This article distills the technical substance from Qing Ke Ai's Chinese summary and the original paper, while removing the livestream promotion, logo art, and QR-code materials from the source post.
Paper: WideSeek-R1: Exploring Width Scaling for Broad Information Seeking via Multi-Agent Reinforcement Learning
Code: RLinf example implementation
WideSeek-R1: Why Breadth Becomes the Bottleneck
Most recent LLM progress has focused on depth scaling: one model thinks longer, uses tools over more turns, and pushes a single reasoning chain harder. That strategy works well for math, coding, and other long-horizon tasks where the main challenge is sustained deduction.
WideSeek-R1 argues that broad information-seeking tasks break that pattern. If the task is to compile a country ranking, compare multiple public companies, or aggregate facts across many entities, the bottleneck shifts away from one agent's reasoning depth and toward coverage, orchestration, and parallel execution.
That is the paper's central move: treat broad search as an organizational problem. Instead of asking one agent to serially gather everything, WideSeek-R1 trains a lead-agent-subagent system that can fan out work across multiple parallel workers and then assemble the result.
TL;DR
- WideSeek-R1 positions width scaling as a complement to depth scaling for LLM agents.
- The system uses a lead agent plus parallel subagents trained with multi-agent reinforcement learning instead of only hand-written coordination rules.
- The paper abstract reports 40.0% item F1 on WideSearch for WideSeek-R1-4B, comparable to DeepSeek-R1-671B on the same benchmark.
- The architecture uses a shared LLM with isolated contexts and specialized tools, so the system can scale coverage without collapsing into one overloaded context window.
- For background, pair this paper with LLM Reinforcement Learning (RL): REINFORCE, PPO, GRPO, and Production Engineering, Best Multi-Agent AI Frameworks for 2025 & 2026: CrewAI vs AutoGen vs LangGraph, the Token Calculator, and the Reinforcement Learning Hub.
1. From Depth Scaling to Width Scaling
The paper starts from a practical observation: strong single-agent reasoning is not the same thing as strong multi-entity coverage.
DeepSeek-R1 made depth scaling look extremely powerful, especially on tasks where a single trajectory can keep refining its own chain of thought. But broad information seeking is different. Asking one agent to look up many subproblems in sequence creates two predictable failures:
- Context interference grows as retrieval traces, tool outputs, and partial answers pile into one conversation.
- Serial execution becomes the throughput bottleneck even when the subtasks are largely independent.
WideSeek-R1 treats width scaling as the complementary answer. Instead of more turns for one agent, the system allocates more parallel search capacity across multiple subagents.
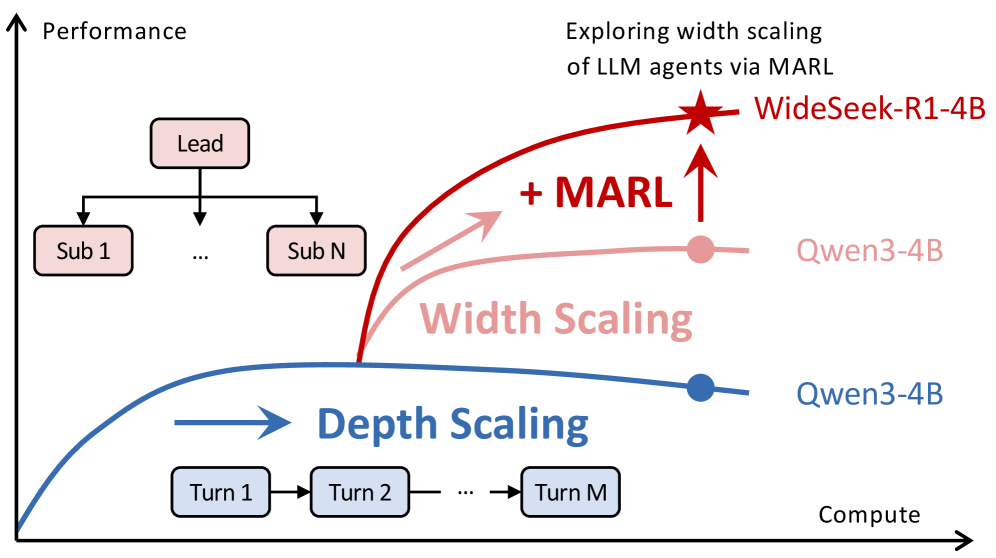
WideSeek-R1 frames breadth as a scaling axis of its own: more parallel subagents, not just deeper single-agent traces.
