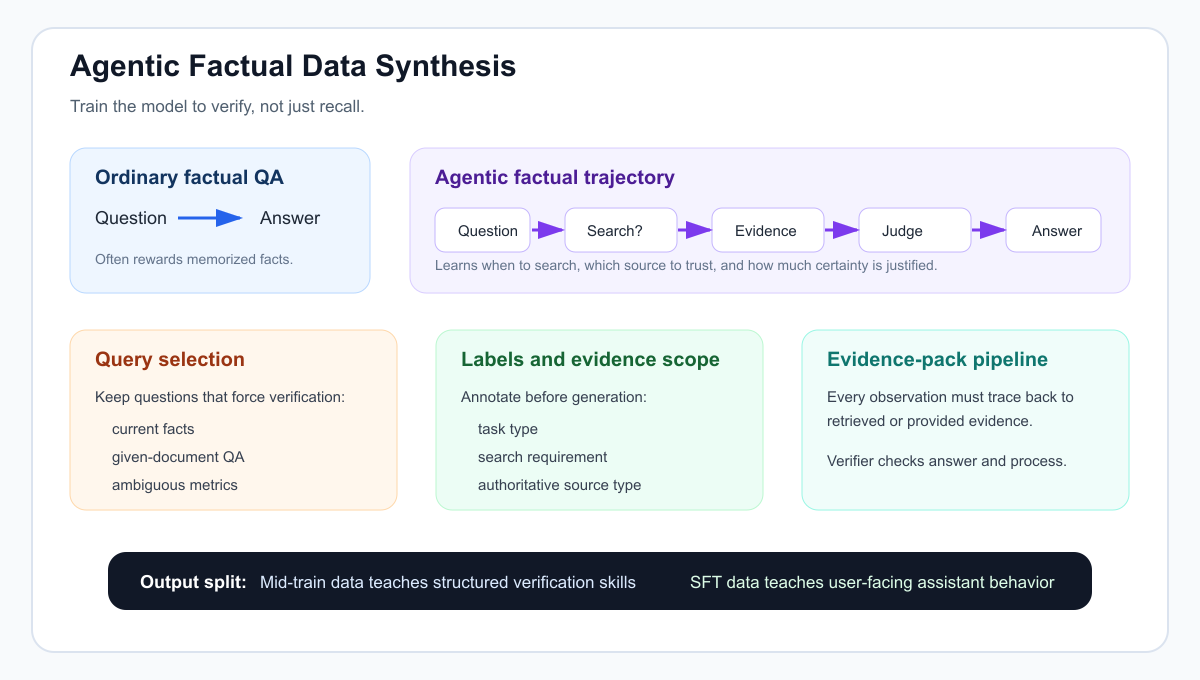
Agentic factual training is not about teaching a model to recite facts from memory. It is about teaching the model to run a visible, checkable, and reviewable verification process.
For an ordinary factual QA dataset, the target may be just:
Question -> Answer
For an agentic factual dataset, the target is closer to:
Question -> search decision -> evidence observation -> evidence judgment -> final answer
That distinction matters. A model that answers from memory may be right on common, stable facts, but it will struggle when the question depends on recency, source authority, reporting scope, or hidden assumptions. A factual agent should know when the answer must be checked, what should be checked, where reliable evidence is likely to live, and how much certainty the evidence actually supports.
The goal is therefore not just "give the correct answer." The goal is to train the model to verify before it answers.
1. Start With the Ability You Want to Train
Ordinary factual QA trains a direct mapping:
Question: Who is the current CEO of Alibaba Group?
Answer: Eddie Wu.
Agentic factual data trains a process:
Question: Who is the current CEO of Alibaba Group?
Action: search("Alibaba Group current CEO official")
Observation: Alibaba Group's official leadership page lists Eddie Wu as CEO.
Final: At the time of this check, Alibaba Group's official leadership page lists Eddie Wu as CEO.
The answer is still important, but the training value is in the behavior around it:
- The word "current" signals a time-sensitive fact.
- Official sources should be preferred over summaries or media rewrites.
- The final answer should carry a time boundary.
- The model should not answer from stale memory when the fact may have changed.
That is the core behavior to preserve when building agentic factual data.
2. Select Queries That Produce Useful Trajectories
More queries are not automatically better. Some questions are too simple to teach agentic behavior:
What is the capital of China?
That kind of query does not force the model to decide whether it should search, compare evidence, resolve ambiguity, or handle uncertainty.
Better queries create a meaningful verification path:
- Who is the current CEO of Alibaba Group?
- Was a specific company profitable in 2023?
- According to this filing, what was the company's fourth-quarter revenue?
- Has a drug been approved for a particular indication?
- Did the company founded by a certain person release a large model in 2024?
These questions test factual judgment, not just recall. They force the model to reason about recency, evidence scope, authority, hidden assumptions, metric definitions, conflicting sources, and cases where evidence is insufficient.
3. Label the Query Before Generating the Trajectory
Query labels are useful because different factual questions require different verification behavior.
