What is DeepSeek-V3.2? AI Models for Advanced Reasoning
DeepSeek AI has launched the DeepSeek-V3.2 series, a new generation of AI models engineered for advanced reasoning and the development of sophisticated AI Agents. These "reasoning-first" models are designed to tackle complex problems and are available in two main variants: DeepSeek-V3.2 and the research-focused DeepSeek-V3.2-Speciale.
DeepSeek-V3.2 vs. V3.2-Speciale: Key Differences
The series offers two distinct models tailored for different use cases, from efficient production applications to cutting-edge research.
DeepSeek-V3.2: Efficient and Powerful
This model balances powerful reasoning capabilities with efficient output, making it ideal for applications like complex Q&A and general-purpose AI Agent tasks. Public reasoning benchmarks show DeepSeek-V3.2's performance is highly competitive with next-generation models, trailing only slightly behind Gemini-3.0-Pro. It is optimized for more concise outputs compared to models like Kimi-K2-Thinking, which helps reduce computational costs and latency.
DeepSeek-V3.2-Speciale: Pushing Research Boundaries
This research-grade model explores the upper limits of open-source AI capabilities. By integrating the advanced theorem-proving functions of DeepSeek-Math-V2, it delivers strong performance in instruction-following, mathematical proof, and logical verification. Its performance on mainstream reasoning benchmarks is comparable to Gemini-3.0-Pro.
To showcase its advanced reasoning, V3.2-Speciale has demonstrated high-level performance on problems from the International Mathematical Olympiad (IMO), Chinese Mathematical Olympiad (CMO), ICPC World Finals, and the International Olympiad in Informatics (IOI).
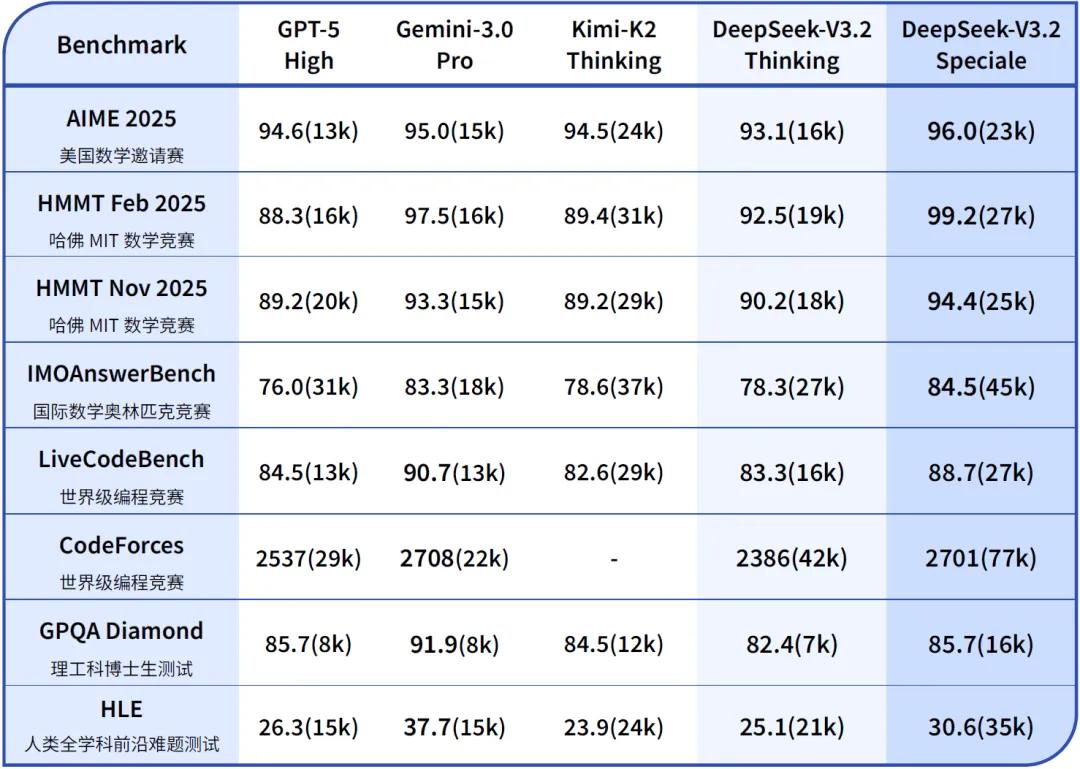
Table 1: Performance comparison of DeepSeek-V3.2 with other leading models on key benchmarks. Numbers in parentheses indicate the approximate total tokens consumed during evaluation.