The conceptual result matters because it reframes what "scaling" should mean for agent systems. On broad tasks, the core question is not only "Can one model reason longer?" but also "Can the organization of agents cover more ground at the same compute budget?"
2. The Lead-Agent-Subagent Architecture
According to the paper abstract, WideSeek-R1 uses a lead-agent-subagent framework trained with multi-agent reinforcement learning. The lead agent handles decomposition and orchestration. The subagents execute search and evidence gathering in parallel, each with its own isolated context.
That isolation is important. It means subagents can pursue different search branches without polluting one another's memory, while still sharing the same underlying LLM weights and tool stack.
The architecture figure also makes the training story more concrete:
- The rollout path sends one query to a lead agent, which dispatches multiple subtasks to parallel subagents.
- Each subagent returns a partial response, and the lead agent composes the final answer.
- The training block shows a GRPO loss, group-normalized rewards, multi-agent advantage assignment, and dual-level advantage reweighting across the agent and token levels.
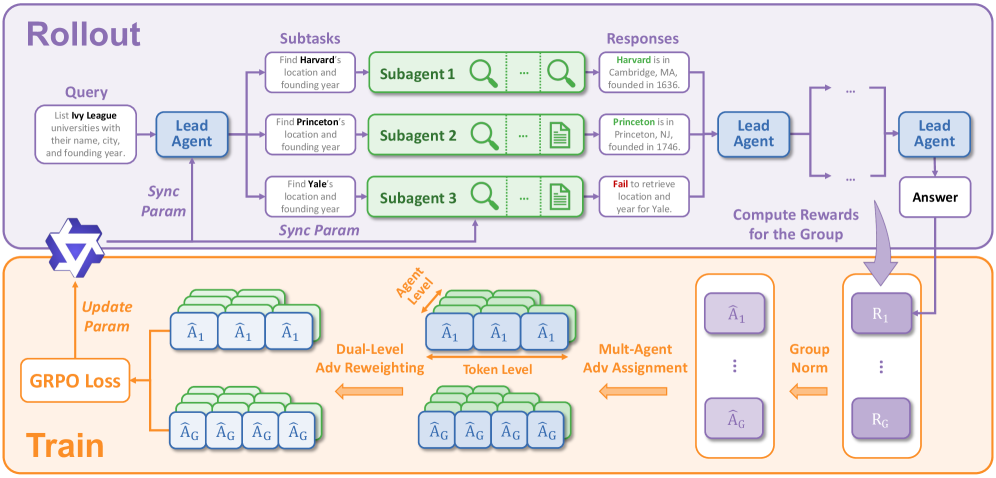
The paper's system diagram emphasizes learned orchestration: parallel rollout on top, MARL-based training on the bottom.
This is the more interesting distinction versus many production multi-agent stacks. A lot of agent systems today use explicit orchestration graphs or hand-written routing logic. WideSeek-R1 instead asks whether coordination itself can be learned as part of the policy.
3. Building a Dataset for Broad Information Seeking
The third figure is useful because it shows the authors treating data construction as a first-class systems problem.
The pipeline begins with structured source data, shown here as HybridQA, then converts that data into broad information-seeking tasks through three stages:
- Query generation: infer user intent, sample the target table size, and generate a refined query.
- Answer generation: create two independent answers and extract unique columns for comparison.
- QA-pair filtering: keep only examples with high cell-wise agreement and enough task hardness.
