What is an AI Inference Engine?
An AI inference engine is the specialized software that runs a trained artificial intelligence model in a real-world application. It acts as the bridge between the model's architecture and the hardware, optimizing performance for tasks ranging from image recognition on edge devices to generating text with large language models (LLMs). The generative AI boom is powered by massive models, but this sophisticated software is the true unsung hero that brings them to life.
This article explores the evolution of these engines, revealing how the AI landscape has been shaped by two distinct eras: the age of specialized 'small' models and the current epoch of colossal large language models. This fundamental split—from diverse small models to standardized large ones—has led to two very different approaches to building inference frameworks.
Not long ago, the AI world was dominated by "small" models, primarily Convolutional Neural Networks (CNNs), designed for specific tasks. Today, we are in the large model era, where architectural diversity has given way to convergence on the Transformer architecture, seen in powerhouses like LLaMA, Deepseek, and Qwen.
Era 1: Small Model Inference for Edge Devices
The world of small model inference is a mature and battle-tested ecosystem. Frameworks have evolved from early pioneers like NCNN and TNN to sophisticated modern toolkits like MNN and TVM. Their primary goal is to squeeze every last drop of performance out of hardware, especially for edge AI applications.

A typical CNN inference framework is split into two parts: the offline Tools and the online Runtime.
Offline Tools for CNN Model Optimization
Before a model can run, it needs to be prepared. The Tools module handles this crucial pre-processing stage.
-
Converter: This tool acts as a universal translator, taking models from frameworks like PyTorch or TensorFlow (often via an ONNX format) and converting them into the engine's own high-performance internal format, or Intermediate Representation (IR). The graph then undergoes powerful optimizations:
- Constant Folding: Pre-calculating static parts of the model.
- Operator Fusion: Merging multiple operations (e.g., convolution, batch norm, ReLU) into a single, faster one.
- Static Memory Planning: Pre-allocating memory to minimize runtime overhead.
-
Compressor: This module shrinks model size using techniques like post-training quantization (reducing weight precision from FP32 to INT8) and model pruning while preserving accuracy.
-
Express Module: This provides flexibility for models with complex control flow, like loops or conditional branches, and allows developers to register custom operators for experimental layers.
-
CV Module: This integrated library provides optimized computer vision functions for pre- and post-processing (e.g., image resizing, normalization), creating a complete, high-performance pipeline without external dependencies like OpenCV.
The Runtime Engine: High-Speed Execution
The Runtime is responsible for executing the optimized model graph at maximum speed on the target hardware.
-
Pre-Inference Stage: Before execution, the runtime handles final memory allocation and performs dynamic shape inference, which is critical for models that process inputs of varying sizes (e.g., different image resolutions).
-
Backend & Operators: This is the computational core of the AI inference engine. It uses highly-tuned operators (e.g., Winograd for convolutions) and supports heterogeneous execution, intelligently scheduling operations across CPUs, GPUs, and NPUs using optimizations like Neon/AVX or acceleration via OpenCL/CUDA.
Era 2: Large Model Inference for Cloud-Based LLMs
The rise of massive, autoregressive models like GPT-4 required a new playbook. A new generation of LLM inference engines emerged to tackle their unique challenges, including LightLLM, vLLM, and TensorRT-LLM.
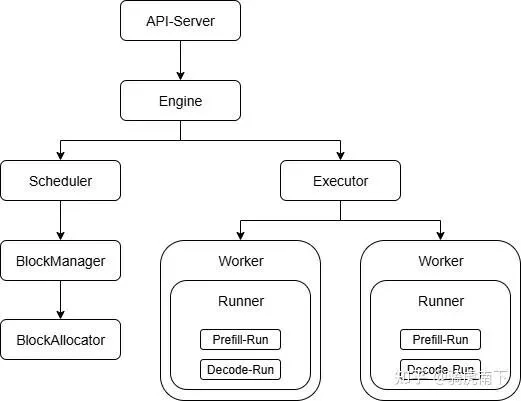
Using the popular vLLM framework as an example, we can see what makes these engines different. While they still perform operator fusion and model compression, their defining features are built to solve the core problem of autoregressive decoding.
Because each new token an LLM generates depends on all previous ones, traditional batching is incredibly inefficient. To solve this, LLM inference frameworks introduced groundbreaking techniques like Continuous Batching, PagedAttention, Packing, and Chunked Prefill to maximize GPU utilization and throughput.
Here’s a look at vLLM's inference logic:
-
Service Layer: vLLM is designed as a high-throughput server, exposing APIs like Chat and Completion endpoints for easy application integration.
-
Inference Engine (Scheduler & Executor):
- The Scheduler is the brain, orchestrating the batching strategy with Continuous Batching to dynamically group requests. It also manages the crucial KV Cache (the Transformer model's memory) using PagedAttention.
- The Executor is the muscle, executing batches on GPUs. This is split into the pre-fill phase (processing the prompt) and the decoding phase (generating the response token-by-token).
-
KV Cache Management (Block Manager): PagedAttention works like virtual memory in an OS. Instead of allocating a large, contiguous memory block for each sequence's KV Cache, it's broken into smaller, fixed-size "pages." This prevents memory fragmentation and allows the scheduler to pack requests more efficiently, dramatically increasing the number of concurrent requests a GPU can handle.
Small vs. Large Model Inference: A Comparison
The evolution of AI inference engines tells a story of divergence driven by architectural necessity.
Small model inference is a discipline of hardware intimacy. It focuses on on-chip acceleration and operator-level optimization to squeeze every last cycle out of the silicon for a single model instance, primarily for the edge.
Large model inference, defined by the monolithic Transformer, is a game of scale and concurrency. Its focus is on sophisticated dynamic batching and service scheduling to maximize throughput and serve thousands of simultaneous requests from powerful cloud infrastructure.
As these two paths continue to evolve, they represent the dual frontiers of AI deployment: one pushing intelligence into every device, the other concentrating it into powerful, centralized services that are reshaping our digital world.
Key Takeaways
• AI inference engines optimize performance for various tasks, from image recognition to text generation.
• Understanding the differences between CNN and LLM frameworks is crucial for effective implementation.
• Edge optimization and cloud-scale inference are key considerations in deploying AI models.