Inspired by Maarten Grootendorst's Visual Guide to LLM Agents, this deep dive unpacks the world of LLM agents. Through detailed illustrations, we'll explore their core components and the LLM agent architecture of both single- and multi-agent systems, explaining exactly how these autonomous AI systems work.
What is an LLM Agent?
An LLM agent is an autonomous system built around a Large Language Model (LLM) that can perceive its environment, make decisions, and take actions to achieve a specific goal. Unlike a standard LLM, which only predicts the next word, an LLM agent is augmented with components like memory, tools, and a planning module to overcome the inherent limitations of the base model.
From Next-Token Prediction to Augmented LLMs
At their core, standard Large Language Models (LLMs) are sophisticated next-token predictors. They excel at generating human-like text by predicting the most probable next word, one after another.
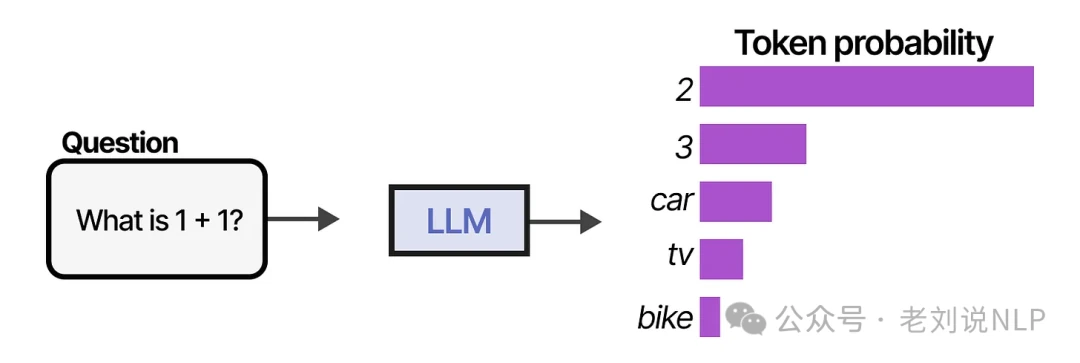
By stringing together enough of these predicted tokens, we can simulate a conversation, getting the LLM to answer questions in detail.

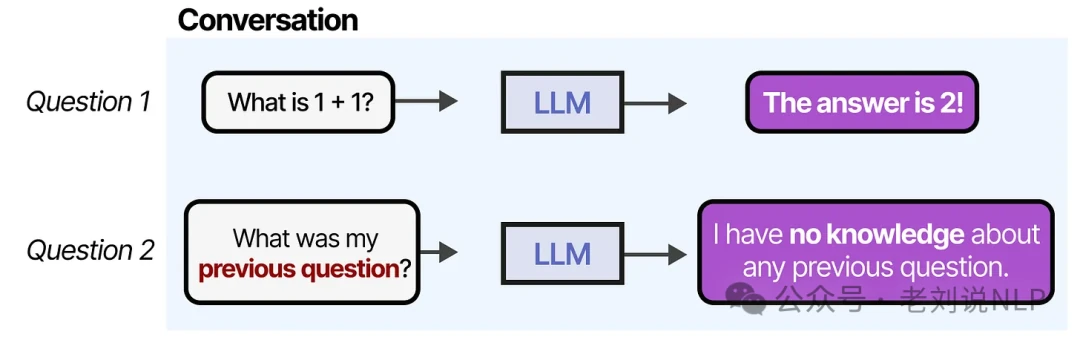
However, this conversational dance quickly reveals a fundamental weakness: LLMs have no memory of past interactions. Each new prompt is a blank slate.
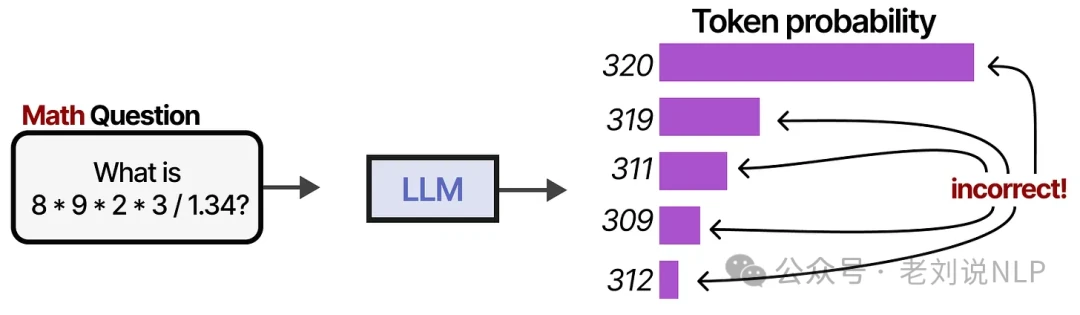
This isn't their only blind spot. LLMs often stumble on tasks that seem simple to us, like basic multiplication and division.
So, are LLMs fundamentally flawed? Not at all. An LLM doesn't need to be a jack-of-all-trades. The magic happens when we augment them, compensating for their weaknesses with external tools, memory, and retrieval systems.
By connecting an LLM to these external systems, we can dramatically expand its capabilities. Anthropic refers to this concept as an "Augmented LLM."
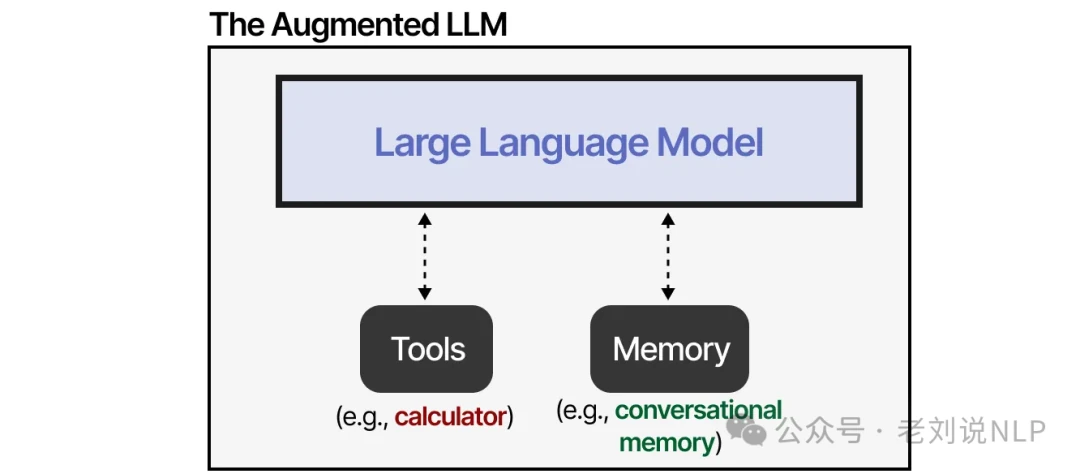
For instance, when faced with a math problem, an augmented LLM can recognize its limitation and decide to use the right tool for the job—a calculator.
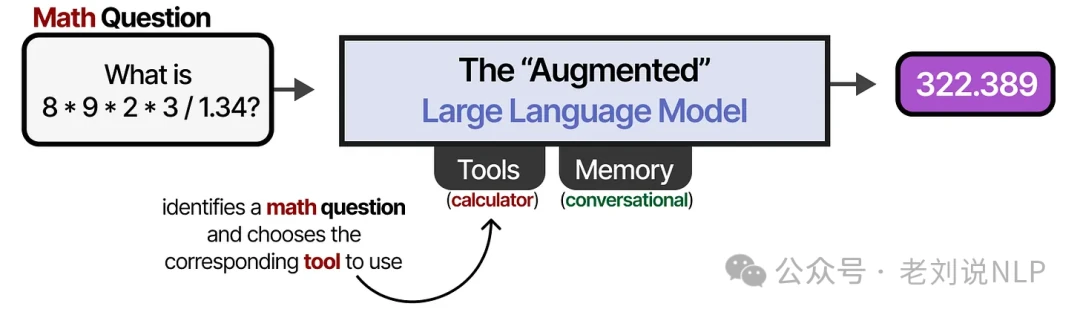
This "Augmented LLM" is very close to being an agent, but it's missing a few key pieces.
The Core Components of an LLM Agent Architecture
An agent is a system that perceives its environment and acts upon it. A classic agent framework includes several key components:
- Environments: The world—digital or physical—where the agent operates.
- Sensors: The inputs the agent uses to observe its environment.
- Controller: The 'brain' or decision-making logic that translates observations into actions.
- Actuators: The tools or mechanisms the agent uses to interact with and affect its environment.
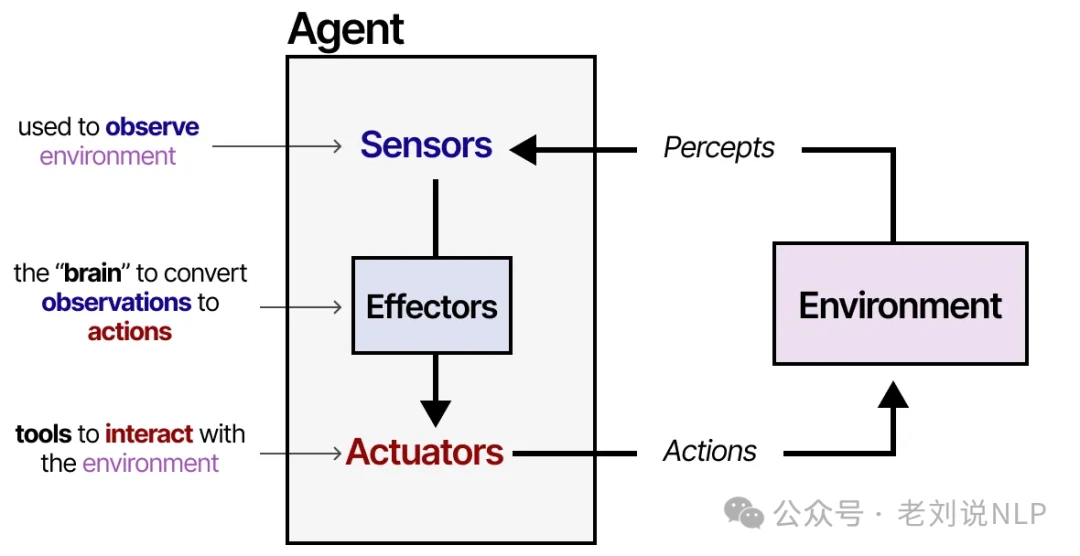
This model applies to everything from a robot navigating a factory floor to an AI assistant interacting with software. We can adapt this framework to fit our "Augmented LLM" and create a true LLM agent.
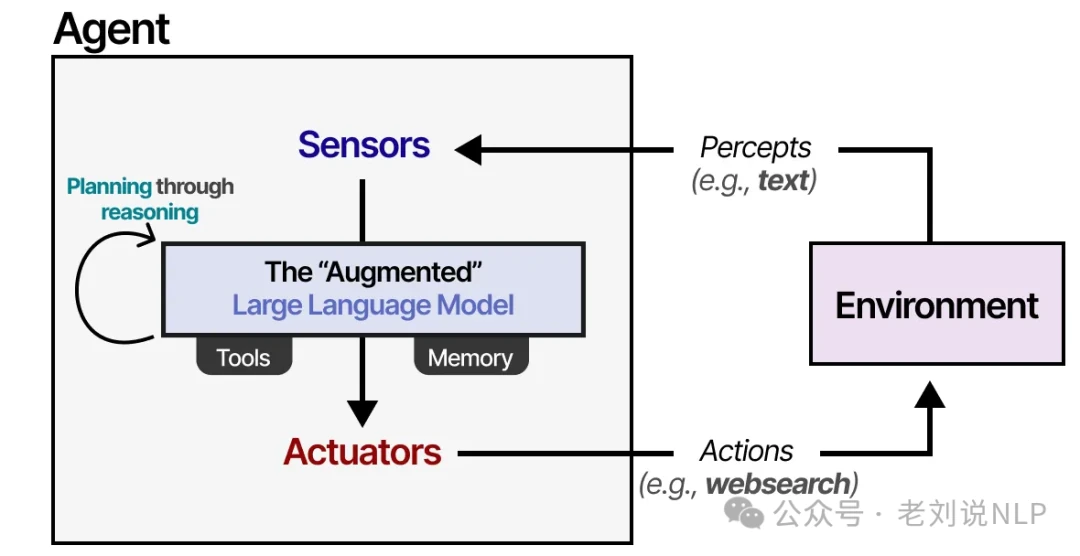
In this setup, the LLM agent observes its environment through text-based inputs and takes action using tools, like performing a web search. But how does it decide which action to take? This brings us to a crucial component of any LLM agent: planning. To plan effectively, the LLM needs to "reason" or "think" through a problem, often using techniques like Chain of Thought.
By leveraging this reasoning ability, the LLM agent can map out the sequence of actions required to complete a task.