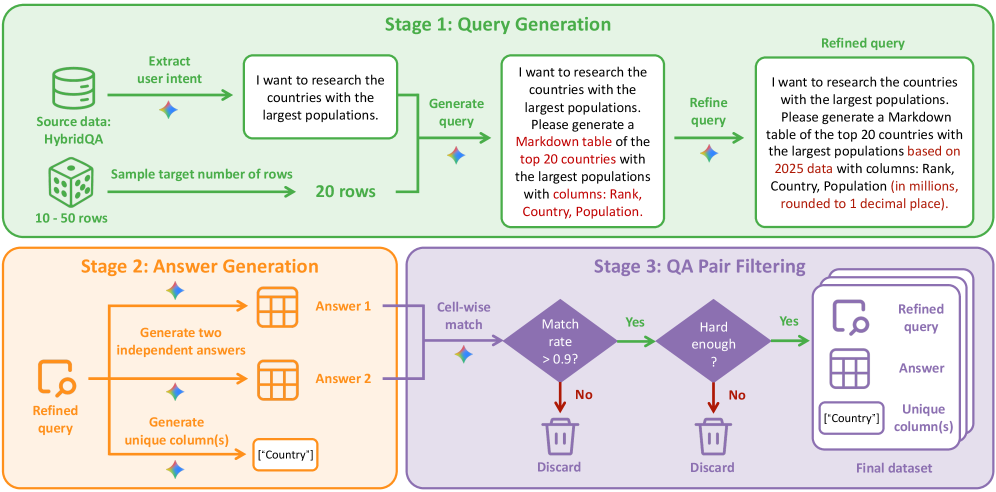
The data pipeline turns structured tables into harder broad-search tasks that reward coverage, decomposition, and answer consistency.
The abstract says the final training corpus contains 20k curated broad information-seeking tasks. That is a useful design choice because it pushes the policy toward tasks where parallel coverage actually matters, instead of mixing in too many examples that a single agent can solve just by thinking longer.
4. What the Reported Results Actually Mean
The headline number from the paper abstract is straightforward: WideSeek-R1-4B reaches 40.0% item F1 on WideSearch, which the authors describe as comparable to single-agent DeepSeek-R1-671B.
Even if you treat that number cautiously until reading the full experimental section, the result points to a meaningful systems claim:
- Bigger single-agent reasoning is not the only path to better agent performance.
- Organization quality can substitute for raw model scale on broad tasks.
- Parallel subagents can convert a small model into a much stronger information-seeking system when the task is decomposable.
The abstract also notes that WideSeek-R1-4B improves consistently as the number of parallel subagents increases. That is exactly what a width-scaling hypothesis should predict. If more subagents continue to raise performance, then the architecture is capturing a genuine scaling law rather than a one-off prompt trick.
5. Why WideSeek-R1 Matters Beyond This Paper
WideSeek-R1 is interesting because it does not argue that depth scaling has stopped working. It argues that depth scaling is not the whole story.
For agent products that must synthesize many facts, compare multiple entities, or search several tools at once, the limiting factor often looks more like organizational bandwidth than raw step-by-step reasoning. That makes WideSeek-R1 relevant well beyond academic benchmarks:
- research agents that must cover many subtopics quickly,
- enterprise search workflows that aggregate evidence across teams or systems,
- analyst assistants that need structured comparisons rather than one long chain of thought.
In that sense, the paper gives a clean mental model for the next stage of agent design: depth scaling improves an individual worker, while width scaling improves the organization built around that worker.
Conclusion
WideSeek-R1 turns a familiar intuition into a research program. When tasks become broad enough, the main optimization target is no longer just smarter reasoning inside one trace. It is better coordination across many traces.
That is why the paper feels important. It suggests that future agent progress may come from scaling organizations, not only scaling minds. If you are tracking where reinforcement learning intersects with agent systems, this paper fits naturally beside our LLM RL guide, the multi-agent frameworks overview, and the broader Reinforcement Learning Hub.