In the quest for peak performance, many teams rely on on-policy training for agentic tasks in reinforcement learning. However, this often requires a fully asynchronous setup, which inevitably introduces off-policy data and its associated stability issues. While off-policy methods offer greater sample efficiency, they must contend with data staleness, where the behavior policy that generated the data differs from the current policy being optimized. With the right configurations, such as routing-replay or limiting the sample-to-gradient-update ratio, off-policy methods can achieve remarkable stability. But what happens when this ratio climbs significantly higher, for instance, to 8, or even to 256? This article explores advanced importance sampling techniques designed to maintain stable training under high data staleness, trading a small amount of bias for a significant reduction in variance.
The Challenge of Data Staleness in Off-Policy RL
A basic formalization at the sequence level can be expressed as:
From a sequence-level perspective, the standard Importance Sampling (IS) ratio,  , is not a particularly stable configuration. Its variance tends to increase with the size of the action space and the length of the sequence—a phenomenon that can be analyzed through the lens of Effective Sample Size (ESS). In this scenario, high variance is the primary obstacle to stable policy optimization, so it is often worth trading some bias for a significant drop in variance. A classic, intuitive way to achieve this is with Self-Normalized Importance Sampling (SNIS):
, is not a particularly stable configuration. Its variance tends to increase with the size of the action space and the length of the sequence—a phenomenon that can be analyzed through the lens of Effective Sample Size (ESS). In this scenario, high variance is the primary obstacle to stable policy optimization, so it is often worth trading some bias for a significant drop in variance. A classic, intuitive way to achieve this is with Self-Normalized Importance Sampling (SNIS):

This approach imposes a few requirements on the training setup:
- The mini-batch must contain all rollout samples for a single prompt to calculate w(x,y).
- After each parameter update, the normalized weight
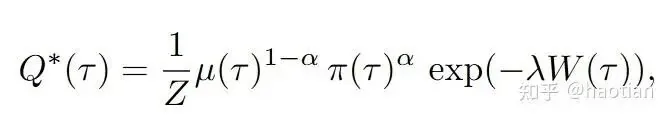 must be recomputed.
must be recomputed.
Furthermore, paper [5] proposed:

Coincidentally, a similar work [4] appeared during a review of papers for ICLR'26. (It was ultimately desk-rejected for hallucinated citations, despite initial scores of 6, 6, 6, 2). The paper [4] offers more theoretical analysis of SNIS and related methods, though its experiments were limited to LoRA-based RL.
GEPO: Group Expectation Policy Optimization
Building on these principles of variance reduction, Group Expectation Policy Optimization (GEPO) offers a more structured approach to handling data staleness. Its core formula is:

