Toolllm: Facilitating large language models to master 16000+ real-world apis. https://arxiv.org/abs/2307.16789
- [72] Vaswani, A., et al. (2017). Attention is All you Need. https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
Key Takeaways
• Kimi K2 features 1.04 trillion parameters, enhancing large language model capabilities.
• The model utilizes the MuonClip optimizer for improved training efficiency and performance.
• Kimi K2's open-source nature promotes collaboration and innovation within the AI community.