Source article by He Zeyu, Tsinghua University. Original Chinese article: WeChat.
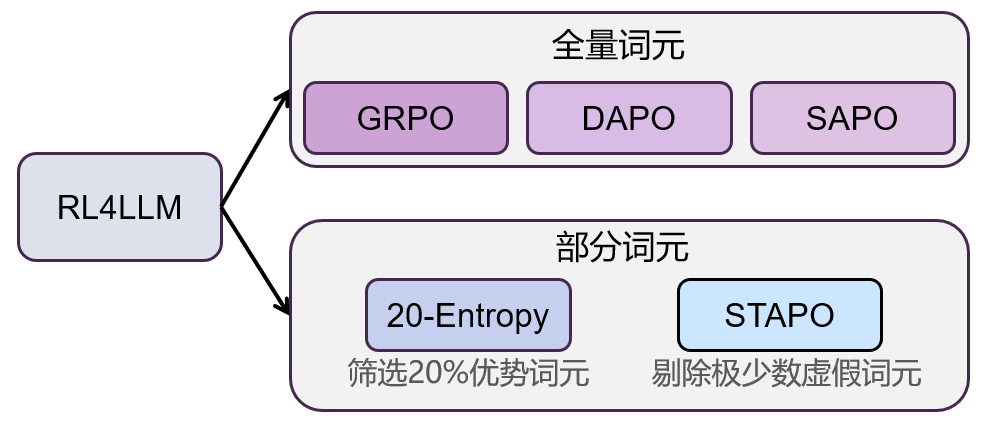
RL for LLMs: From Full-Token to Partial-Token Optimization
In recent years, large language models such as OpenAI's o1 series, DeepSeek's R1, and the Qwen series have demonstrated remarkable gains in stability and reasoning, particularly in complex, long-chain tasks like mathematical proofs and code generation.
This progress is increasingly driven by Reinforcement Learning for Large Language Models (RL4LLM), a core technique in the post-training alignment stage.
Compared to earlier methods that relied on Supervised Fine-Tuning (SFT) or Direct Preference Optimization (DPO), RL4LLM provides training signals more directly correlated with final performance. It accomplishes this by constructing optimization objectives around the correctness of a result or the quality of task completion. This approach is also widely considered a key factor in developing the chain-of-thought reasoning capabilities of modern models.
Following foundational policy gradient methods, the field of reinforcement learning for large models has evolved along a distinct path. To systematically map this development, this article classifies these methods based on the 'scope of tokens involved in optimization':
One class of methods optimizes all tokens in a generated sequence, emphasizing the modeling of global consistency.
Another class uses optimization signals from only a select subset of tokens to reduce noise and improve training stability.
Based on this criterion, existing methods can be broadly categorized into two main directions: 'Full-Token Optimization' and 'Partial-Token Optimization.'
TL;DR
- Full-token optimization updates every generated token and evolves from GRPO to DAPO, GSPO, and SAPO.
- Partial-token optimization filters for the tokens that matter most, as seen in Beyond the 80/20 Rule and STAPO.
- The key tradeoff is straightforward: full-token methods prioritize global stability, while partial-token methods improve signal density and reduce noisy gradients.