Using this Group Expectation Importance Weighting (GEIW), the authors prove a key theorem: the variance decreases exponentially compared to the naive P/Q ratio.
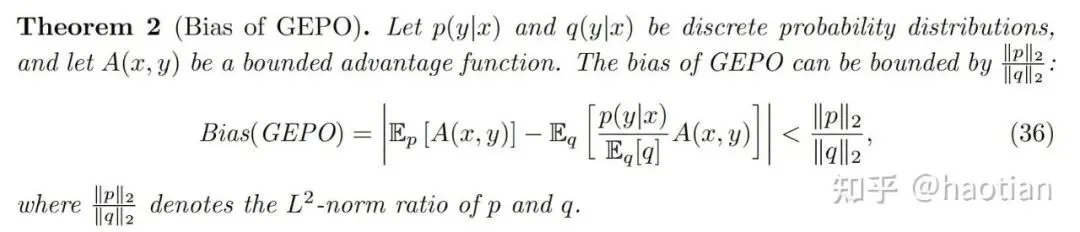
However, a reduction in variance is only useful if the introduced bias is manageable. The authors address this with an analysis of GEPO's bias in the appendix:
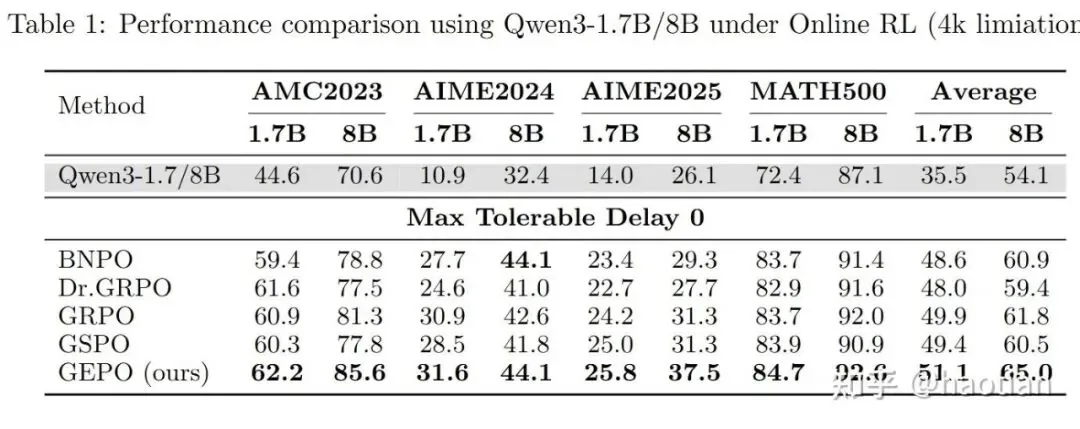
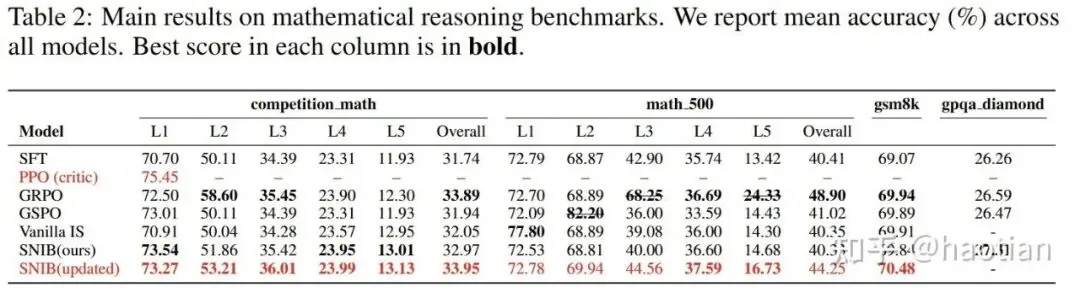
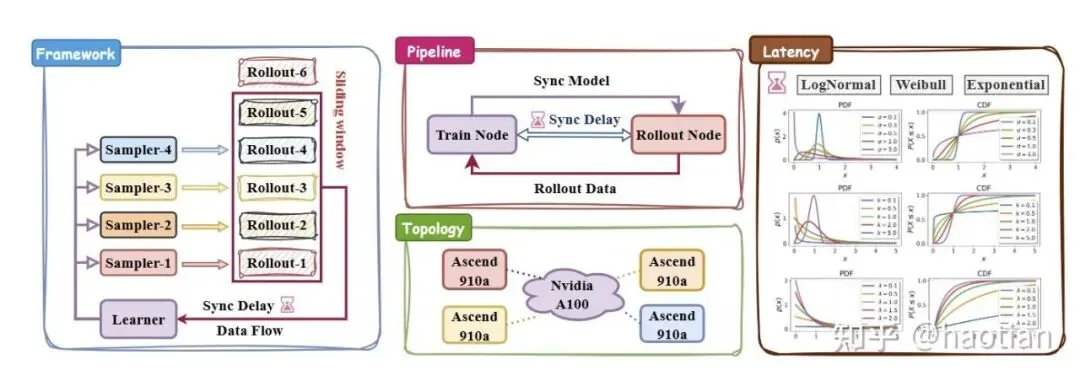
For their experimental setup, the authors used levels 3-5 of the MATH500 dataset for RL training, setting the output length to 4096 in "think-mode." The experiments were trained on NVIDIA A100s with inference running on Ascend 910A. Their findings were conclusive:
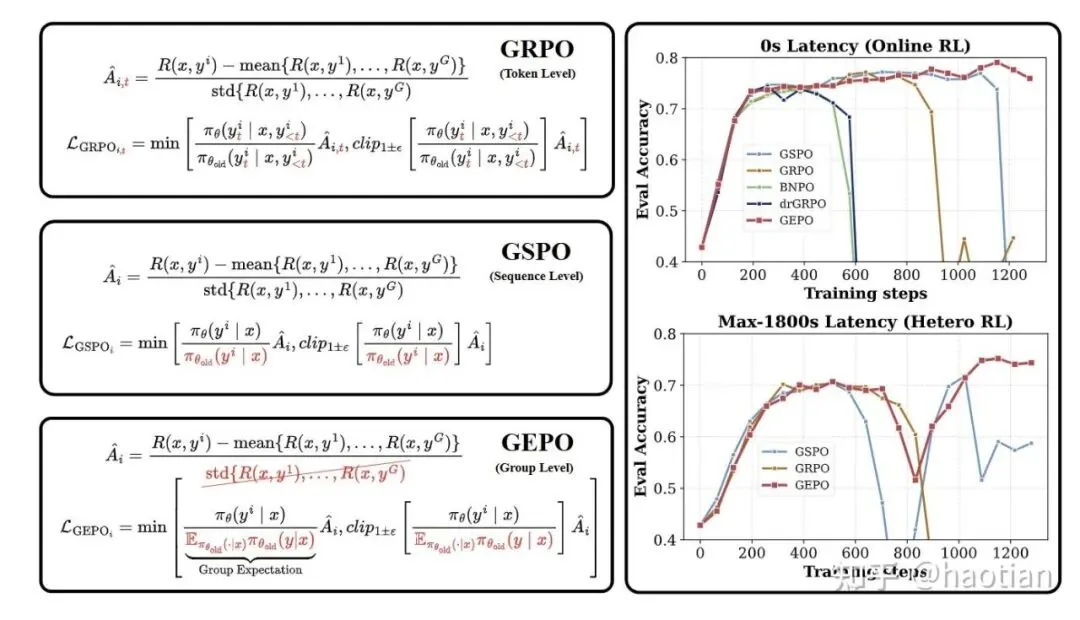
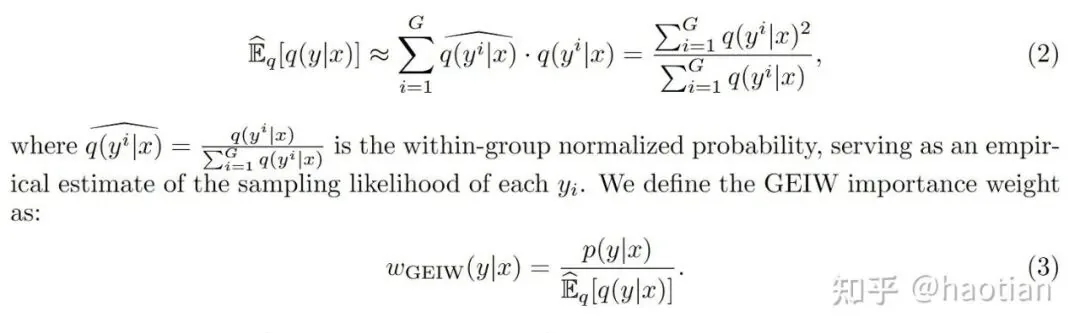
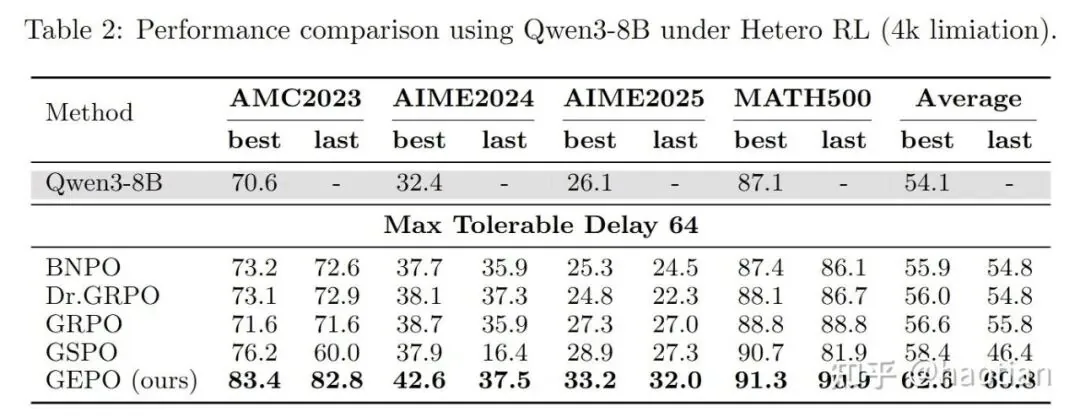

VESPO: Variational Sequence-Level Soft Policy Optimization
Another powerful technique can be found by examining literature on Annealed Importance Sampling (AIS). A paper on this topic [6] mentions:

The key insight for VESPO is its variational representation, which treats the proposal distribution as a weighted sum of KL-divergences between two distributions. In the context of reinforcement learning, these are the current policy and the rollout (or behavioral) policy.