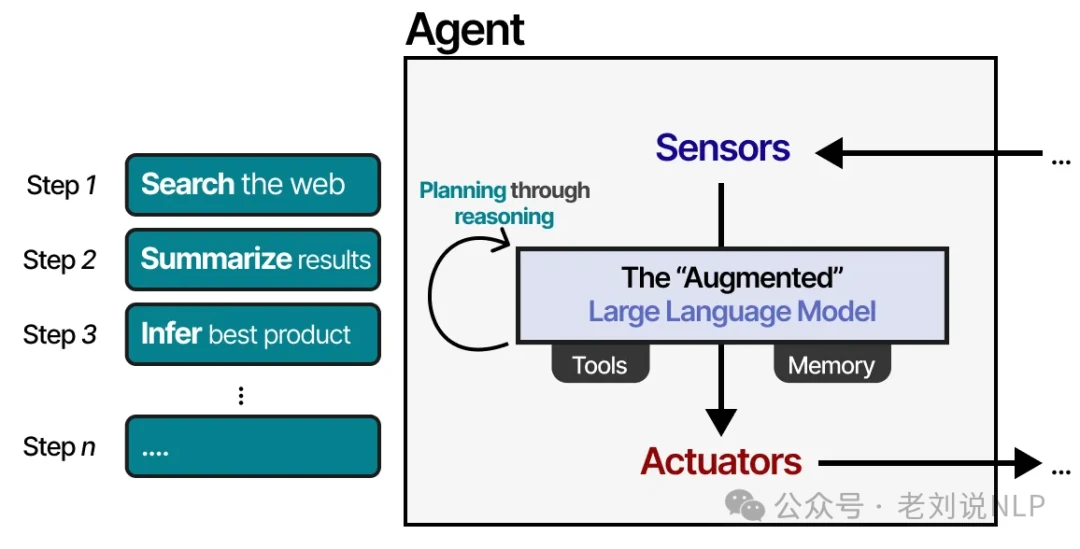
This entire process forms a loop: the agent perceives the situation (LLM), plans its next moves (Planning), executes them (Tools), and remembers the outcomes (Memory).
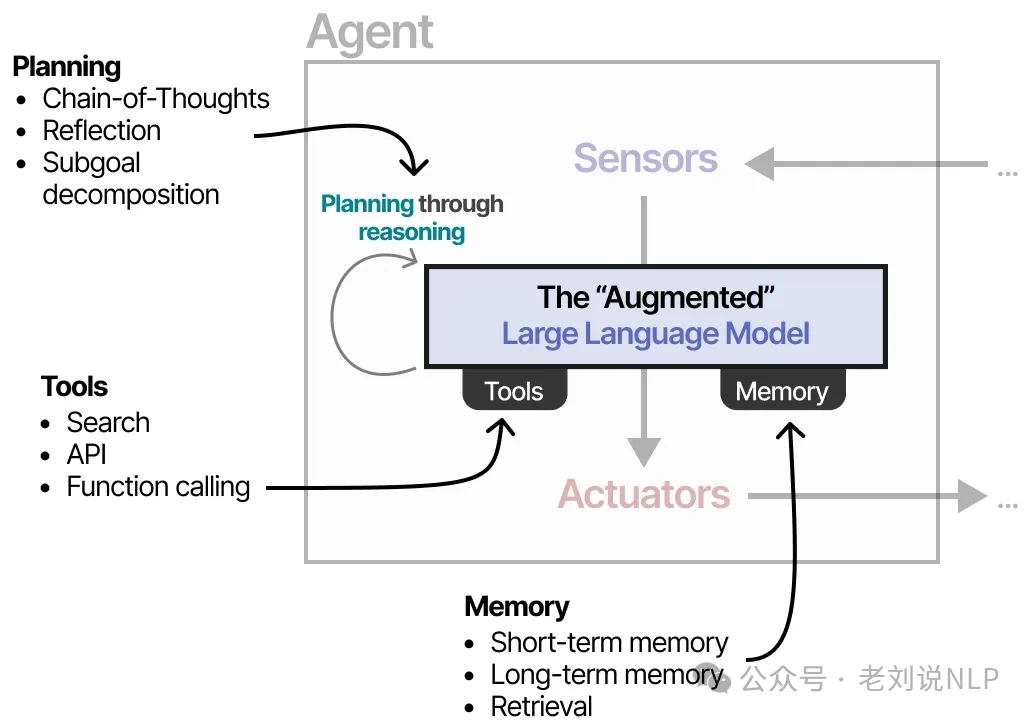
Different systems can grant LLM agents varying degrees of freedom. Generally, the more "agentic" a system is, the more autonomy the LLM has in deciding its own behavior.
Understanding LLM Agent Memory: Short-Term and Long-Term
The Challenge of Stateless LLMs
A critical point to understand is that LLMs are inherently stateless. They don't "remember" anything in the human sense. When you ask an LLM a question and then ask a follow-up, it has no memory of the first one without being explicitly reminded.
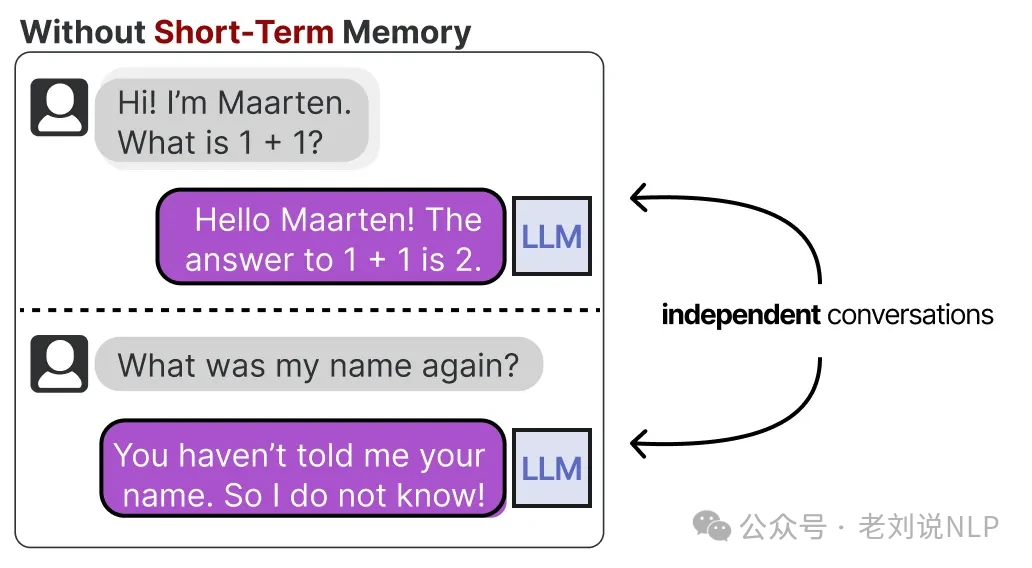
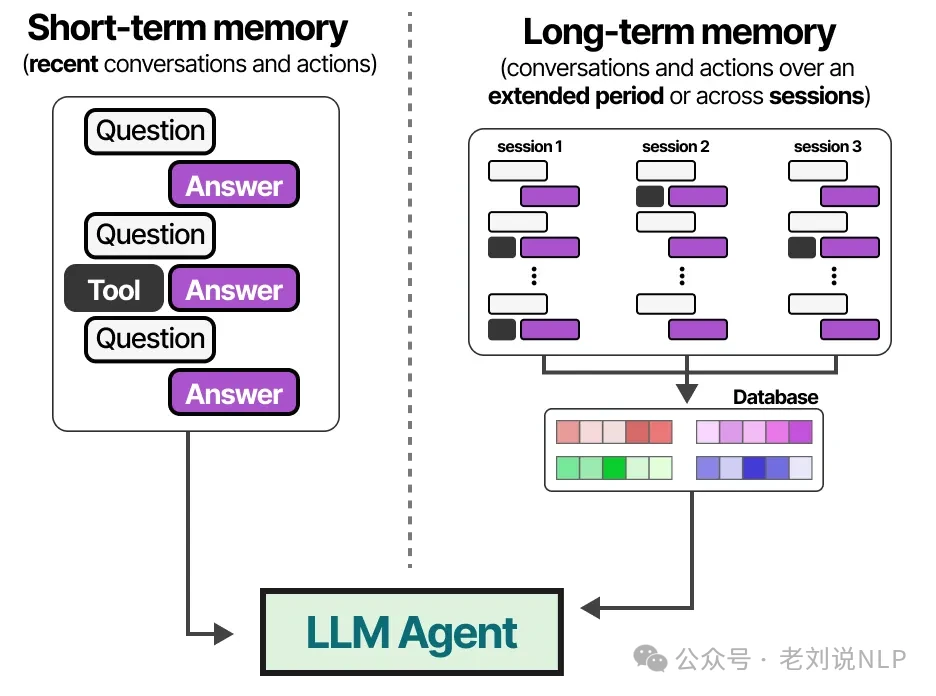
This immediate context is often called short-term memory or working memory. It acts as a scratchpad for the agent's most recent actions and observations. But what about tasks that require tracking dozens of steps? An LLM agent needs more than just a fleeting memory of what just happened.
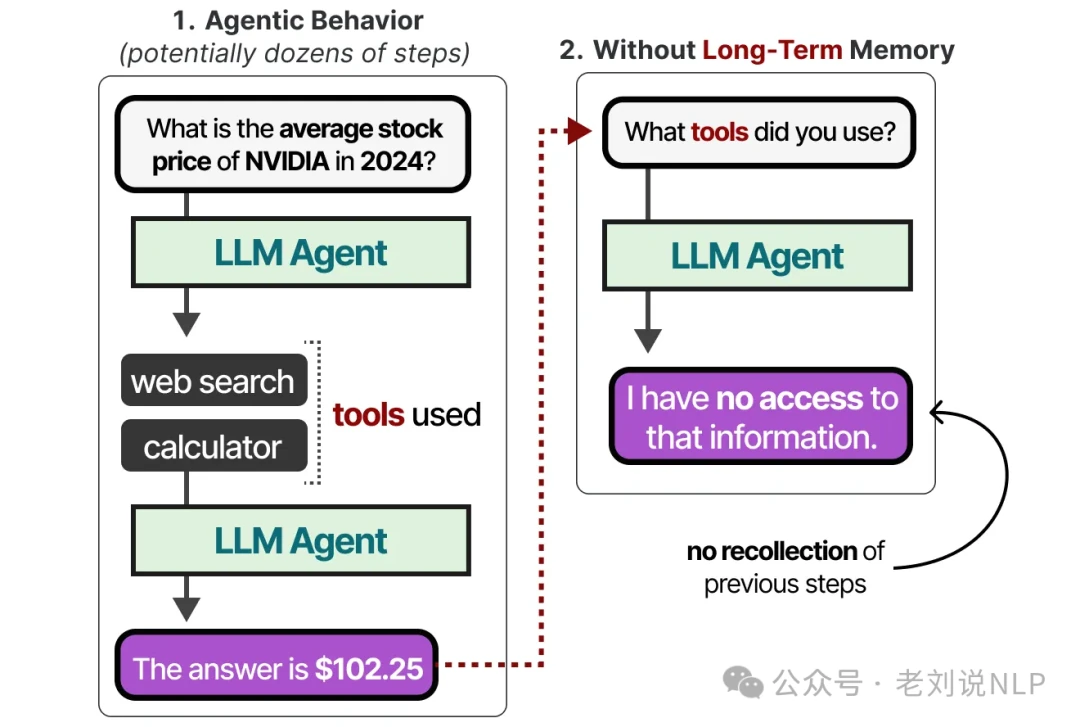
This is where long-term memory comes in, allowing an agent to recall information from potentially hundreds of previous steps.
Short-Term Memory and the Context Window
The simplest way to implement short-term memory is to use the model's context window—the maximum number of tokens an LLM can process at once.
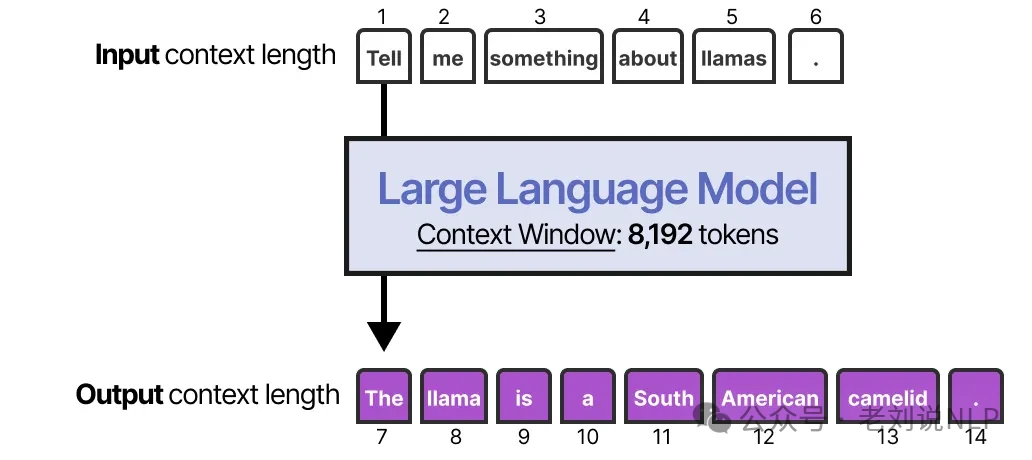
Modern context windows can handle anywhere from 8,192 to hundreds of thousands of tokens. A large context window allows you to feed the entire conversation history back to the model with every new prompt.