- For broader context, continue with LLM Reinforcement Learning (RL): REINFORCE, PPO, GRPO, and Production Engineering, Flexible Entropy Control in RLVR: Fixing Policy Entropy Collapse with Dynamic Clipping, the Token Calculator, and the Reinforcement Learning Hub.
To make the following formulas easier to follow, let's standardize the notation:
- is the input question or prompt.
- is the -th response sequence generated by the model, and is its length.
- is the -th token in the -th response.
- and represent the current policy and the reference (old) policy, respectively.
 represents the probability ratio of generating a token between the new and old policies.
represents the probability ratio of generating a token between the new and old policies.- represents the sequence-level advantage function.
- represents the number of candidate responses obtained through group sampling for the same input.
- (and later in the text) represents the clipping threshold in the policy update.
Full-Token Optimization in RL4LLM: From GRPO to SAPO
The core idea behind full-token optimization is to use every single output token to update the model's policy. This path, starting with the influential GRPO algorithm, has gradually evolved through DAPO, GSPO, and SAPO. The overarching goal has been to continuously improve training efficiency and gradient stability without sacrificing optimization strength.
GRPO: A Lightweight Approach to Policy Optimization
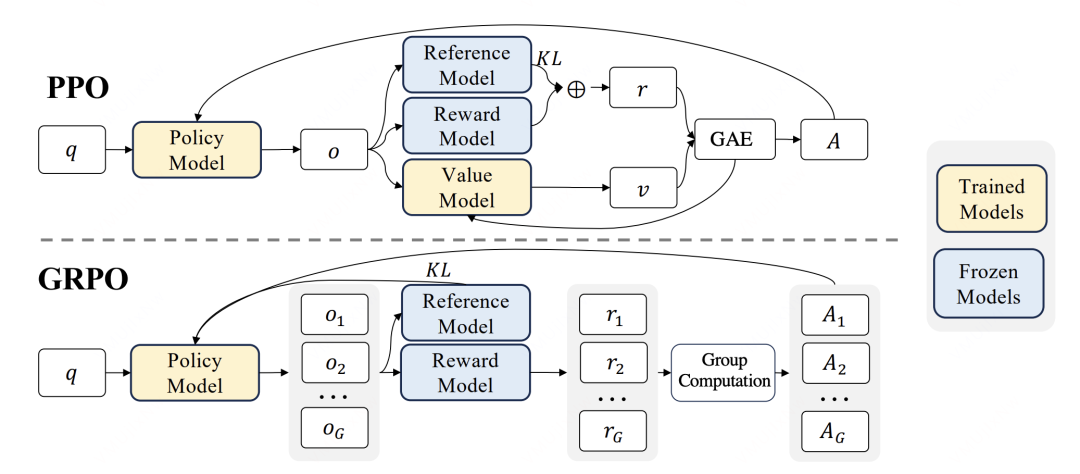
Paper: DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Introduction: GRPO marked a significant shift in the field, garnering substantial attention for its novel, resource-efficient approach.
Core Innovation: Previous reinforcement learning methods for LLM fine-tuning typically required separate networks to estimate value or rewards. GRPO cleverly sidesteps this by using a group sampling mechanism and a rule-based reward function. Its key innovation was eliminating the traditional critic model, which drastically reduces memory consumption.