This brings us to VESPO, a paper from the team at Xiaohongshu. This work is particularly insightful, and its experimental results are equally impressive.
Unifying Methods with Weight Reshaping
First, the authors formalize and unify several different methods:
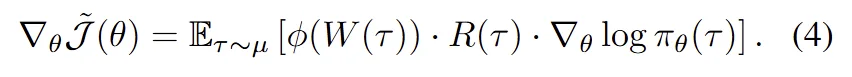
They demonstrate that these methods can all be unified under a single form:
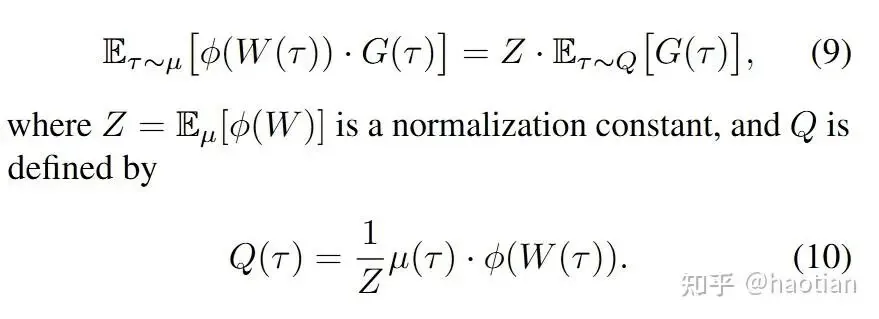
With this unified expression, the authors introduce the concept of "Weight Reshaping as Measure Change." In simpler terms, different weight-shaping techniques are equivalent to inducing a new proposal distribution.
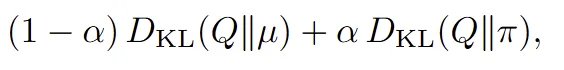
This formalization makes the next step clear: find a closed-form solution for q by applying reasonable constraints. An intuitive constraint is that the new proposal distribution, q, should be close to both the original sampling distribution and the target policy. The authors use KL-divergence to measure this closeness, though other divergences could also be used.
However, a potential issue arises when the rollout data is very stale, causing the gap between the behavioral policy 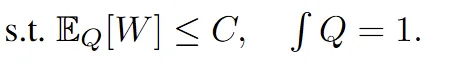 and the current policy
and the current policy 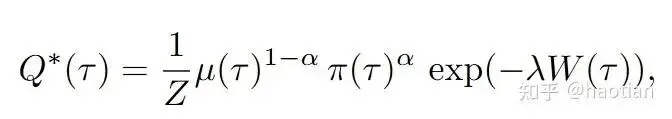 to become enormous. In such cases, the resulting q would not be an effective proposal, and performance would likely degrade severely.
to become enormous. In such cases, the resulting q would not be an effective proposal, and performance would likely degrade severely.