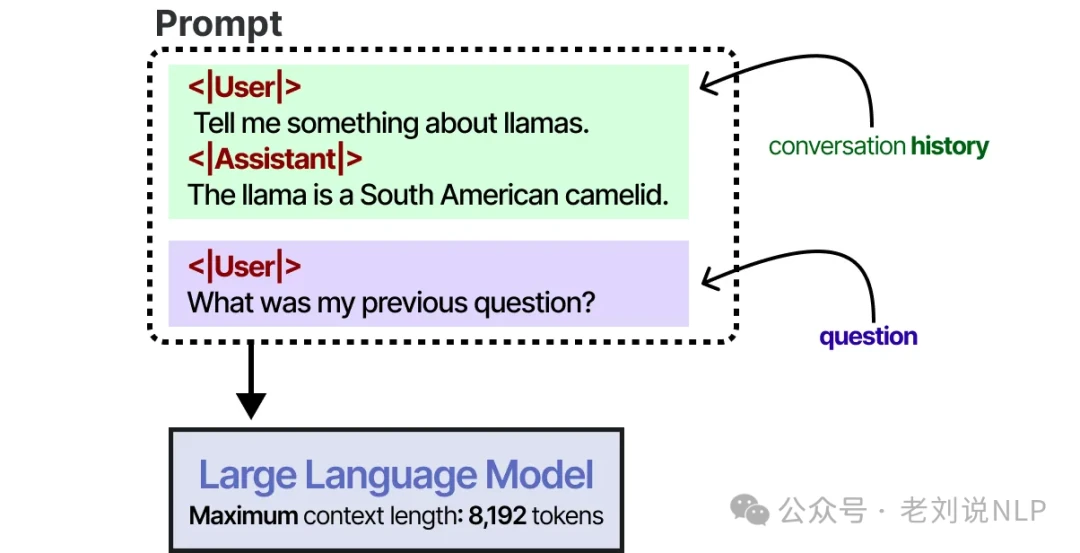
As long as the history fits, this works surprisingly well. But it's important to remember that the LLM isn't truly remembering the conversation; you're simply re-telling it what happened every single time. For models with smaller context windows or for very long conversations, another strategy is to use a separate LLM to summarize the dialogue as it progresses.
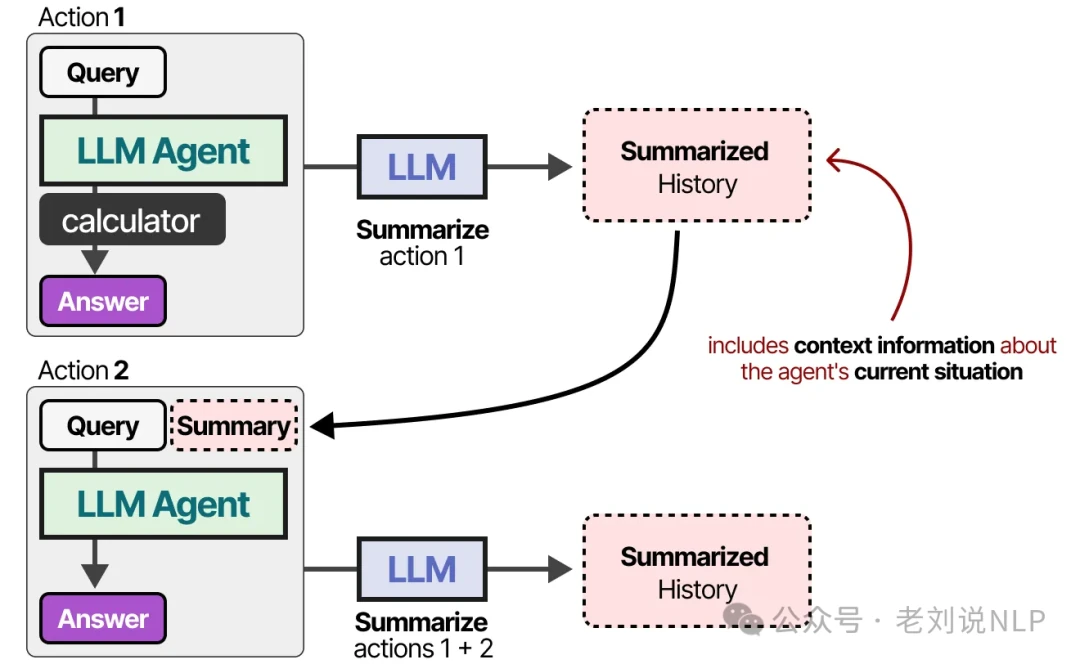
By continuously summarizing, you can keep the token count low while preserving the most critical information.
Long-Term Memory with Retrieval-Augmented Generation (RAG)
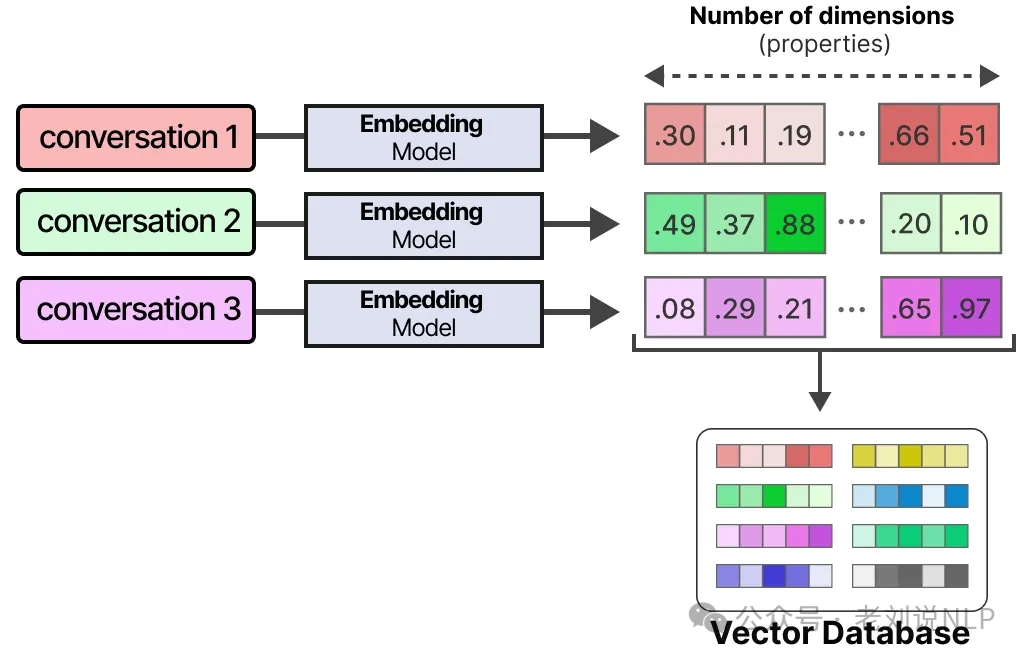
An LLM agent's long-term memory is designed to retain information over extended periods. A popular technique for this is to store all past interactions, actions, and conversations in an external vector database. To create this database, you first convert the text into numerical representations, or embeddings, that capture its semantic meaning.
Once the database is built, you can find the most relevant information for any new prompt by comparing the prompt's embedding to all the embeddings stored in the database.
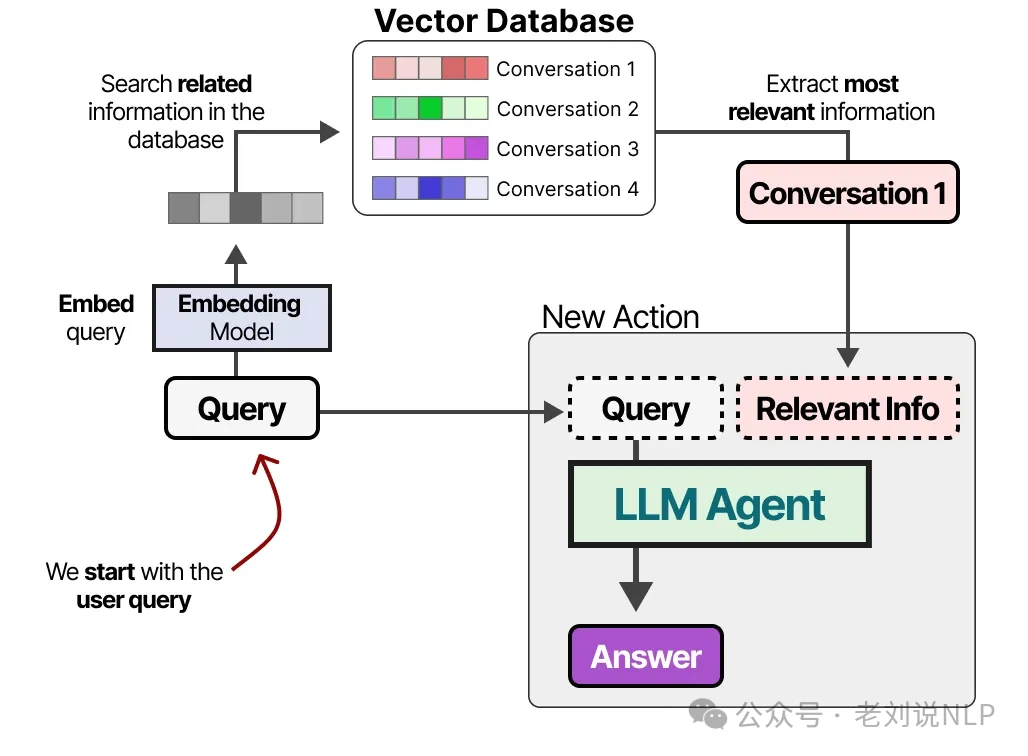
This powerful approach is known as Retrieval-Augmented Generation (RAG). Long-term memory can also persist across different sessions. To better organize this information, we can categorize memory into different types.

This distinction is useful in agent frameworks. For example, semantic memory (general world knowledge) might live in a different database than working memory (the current task's context).
Empowering Agents with Tools and Function Calling
Tools are what allow an LLM to break out of its text-only world and interact with external environments, whether that's a database, a piece of software, or a web API.

Broadly, tools serve two purposes: acquiring new information (like checking the latest news) and taking action (like scheduling a meeting or ordering a pizza).
How LLMs Use Tools: From APIs to Function Calling
To use a tool, the LLM must generate a text output that perfectly matches the tool's API. This is often a JSON-formatted string that can be easily parsed by a code interpreter.
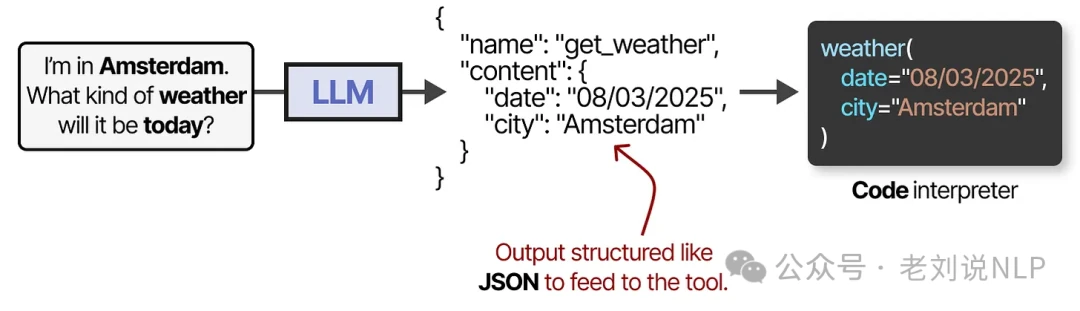
Note that this isn't limited to JSON; tools can also be called directly from code. You can also define custom functions for the LLM to use, such as a simple multiplication function. This is commonly known as function calling.
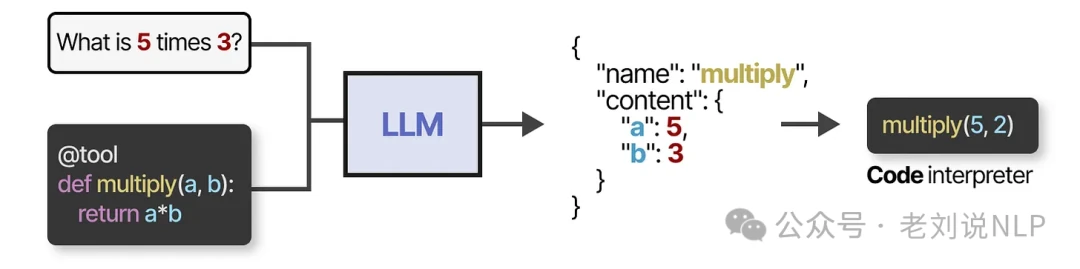
With the right prompting, many modern LLMs can learn to use a wide variety of tools right out of the box.
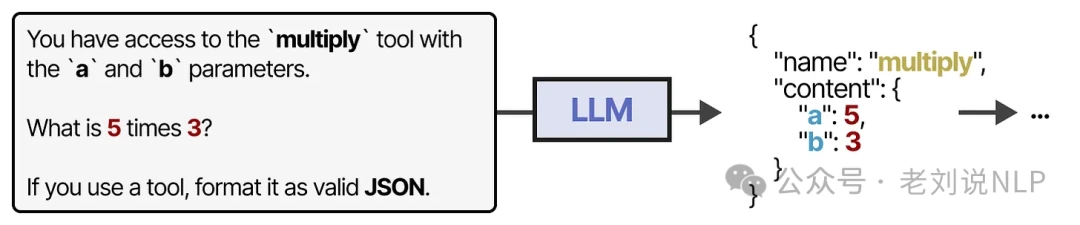
For more reliable and robust tool use, however, fine-tuning the LLM on specific tool-use examples is often the best approach. In a simple agent, tools might be used in a fixed, predefined sequence.