The trade-off, however, is that the diversity of positive and negative samples depends heavily on the intra-group sample size during the rollout phase. This can lead to lower sampling efficiency and potential training instability.
DAPO: Refining Policy with Asymmetric Clipping
Paper: DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Introduction: DAPO refines GRPO with several fine-grained improvements across three key areas.
Core Innovation: The algorithm introduces a global token coefficient to normalize and stabilize gradient fluctuations caused by varying sequence lengths within a group. It also adopts asymmetric clipping ( and ) to prevent entropy collapse during training. Finally, DAPO uses dynamic sampling (discarding invalid sample groups where rewards are all 0s or all 1s) to boost efficiency and incorporates a soft penalty for output length.

GSPO: A Sequence-Level View for MoE Models
Paper: Group Sequence Policy Optimization
Introduction: The GSPO algorithm was developed primarily to tackle the training-inference inconsistency found in Mixture-of-Experts (MoE) models.
Core Innovation: GSPO's main improvement lies in its treatment of the importance sampling coefficient. It swaps the token-level probability ratio for the sequence-level probability ratio of the entire sentence, helping to overcome the instability that can arise from focusing on individual tokens:

Optimization Objective: Accordingly, GSPO's objective function replaces the original token-level ratio with the sequence-level ratio :

This modification better aligns with the goal of decreasing perplexity (PPL) during pre-training and effectively mitigates the expert routing inconsistency between the Rollout Engine and the Model Engine in MoE architectures.
SAPO: Using a Soft Trust Region for Policy Updates
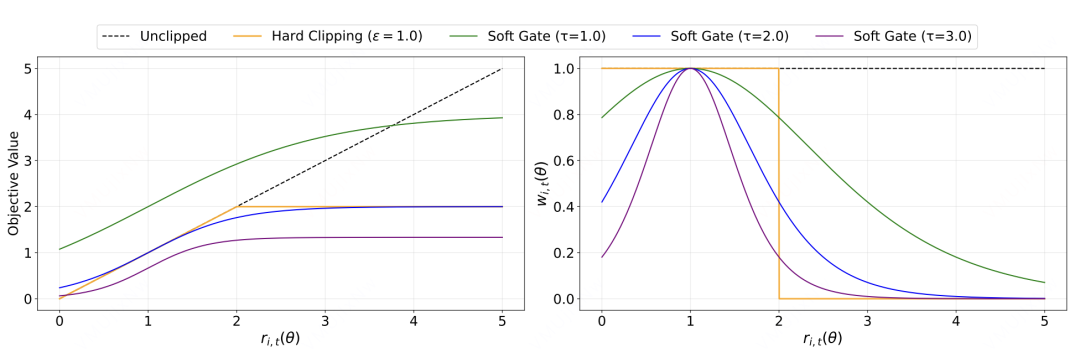
Paper: Soft Adaptive Policy Optimization
Introduction: SAPO strikes a balance between the model's exploitation and exploration by modifying the traditional hard clipping mechanism.
Core Innovation: SAPO ditches the rigid clip operation in favor of a token-level soft trust region (Soft Control):

By designing asymmetric temperature parameters for positive and negative tokens (using when the advantage is positive, and otherwise), it achieves more fine-grained control over the policy updates.

Partial-Token Optimization: A Targeted RL4LLM Strategy
While full-token algorithms were busy refining stability, the research community started asking a fundamental question: Are all tokens in a response equally important for policy updates? Which tokens truly drive the learning process?
The reality is, many tokens—like common connecting words—provide very little useful gradient information. Worse, some plausible-sounding but hallucinatory tokens can introduce destructive noise into the training process. This realization gave rise to the cutting-edge branch of Partial-Token Optimization, which filters tokens using an indicator function so that only a select subset contributes to the loss calculation.
Beyond the 80/20: High-Entropy Token Optimization
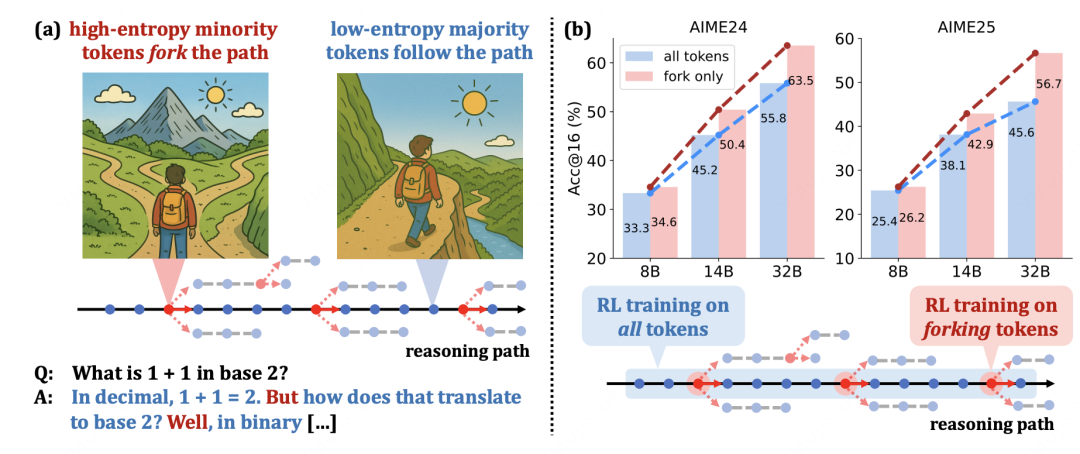
Introduction: The core idea of Beyond the 80/20 (also known as 20-Entropy) is to allocate the update budget based on a token's information content, moving away from the traditional all-tokens-in approach.
Core Innovation: The key insight here is that not all tokens are created equal. Low-information tokens can dilute the gradient, weakening the learning signal. To address this, the method first calculates each token's entropy and then constructs a filter mask using a threshold , retaining only high-entropy tokens for the policy update.