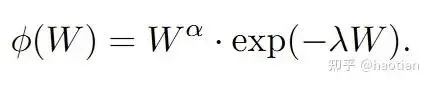
Solving with Constrained Optimization
Additionally, we need to constrain the variance of q and ensure it remains a valid probability distribution:
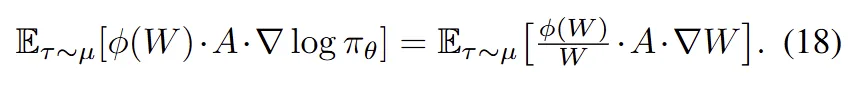
Calculating the sampling variance of q requires an approximation, for which the authors use ESS. This constrained optimization problem can be solved using Lagrange multipliers—much like deriving the optimal distribution under a KL constraint—which leads to the following solution:

By comparing this result with Equation 11, we can derive the final expression for the Weight Reshaping term, 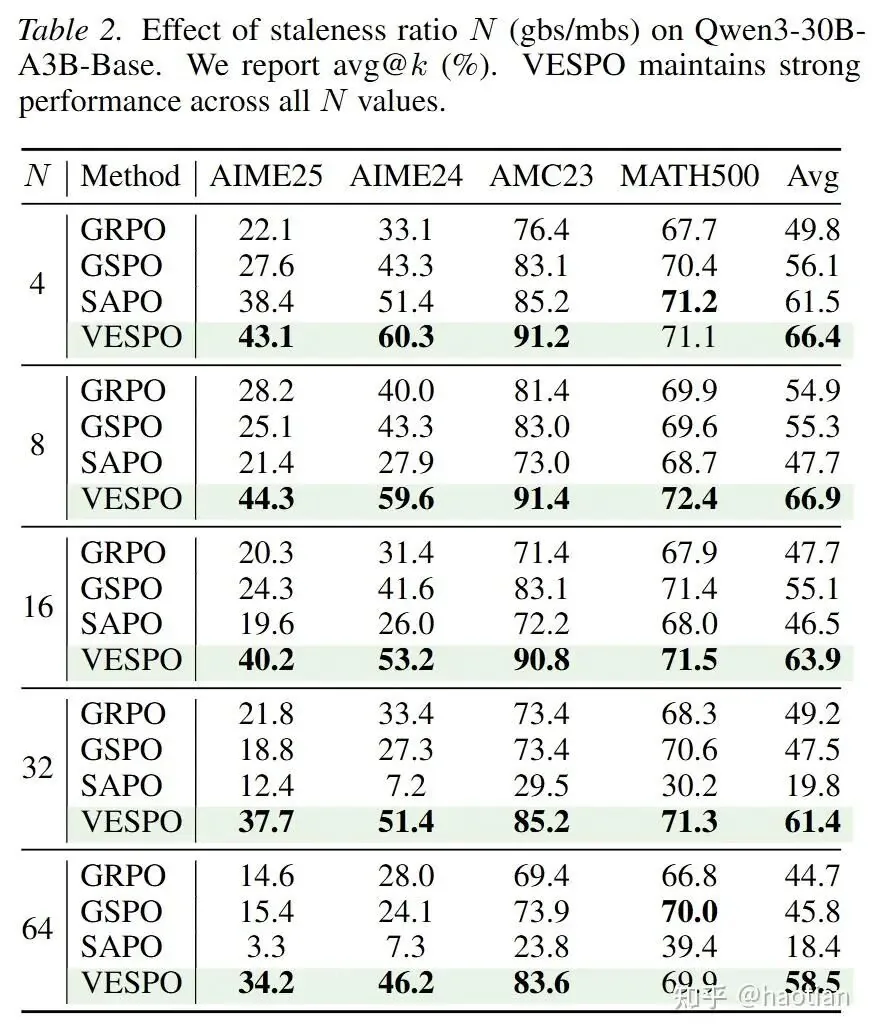 :
:
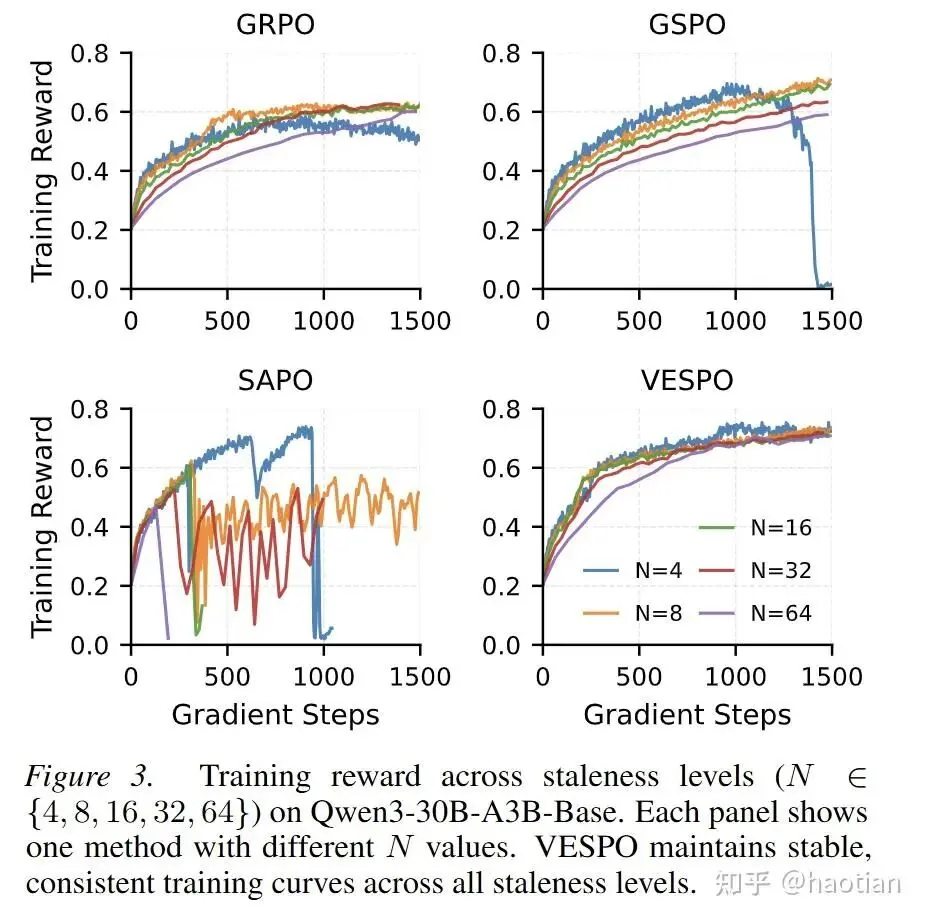
VESPO's Impressive Stability Results
The paper's results are impressive. (Note: in the actual implementation, operations are performed in the log domain for numerical stability). They show that when N=64 (meaning one rollout for every 64 gradient updates), performance degrades severely without their method. (Curiously, the authors did not report staleness results for a dense model).
With VESPO, training stability remains remarkably high across different data delays, all without needing extra techniques like routing-replay:
Conclusion: GEPO vs. VESPO for Stable Training
Both GEPO and VESPO offer valuable frameworks for maintaining training stability when dealing with high data staleness in off-policy reinforcement learning. Their core innovation lies in reshaping importance weights to reduce variance, enabling stable training even with high sample-to-gradient