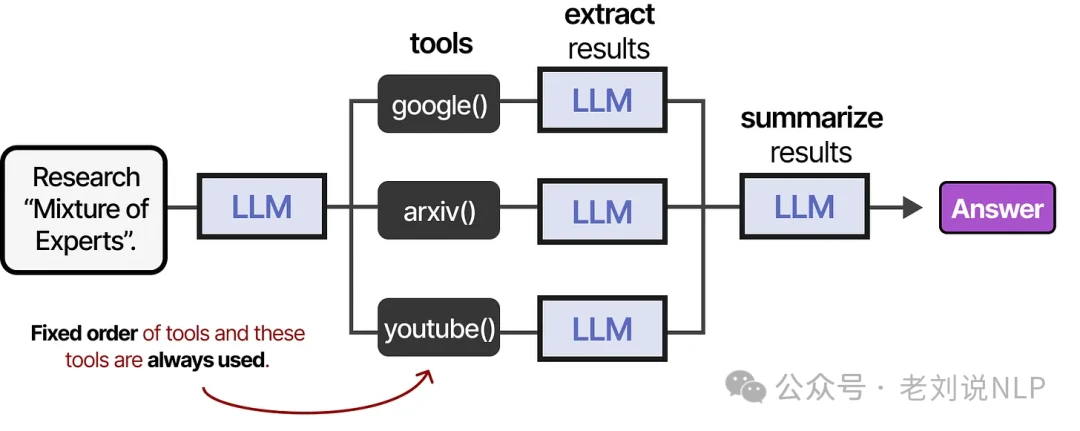
But a truly autonomous agent needs to decide for itself which tool to use and when. At its heart, an LLM agent is a loop of LLM calls, where the output of one step is fed back as the input for the next.
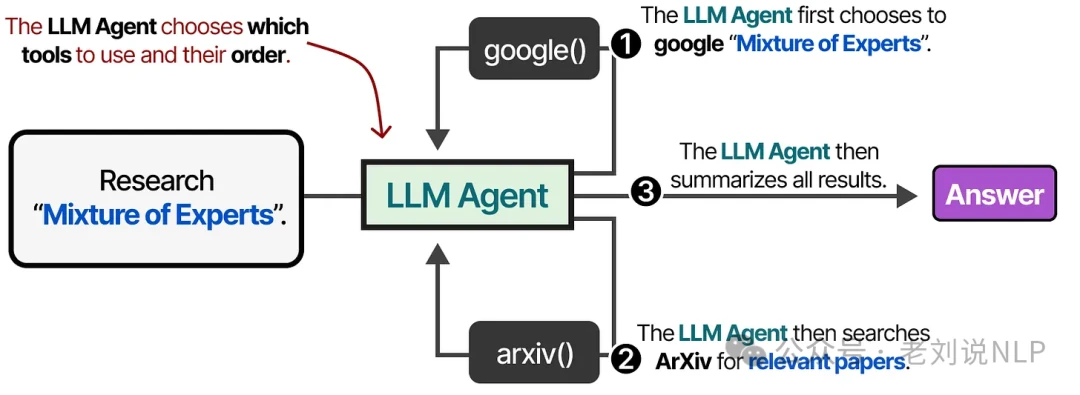
In other words, the agent continuously processes information, decides on an action, and observes the result, refining its approach with each cycle.
Mastering Tool Use with Toolformer
Because tools can so effectively compensate for an LLM's inherent weaknesses, research into tool learning has exploded in recent years.
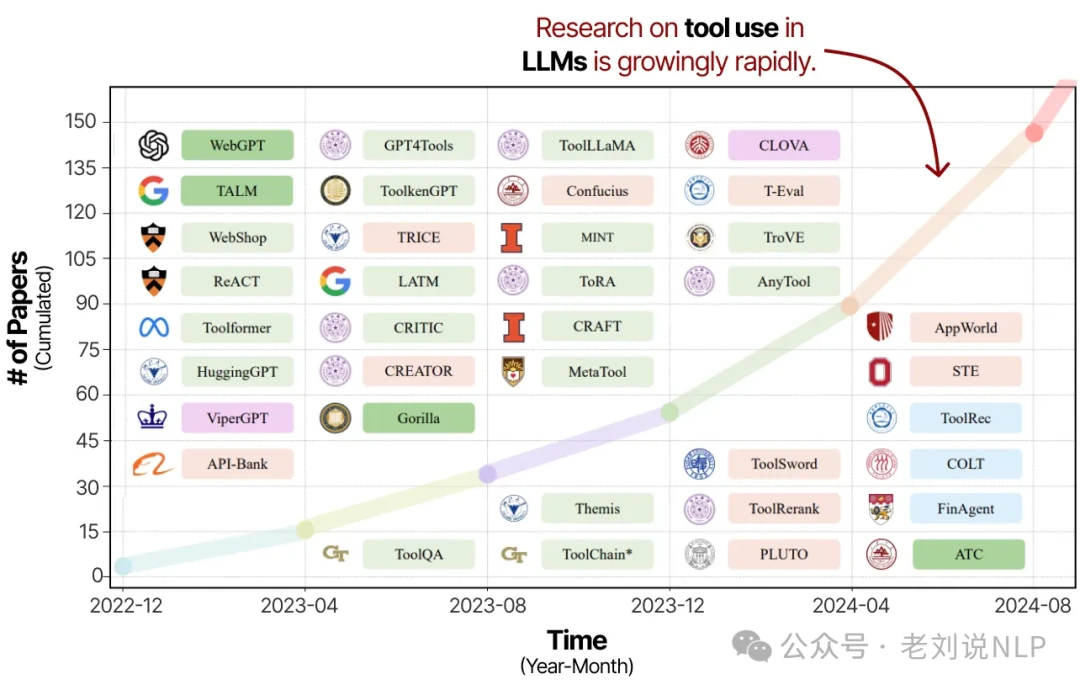
As detailed in the survey paper "Tool Learning with Large Language Models," this growing focus is making agentic LLMs more powerful than ever. One of the pioneering techniques in this area was Toolformer, a model trained to decide which APIs to call, when to call them, and what to pass to them.
It signals the start and end of a tool call using special [ and ] tokens. When given a prompt like, "What is 5 times 3?", it generates text until it produces the [ token.

It then continues generating the API call until it hits the → token, which tells the system to pause generation.

At this point, the tool is executed, and its output is inserted back into the text.
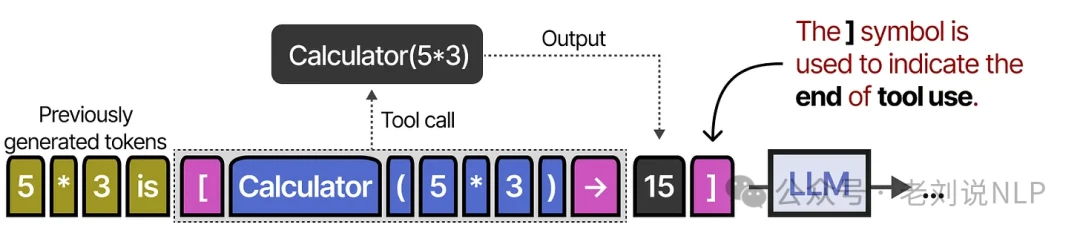
The closing ] token signals that the LLM can now resume generating its final answer. Toolformer learned this behavior by being trained on a carefully curated dataset filled with examples of tool use.
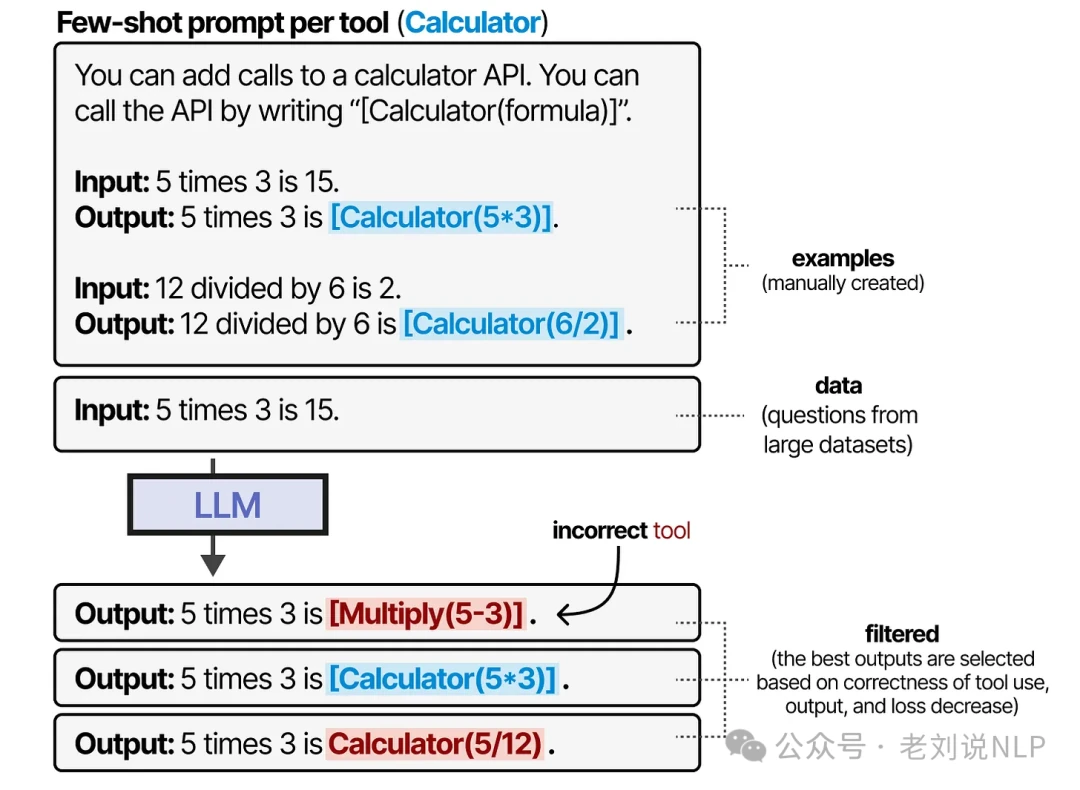
Since Toolformer, the field has advanced rapidly, with new models that can handle thousands of tools (ToolLLM) or intelligently retrieve the most relevant tool for a given task. It is now common practice for most LLMs to be trained to call tools by generating JSON.
Simplifying Tool Management with the Model Context Protocol (MCP)
Tools are a vital part of agent frameworks, but as the number of available tools grows, managing them can become a real headache. Each tool needs to be manually tracked, described to the LLM, and updated whenever its API changes.
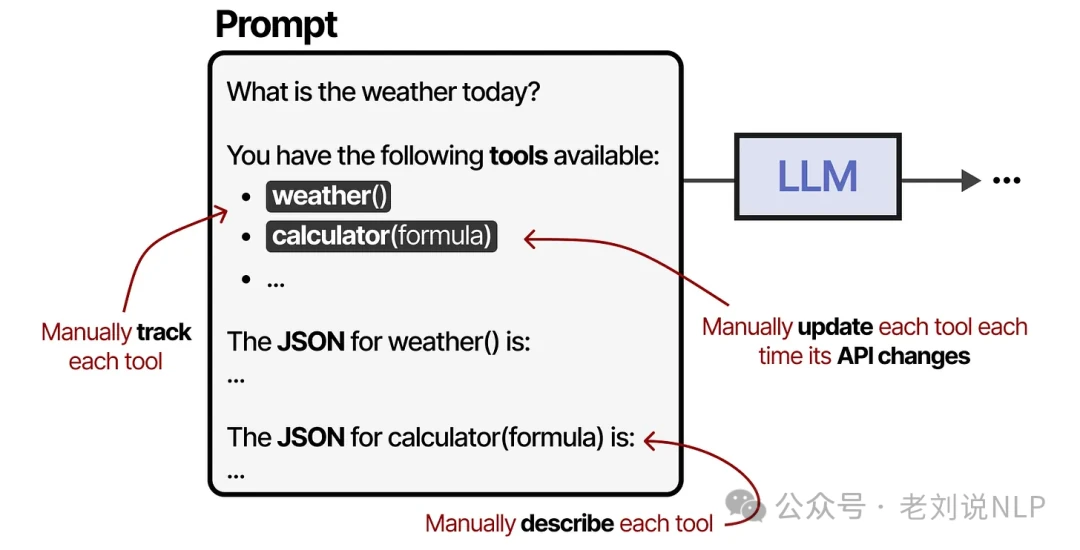
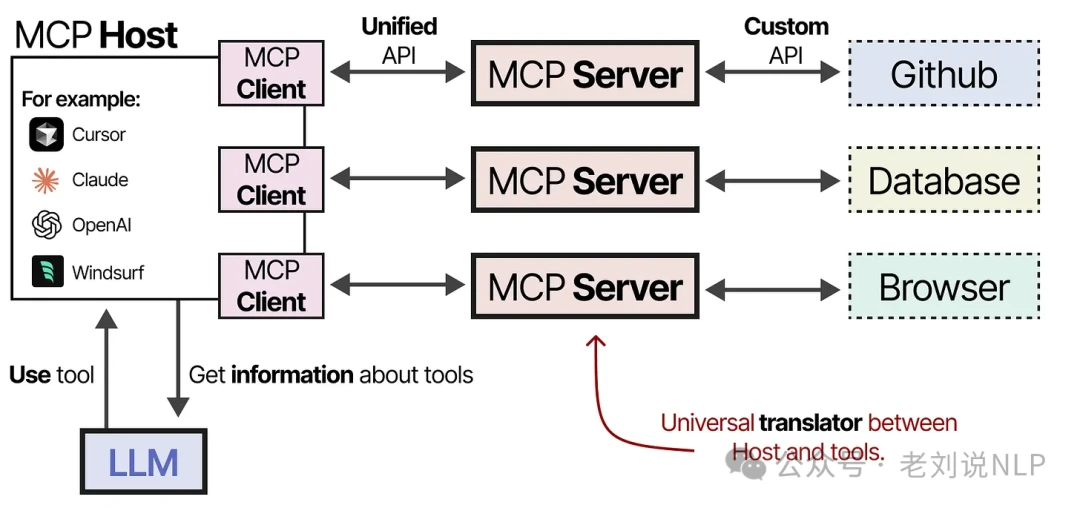
To streamline this process, Anthropic developed the Model Context Protocol (MCP), a standard for giving LLMs access to services like weather apps and GitHub. MCP has three main components:
- MCP Host: Manages the LLM application (e.g., an AI-powered code editor like Cursor).