A "current CEO" question should usually check recent official sources. A "based on this filing" question should stay inside the provided document. A "was the company profitable" question must first define the profitability metric. A question asking for private or unreleased information may need a refusal instead of a search.
A practical annotation scheme can use two layers.
The first layer is the factual task type:
- Time-sensitive factual question: current CEO, latest version, current policy status.
- Given-document QA: answer only from a filing, paper, announcement, or provided context.
- False-premise detection: the question may contain an assumption that is not true.
- Metric or scope ambiguity: terms like profitable, open-source, listed, effective, or better need definitions.
- Conflicting-evidence handling: multiple sources may disagree.
- Insufficient-evidence refusal: private, unpublished, or unverifiable information.
The second layer describes how the trajectory should be generated:
- Evidence scope: provided document only, open web search, database lookup, or internal corpus.
- Search requirement: whether a tool call is necessary.
- Authority requirement: whether official filings, company pages, regulatory databases, or primary sources are required.
- Recommended sources: the likely source types to inspect.
- Trajectory strategy: the verification behavior the sample should demonstrate.
For example:
{
"task_type": "metric_ambiguity",
"evidence_scope": "open_search",
"requires_search": true,
"requires_authoritative_source": true,
"recommended_sources": ["annual report", "company announcement", "exchange filing"],
"trajectory_strategy": "Check both net income and adjusted EBITDA, then answer by metric instead of giving a single yes/no."
}
This prevents the data generator from producing a shallow answer. The sample should not simply say "profitable" or "not profitable"; it should first establish the accounting basis.
4. Define the Shape of the Trajectory
A complete trajectory does not need to be complicated. A compact format can include four parts:
{
"query": "The user's factual question",
"category": "The factual task type",
"evidence": ["What source was checked and what it supports"],
"response": "The verification trajectory and final answer the model should learn"
}
For a profitability question, a training item may look like this:
{
"query": "Was Company X profitable in 2023?",
"category": "metric_ambiguity",
"evidence": [
"E1: The annual report shows a net loss attributable to shareholders of $1.2 billion.",
"E2: A company announcement says adjusted EBITDA was positive."
],
"response": "First check the annual report's net income metric, then check adjusted EBITDA. Final answer: by net income, the company was loss-making; by adjusted EBITDA, it was profitable. Do not state that the company was simply profitable without specifying the metric."
}
The important property is that the observation comes from evidence, not from the model's imagination.
5. Do Not Make Mid-Train and SFT Data Identical
Mid-train data and SFT data should not be formatted the same way because they train different parts of the behavior.
Mid-train data is better for capability acquisition. It can be more structured and less conversational. The target is to teach low-level factual skills:
- Decompose a claim.
- Match claims to evidence.
- Judge support, contradiction, or insufficiency.
- Handle conflicting evidence.
- Detect false premises.
A mid-train example can be shaped like:
Question -> claim decomposition -> evidence -> stance judgment -> reasoning basis -> conclusion
SFT data is more about behavior alignment. It should resemble what the final assistant should do in front of a user:
- Decide whether a search is needed.
- Use the right source.
- Summarize what the evidence says.
- Cite or describe evidence boundaries.
- Give a concise, calibrated answer.
An SFT example can be shaped like:
User question -> assistant action/observation -> final answer
In short: mid-train data teaches the factual verification muscles; SFT data teaches the assistant how to use those muscles in a user-facing interaction.
6. A Practical Synthesis Pipeline
A workable data synthesis pipeline can be simple:
Clean and deduplicate queries
-> classify and tag queries
-> build evidence packs
-> generate trajectory samples
-> score with a verifier
-> write to SFT or mid-train format
The key object is the evidence pack. The generated trajectory should draw its observations from that pack. If the model is allowed to invent observations, it may produce fluent but ungrounded traces such as "the official website shows..." without any real evidence behind the claim.
The verifier should score more than the final answer. It should also check whether:
- The query type was recognized correctly.
- The search decision was appropriate.
- The cited evidence is actually in the evidence pack.
- The final answer is consistent with the evidence.
- Uncertainty is expressed when evidence is weak or conflicting.
This makes the data useful for training agentic factual behavior rather than just answer memorization.
7. Common Failure Modes
There are a few recurring traps in this kind of data.
Invented observations. The trajectory says "the official website shows X," but no source actually supports it. The fix is to require every observation to be traceable to the evidence pack.
Only checking the final answer. Some answers are accidentally correct even when the reasoning path is bad. Agentic factual data should evaluate whether the model searched when needed, used the right source, and handled evidence properly.
Searching for everything. Tool use is not the same as agentic ability. If the user says "based on this filing," the model should stay inside that filing. A good factual agent knows when not to search.
Over-answering when evidence is insufficient. If reliable evidence cannot be found, the model should downgrade certainty, ask for more context, or refuse. It should not fabricate a confident answer.
The best agentic factual samples teach a model to be useful and constrained at the same time: actively verify when the fact requires it, but only say what the evidence supports.