This 'filter-first, optimize-later' approach concentrates computational resources where they matter most, increasing the density of effective gradients and leading to a more stable optimization signal for the same computational budget.
STAPO: Silencing Spurious Tokens for Stable Training
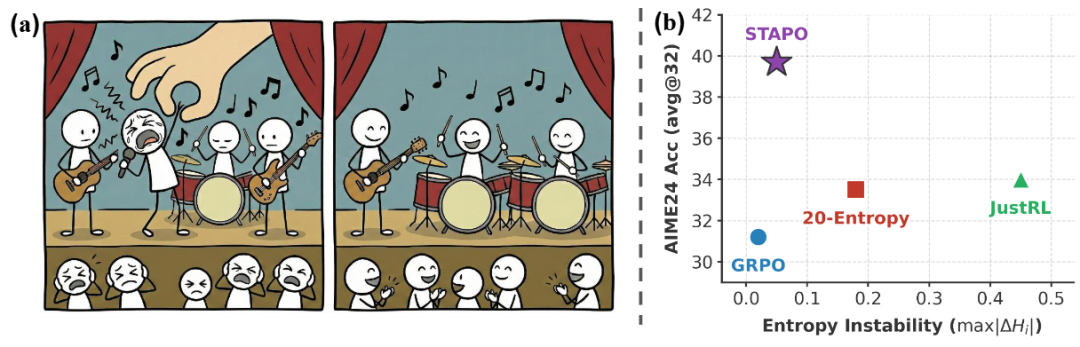
Paper: STAPO: Stabilizing Reinforcement Learning for LLMs by Silencing Rare Spurious Tokens
Introduction: Building on the principle of targeting high-value tokens, STAPO—a recent method from a team at Tsinghua University—adopts a more surgical approach. Its core principle is to identify and neutralize the small fraction of 'spurious' tokens that can destabilize the training process. By modifying as little as 0.01% of tokens, it has achieved state-of-the-art performance.
Core Innovation: STAPO is the first method to explicitly define 'spurious tokens': harmful tokens that appear in a sequence with a positive final reward but also exhibit a large gradient norm, low entropy, and low probability. In essence, they are confidently generated but incorrect tokens within an otherwise good response, and reinforcing them can be destructive. STAPO therefore proposes the Silencing Spurious Tokens (S2T) mechanism:

Here, and are the probability and entropy thresholds. This criterion flags tokens that meet a trifecta of conditions: 'low probability + low entropy + positive advantage.' When an overall sequence is correct, but a specific token within it is both unlikely (low probability) and generated with high confidence (low entropy), S2T flags it as spurious. It then nullifies its contribution to the loss, preventing a single problematic token from corrupting the gradient update.
Optimization Objective:

The key insight behind STAPO is its precision. Without disrupting the overall coherence of the generated text, it removes the influence of a tiny fraction of spurious tokens (as little as 0.01%). This leads to comprehensive improvements in policy entropy, stability, and convergence, ultimately achieving leading performance among similar algorithms.
Conclusion: The Future of RL4LLM Optimization
In summary, the evolution of RL4LLM methods reveals a clear trajectory from 'full-scale, uniform updates' to a more sophisticated phase of 'fine-grained updates based on token contribution.'
- The first wave, represented by GRPO, DAPO, GSPO, and SAPO, focused on optimizing training stability and efficiency across all tokens.
- The second wave, led by methods like 20-Entropy and STAPO, enhances training by concentrating on high-value tokens and suppressing spurious ones. This boosts effective gradient density, stabilizes policy entropy, and improves convergence.
This paradigm shift from 'full coverage' to 'fine-grained filtering' is proving to be a critical factor in improving LLM training efficiency and strengthening logical coherence. Future research will likely push this granularity further, perhaps by dynamically adjusting the optimization scope based on task complexity or even modeling the interdependencies between tokens to create more robust and efficient learning signals.