- MCP Client: Maintains the connection between the Host and the Server.
- MCP Server: Provides the context and tools the LLM can use.
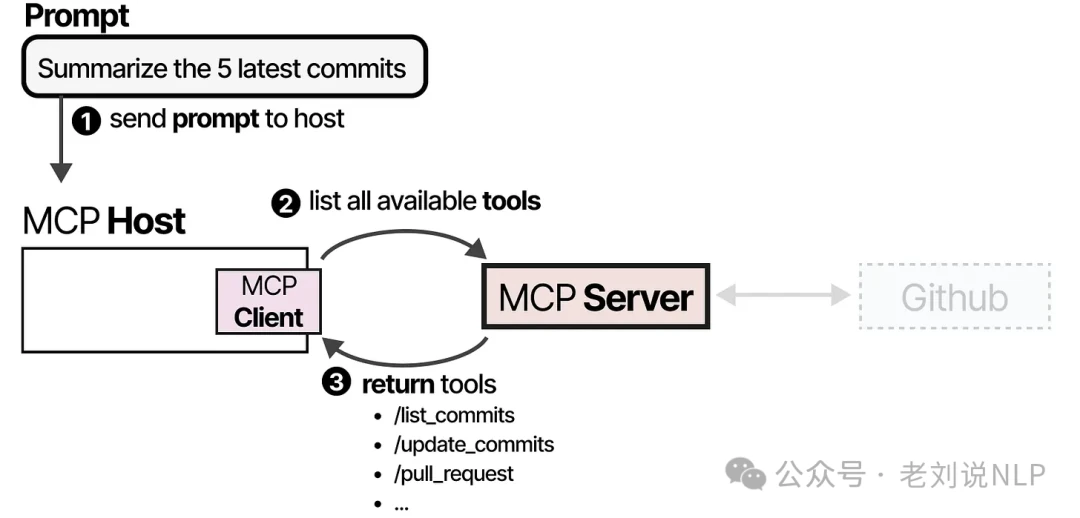
Let's say you want your LLM application to summarize the last five commits in a GitHub repository. First, the MCP Host and Client query the MCP Server to see what tools are available.
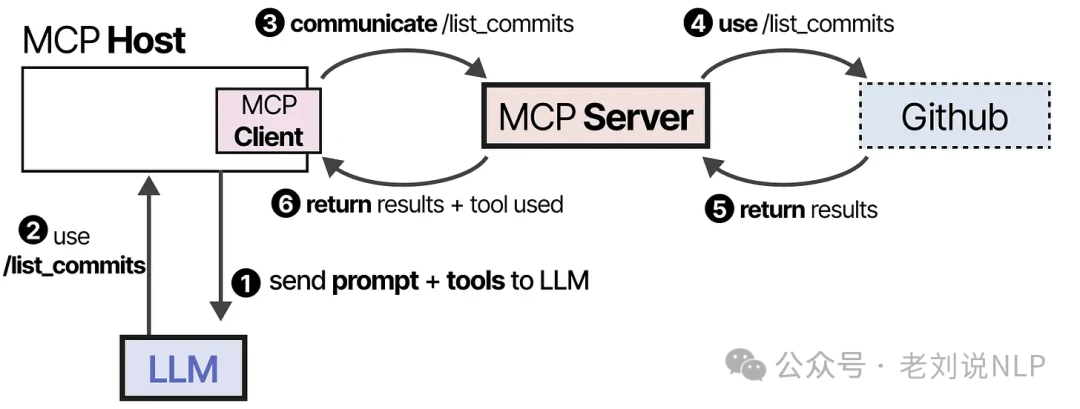
The LLM receives this list and decides to use a GitHub tool. It sends a request back through the Host to the MCP Server, which executes the tool and returns the result.
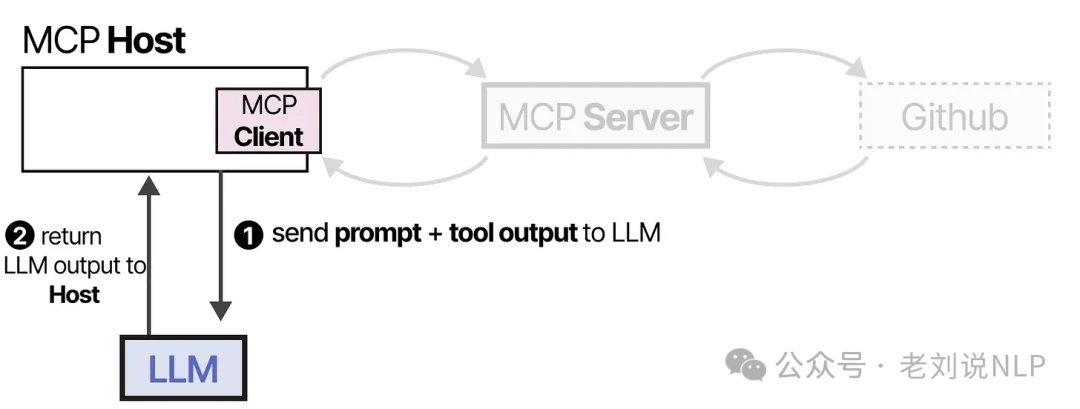
Finally, the LLM receives the tool's output and uses it to generate a summary for the user.
This framework simplifies tool creation immensely. If you build an MCP server for GitHub, any MCP-enabled LLM application can instantly connect to it and use its tools.
The Role of Planning and Reasoning in LLM Agents
Tools give LLMs powerful new capabilities. But how does an agent decide which tool to use and when? This is where planning comes in. In an LLM agent, planning is the process of breaking down a complex goal into a series of smaller, actionable steps.
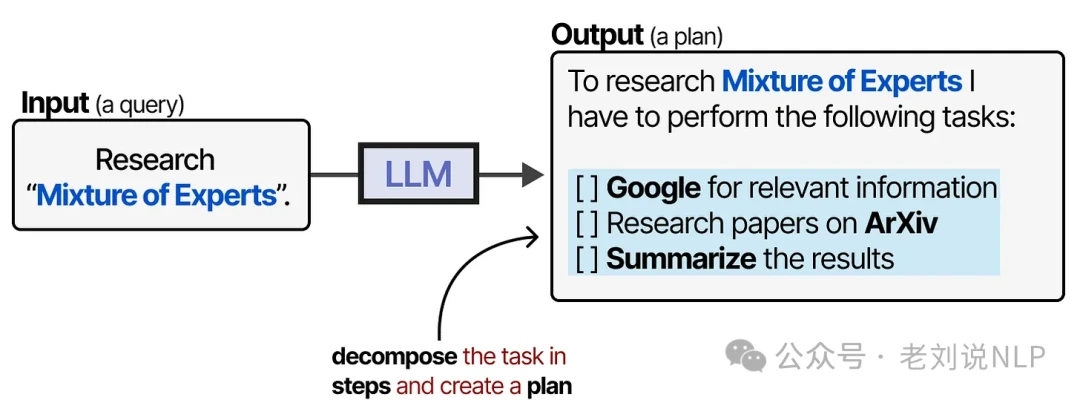
This allows the model to iteratively reflect on its progress and adjust its plan as needed.

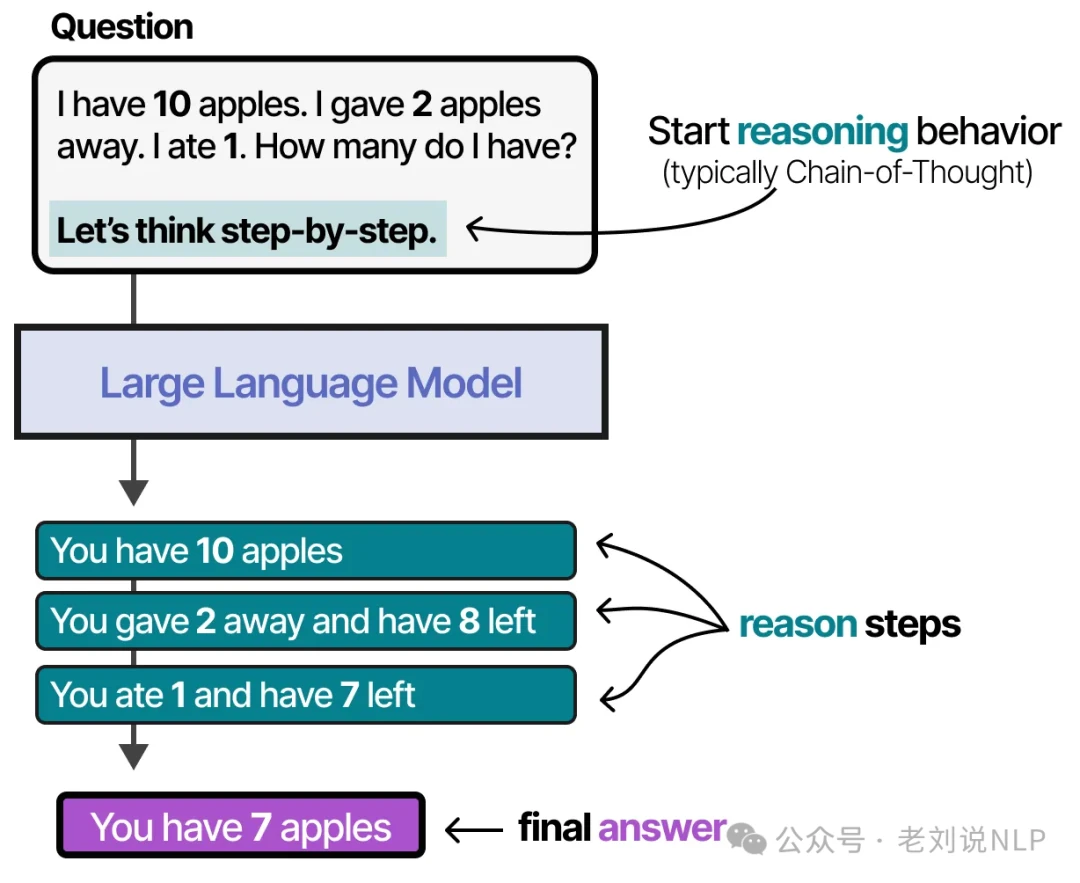
The Foundation of Planning: Reasoning with Chain of Thought
Before an LLM can plan, it must be able to "think" through a problem.
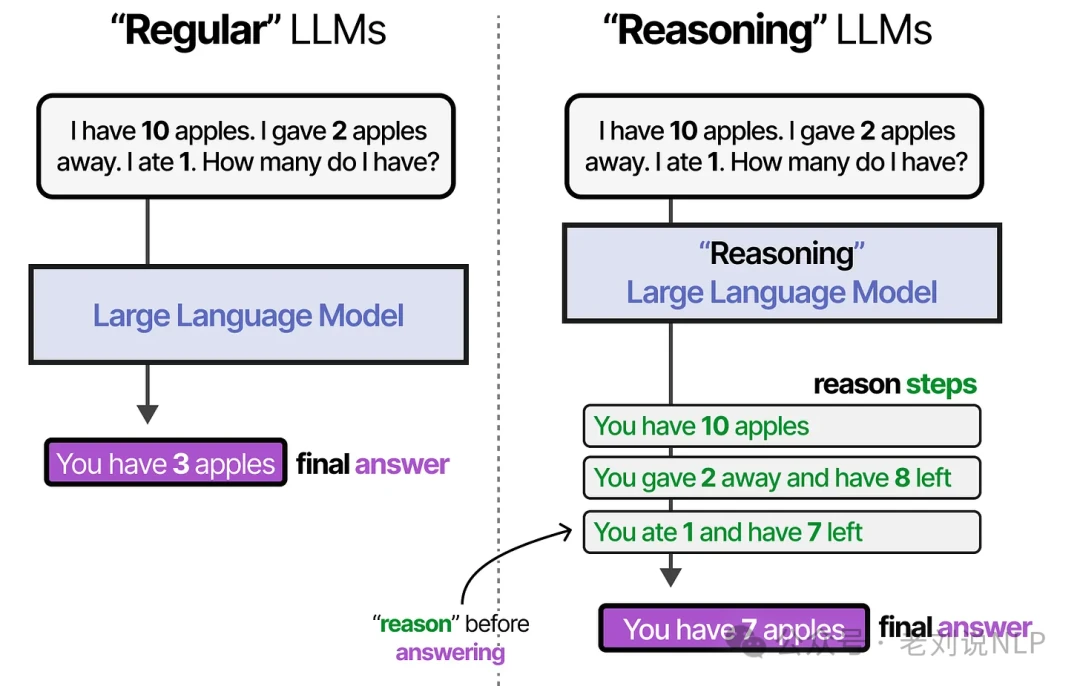
This reasoning behavior can be coaxed out of an LLM in two main ways: fine-tuning or clever prompt engineering. With prompt engineering, you can provide the LLM with examples of the reasoning process you want it to follow. This technique, known as few-shot prompting, is a powerful way to guide an LLM's behavior.