ratios. While a direct head-to-head comparison is difficult due to differing experimental setups, their collective insights are significant. Future work should include direct benchmarking against other techniques like sequence and token masking.
Ultimately, when using importance sampling to estimate expectations, more sophisticated proposal distributions, like those from annealed IS or parallel tempering, may be needed. This always involves a trade-off between effectiveness and computational efficiency. VESPO offers a clever way to "automatically" find a good proposal distribution, though as mentioned, its solution might become less effective when data staleness is extreme.
Furthermore, exploring how these weight-shaping methods affect parameter sparsity during optimization could unlock new research directions, potentially bridging advanced sampling techniques with optimization theory, as analyzed in [3].
References
- [1] GEPO: Group Expectation Policy Optimization for Stable Heterogeneous Reinforcement Learning https://arxiv.org/abs/2508.17850
- [2] VESPO: Variational Sequence-Level Soft Policy Optimization for Stable Off-Policy LLM Training https://arxiv.org/abs/2602.10693
- [3] The Path Not Taken: RLVR Provably Learns Off the Principals https://arxiv.org/abs/2511.08567
- [4] PRINCIPLED POLICY OPTIMIZATION FOR LLMS VIASELF-NORMALIZED IMPORTANCE SAMPLING https://openreview.net/pdf?id=HVciz8hi1c
- [5] Pareto Smoothed Importance Sampling https://arxiv.org/abs/1507.02646
- [6] Annealed Importance Sampling with q-Paths https://arxiv.org/abs/2012.07823