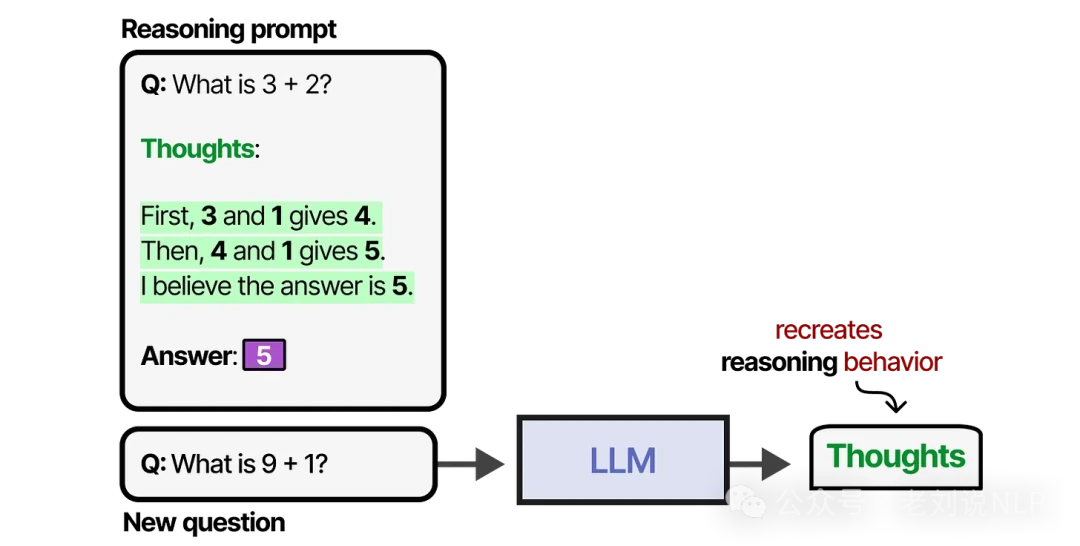
When these examples demonstrate a step-by-step thought process, it's called Chain of Thought (CoT) prompting, which unlocks more complex reasoning. You can even trigger Chain of Thought with a simple zero-shot prompt by just adding the phrase "Let's think step by step."

Alternatively, you can train an LLM on a large dataset of thought processes, or even use reinforcement learning to reward the model for demonstrating this behavior.
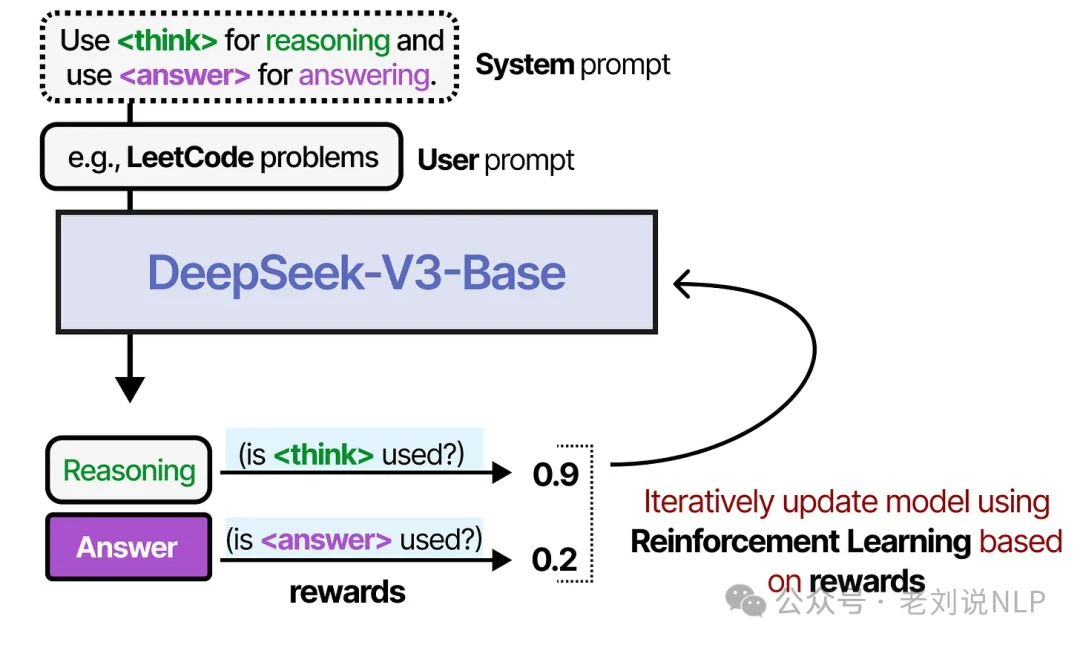
From Reasoning to Action: The ReAct Framework
Reasoning alone isn't enough. An agent needs to connect its thoughts to actions. One of the first techniques to bridge this gap was ReAct, which stands for "Reason and Act."

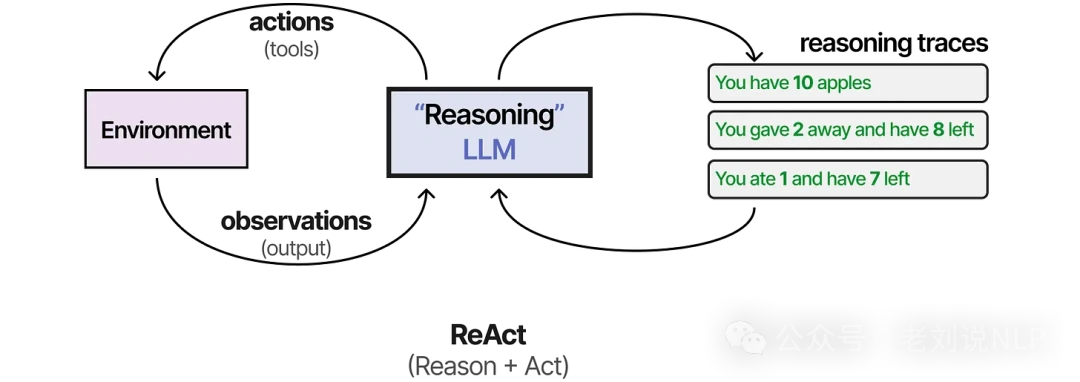
ReAct works by prompting the LLM to follow a specific three-step cycle:
- Thought: Reason about the current situation and what to do next.
- Action: Choose and execute an action (e.g., use a tool).
- Observation: Analyze the result of the action.
The prompt itself is quite straightforward:

Using this prompt as a guide, the LLM cycles through the Thought-Action-Observation loop.
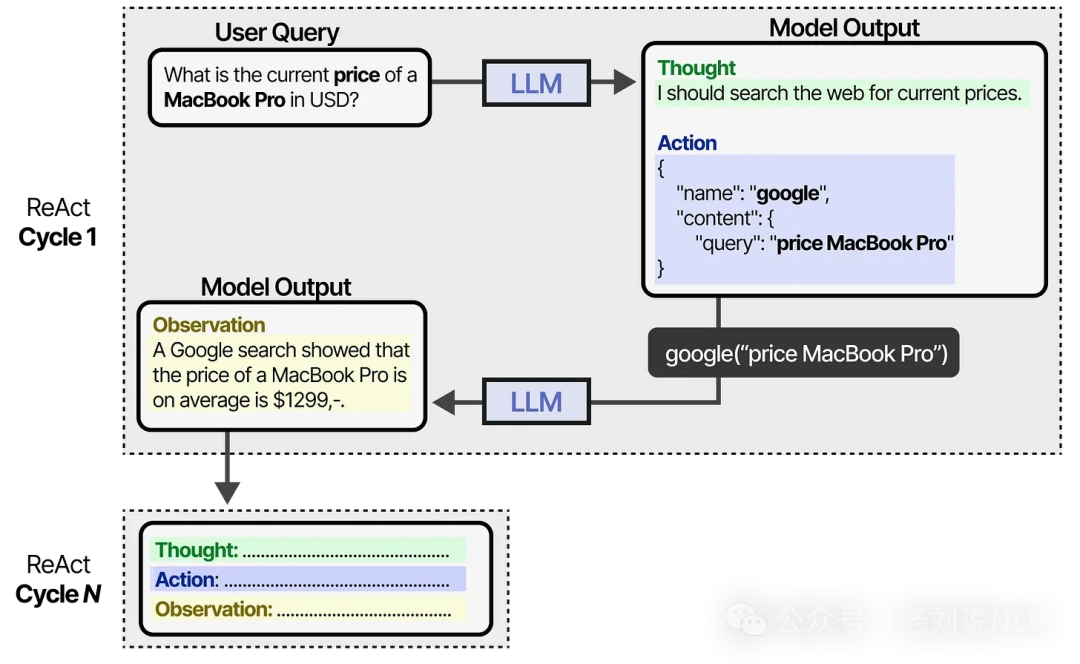
It continues this process until the Action step determines that the task is complete and it's time to return the final answer. This gives it far more autonomy than an agent following a fixed, predefined plan.
Learning from Mistakes: Reflection and Self-Refine
No one gets everything right on the first try—not even an LLM agent. This is the missing piece in ReAct, and it's where a technique called Reflection comes in. Reflection helps an agent learn from its past failures using verbal reinforcement.
The method involves three distinct LLM roles:
- Actor: Selects and executes actions, using a method like ReAct.
- Evaluator: Scores the quality of the Actor's output.
- Self-reflection: Analyzes the Actor's performance and the Evaluator's feedback to identify areas for improvement.
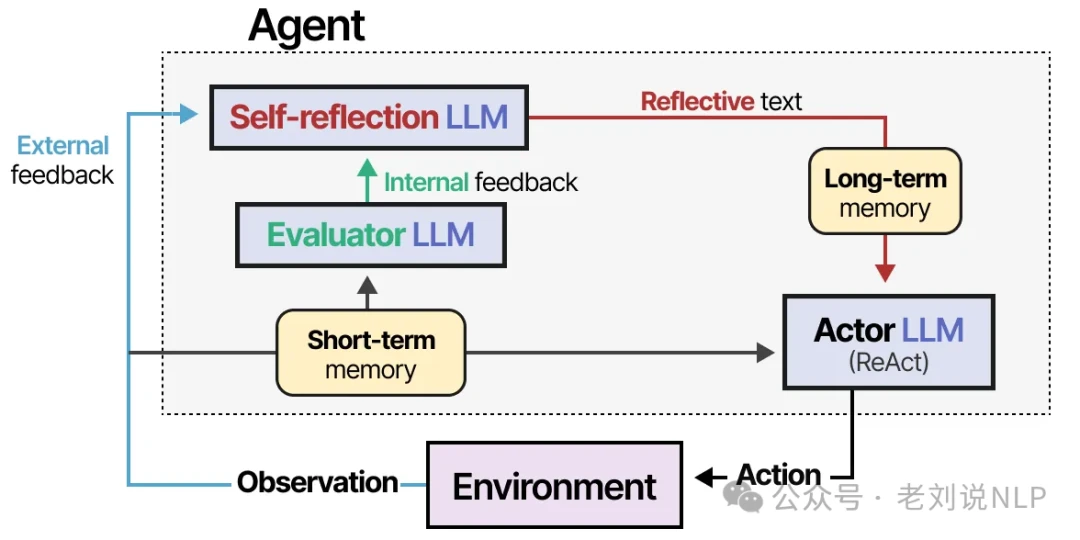
By adding a memory module to track actions (short-term) and reflections (long-term), the agent can learn from its mistakes over time.
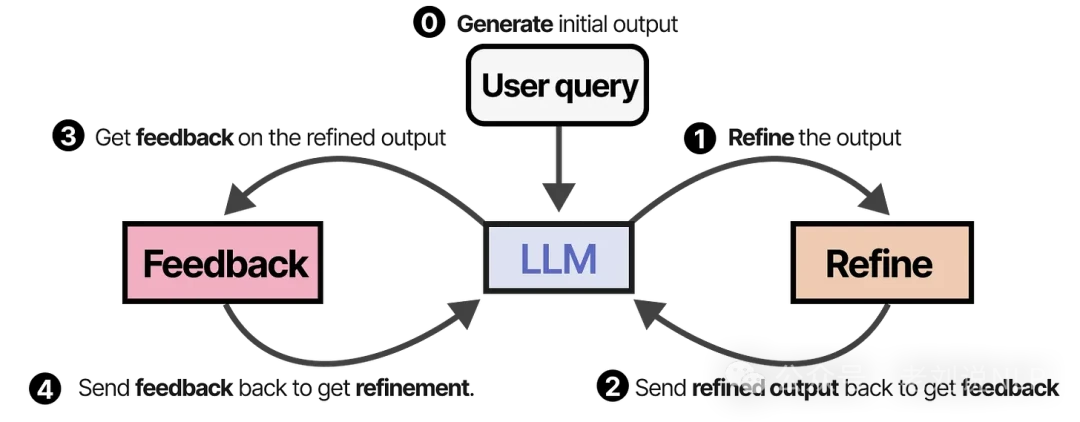
A similar and elegant technique is Self-Refine, where the agent iteratively generates an output, critiques it, and then refines it based on that feedback. The image below comes from the paper "SELF-REFINE: Iterative Refinement with Self-Feedback."
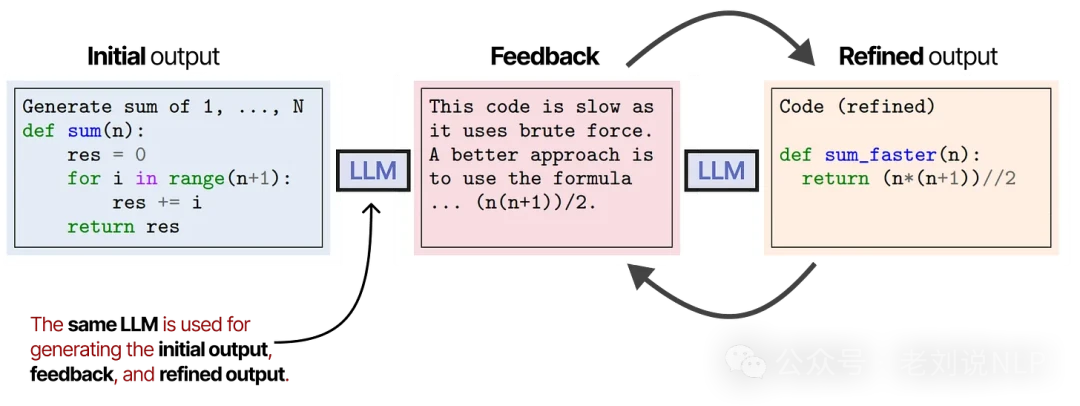
This self-reflection loop closely mirrors reinforcement learning, where an agent receives rewards based on the quality of its actions.
Beyond Single Agents: Exploring Multi-Agent Systems
While powerful, single-agent systems have their limits. A lone agent can become overwhelmed if it has too many tools to choose from, and some complex tasks simply require a team of specialists. This is where multi-agent systems come in. These are frameworks where multiple agents—each with its own tools, memory, and planning abilities—collaborate to solve a problem.
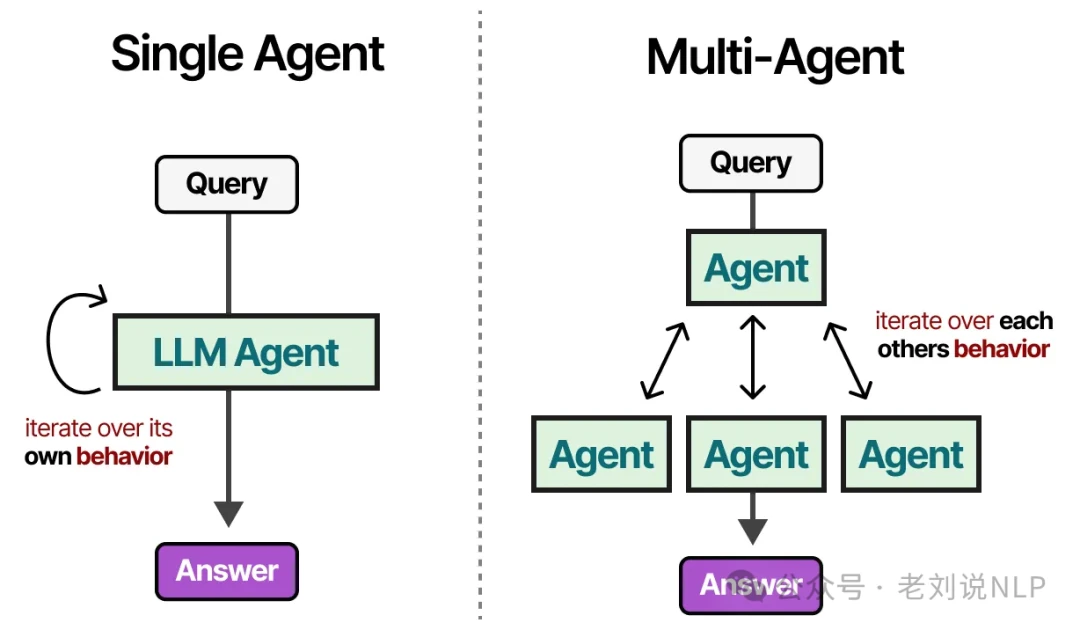
Why Use Multi-Agent Systems?
Multi-agent systems often resemble a team of human experts. You might have a supervisor or orchestrator agent that delegates tasks to specialized agents, each equipped with a unique set of tools.
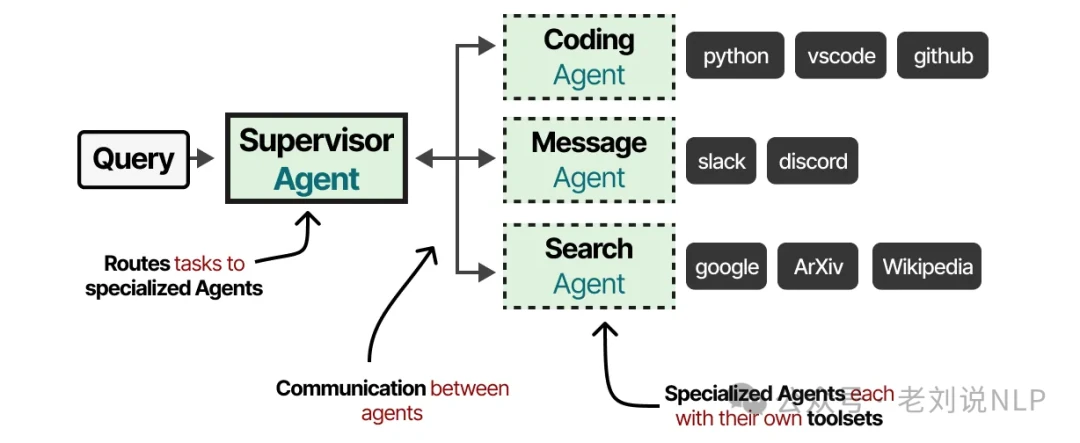
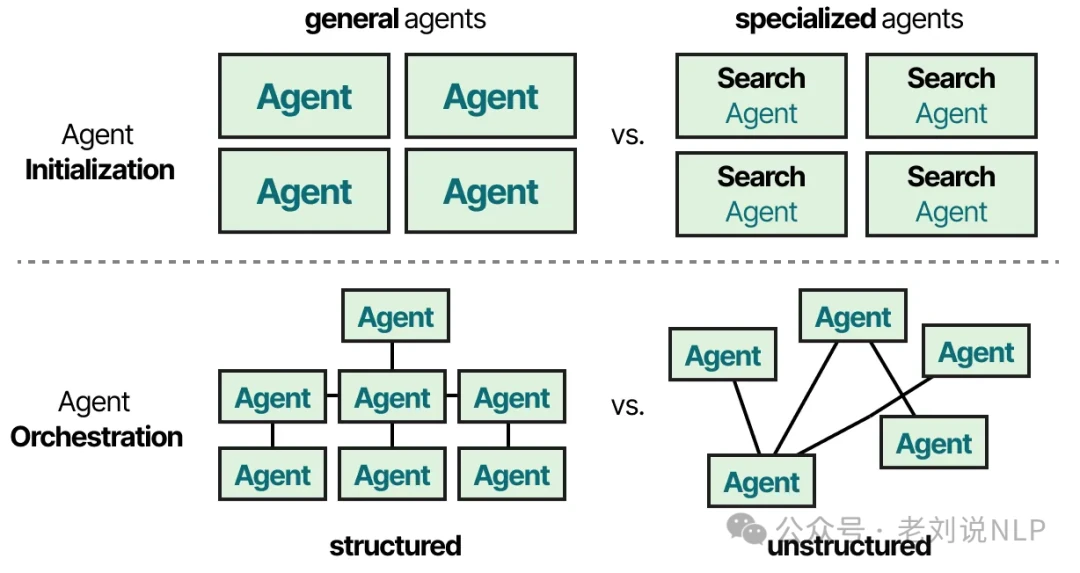
These agents might have different tools, different memory systems, or even be powered by different underlying LLMs. While there are dozens of multi-agent architectures, they all boil down to two core components:
- Agent Initialization: How are the individual agents created and defined?
- Agent Orchestration: How do the agents communicate and coordinate their work?
Case Study: Generative Agents in a Virtual Town
Arguably one of the most influential papers in this space is "Generative Agents: Interactive Simulacra of Human Behavior." The researchers created a virtual town populated by computational agents that simulate believable human behavior.
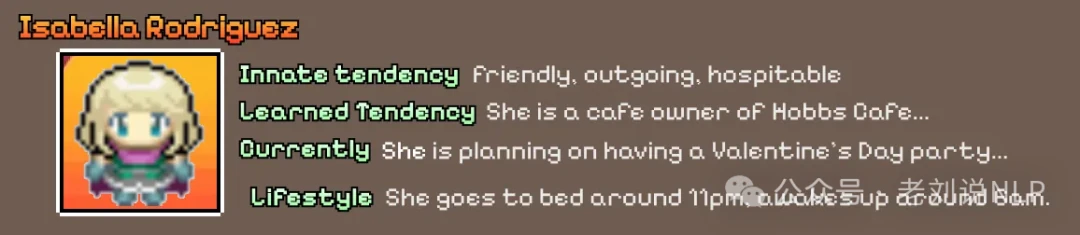
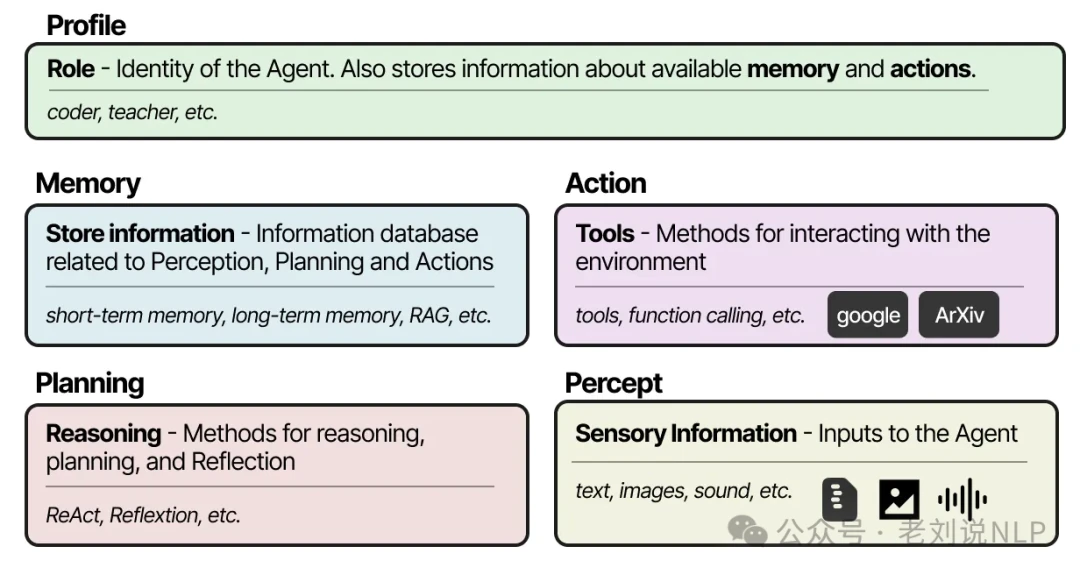
Each agent is given a unique profile, which influences its personality and behavior. The architecture for each agent is built on three modules we've already seen: Memory, Planning, and Reflection.
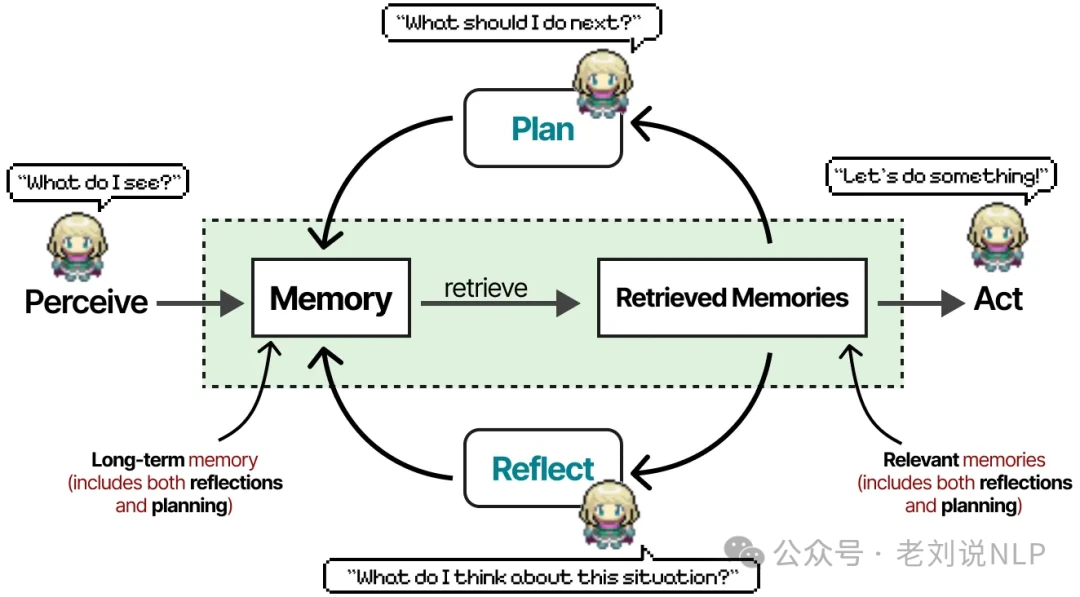
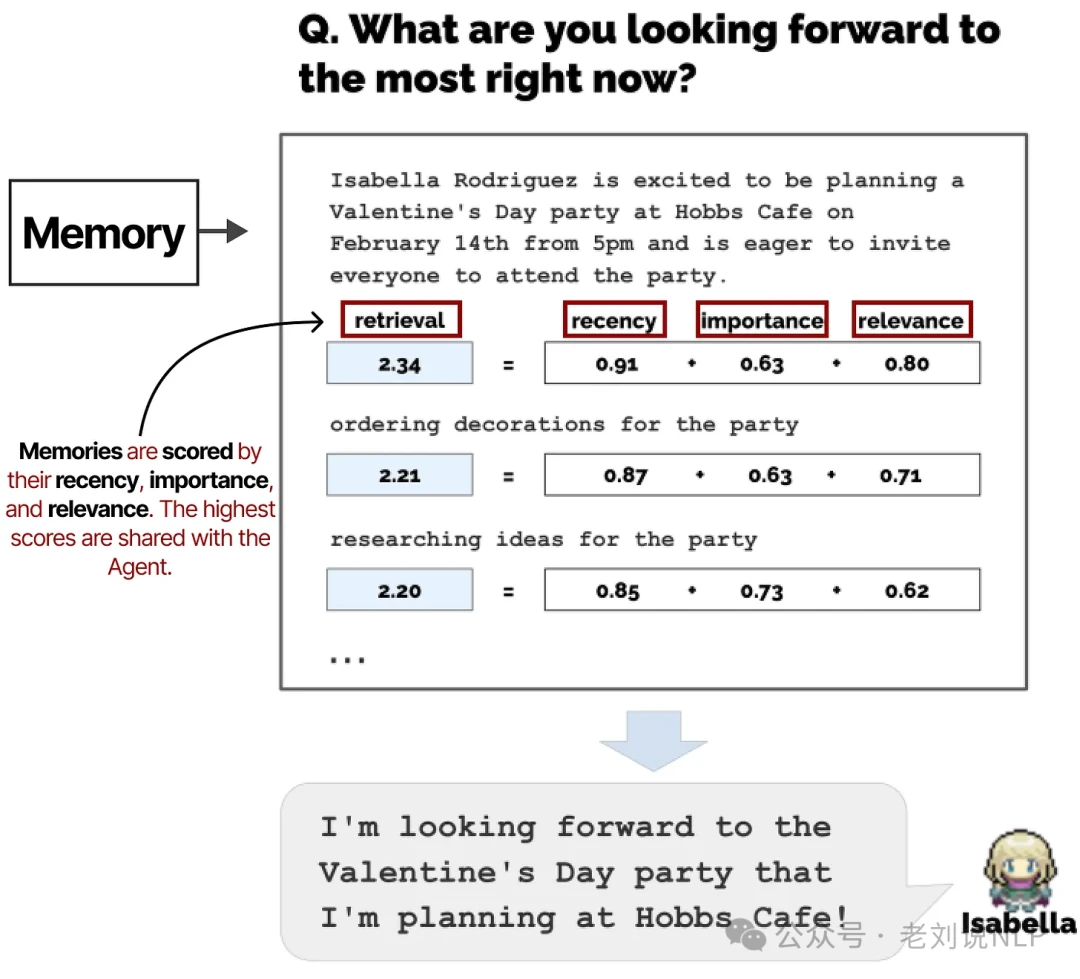
The memory module is the heart of this system. It stores a comprehensive log of every event, plan, and reflection the agent has ever had. When deciding its next action, the agent retrieves memories and scores them based on recency, importance, and relevance.
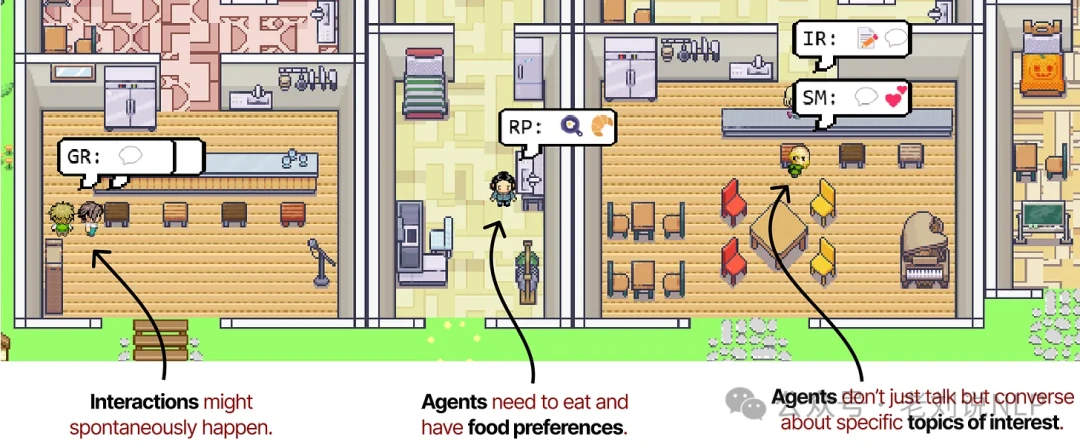
This architecture allows the agents to behave with a high degree of autonomy, interacting with each other and their environment without a central orchestrator directing their every move.
The researchers evaluated the system on the believability of the agents' behavior, as rated by human evaluators.
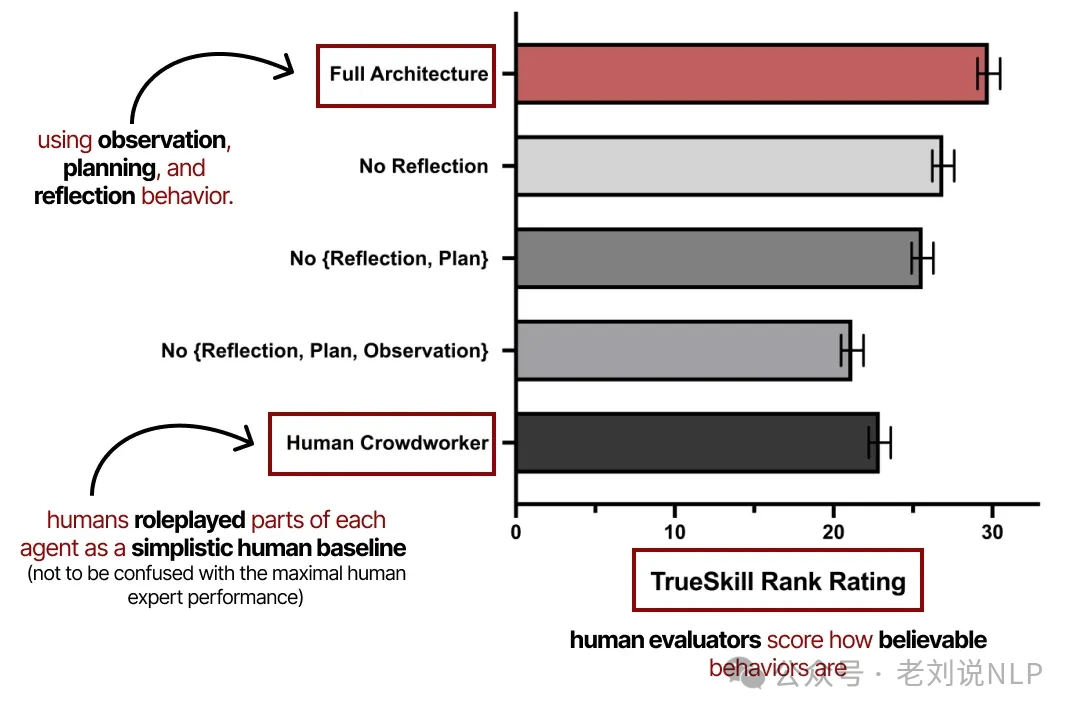
The results confirmed that observation, planning, and especially reflection are all critical for creating intelligent and believable agentic behavior.
Popular Multi-Agent Frameworks: AutoGen, MetaGPT, and CAMEL
Most multi-agent systems are built from the same fundamental building blocks: agent profiles, environmental perception, memory, planning, and a set of available actions.
Popular open-source frameworks for building these systems include AutoGen, MetaGPT, and CAMEL. Take CAMEL, for instance. A user defines a task and then creates two AI agents to solve it: an AI User, who guides the process, and an AI Assistant, who performs the work.

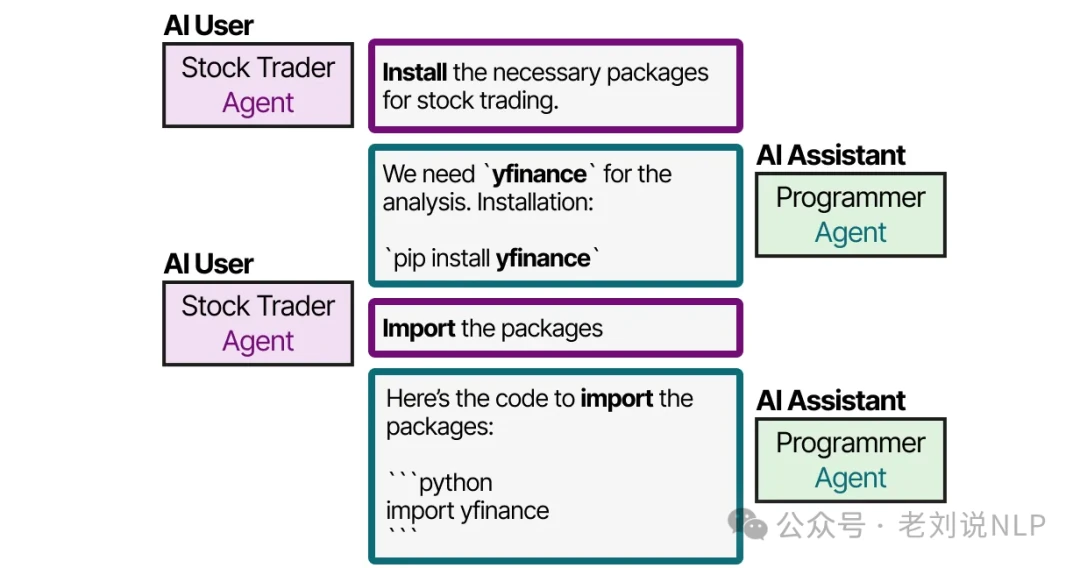
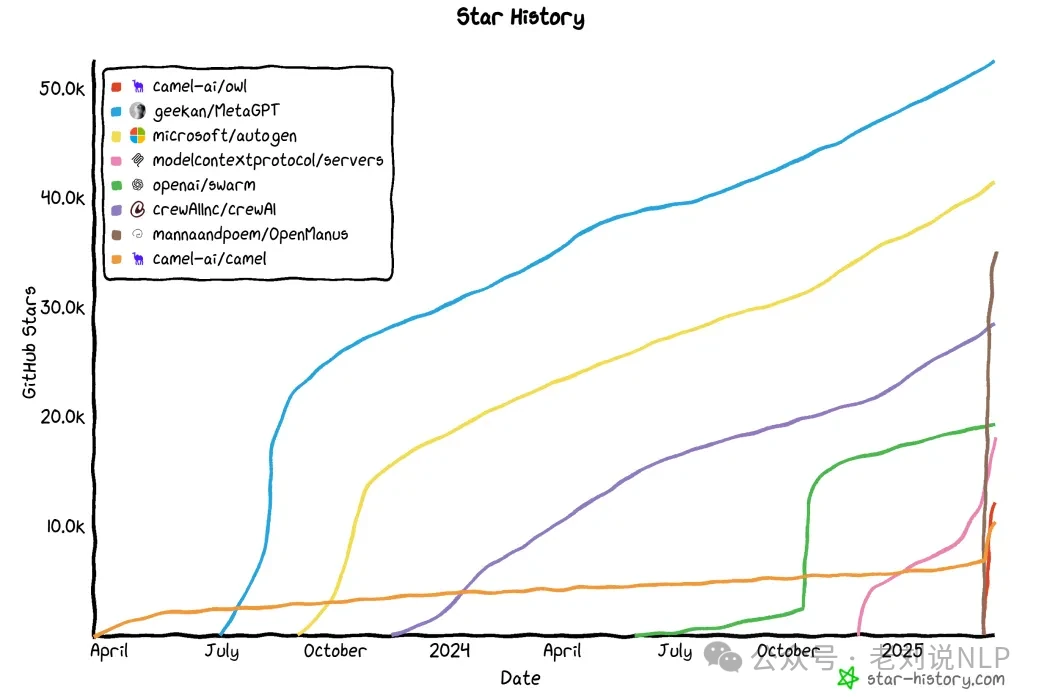
This role-playing dynamic creates a natural, collaborative dialogue between the agents. AutoGen and MetaGPT use different communication protocols, but they all rely on this core idea of collaborative communication. The development of these frameworks has been explosive over the past year.
Conclusion
From augmented LLMs to sophisticated multi-agent systems, the journey into agentic AI reveals a clear trajectory: away from simple text predictors and toward autonomous, goal-oriented systems. By combining the reasoning power of LLMs with memory, tools, and planning, we are building LLM agents capable of tackling increasingly complex challenges. As these architectures mature, they promise to redefine not just how we interact with AI, but the very nature of problem-solving itself.
Key Takeaways
• LLM agents are autonomous systems that utilize Large Language Models for decision-making.
• The architecture includes components like memory, tools, and planning mechanisms.
• Multi-agent systems, such as AutoGen, enhance collaboration among LLM agents.