Core Technical Innovations Behind DeepSeek-V3.2
The performance of the DeepSeek-V3.2 series is built on several key technical innovations that enhance its reasoning and efficiency.

DeepSeek Sparse Attention (DSA)
DeepSeek-V3.2 utilizes DeepSeek Sparse Attention (DSA), a novel attention mechanism designed to reduce computational complexity. This innovation enables the efficient processing of long contexts without significant performance degradation, a crucial feature for complex AI models.
Scalable Reinforcement Learning Framework
The models are fine-tuned using a highly scalable Reinforcement Learning (RL) framework. This approach leverages a robust training protocol and substantial computational resources to optimize the model's performance on complex reasoning tasks.
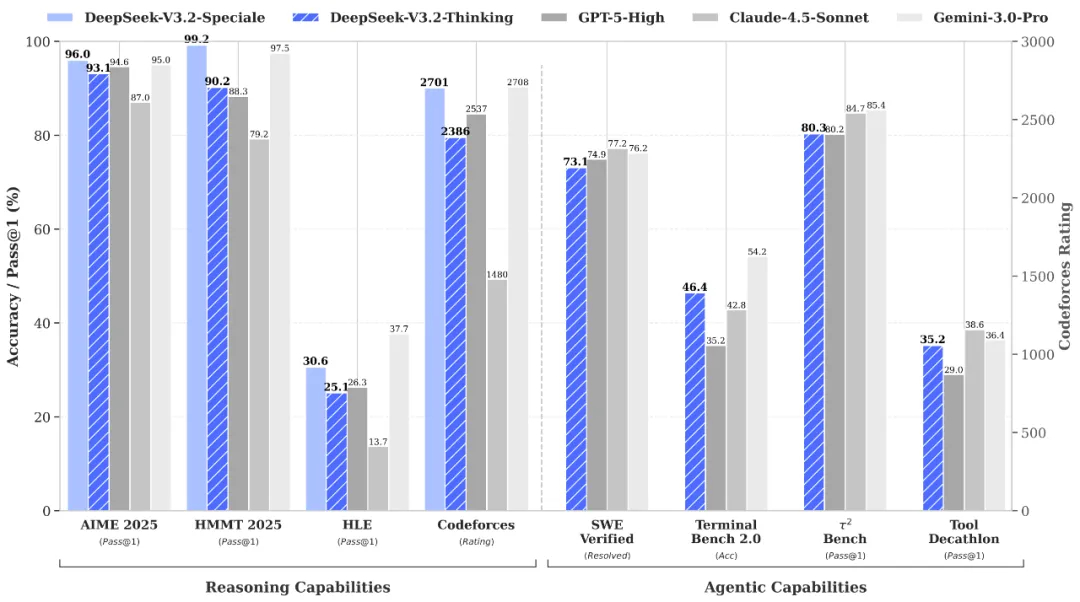
Advanced Agent Training Data Synthesis
A key part of training these AI Agents is a novel data synthesis pipeline. This system generates a large-scale dataset of "hard-to-solve, easy-to-verify" reinforcement learning tasks. Spanning over 1,800 environments and 85,000 complex instructions, this dataset fosters the model's generalization and instruction-following capabilities.
This method allows DeepSeek-V3.2 to integrate its "thinking" process into its tool-use framework, enabling it to operate in a deliberative (thinking) mode for complex problems or a direct (non-thinking) mode for faster responses.
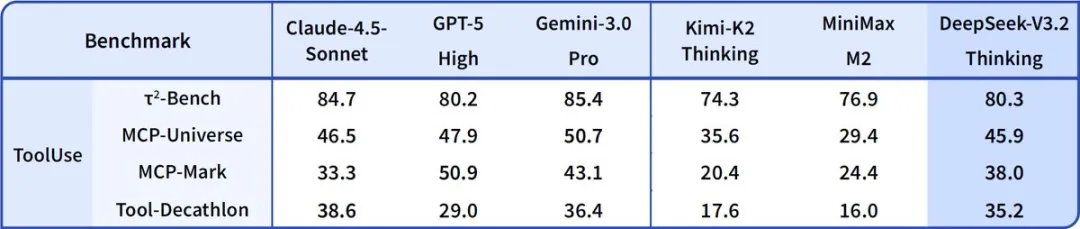
How to Use and Deploy DeepSeek-V3.2
The standard DeepSeek-V3.2 model is now live across the company's web interface, app, and API. The Speciale version is available as a limited-time preview via a dedicated API endpoint for research and development, with access provided by setting base_url="https://api.deepseek.com/v3.2_speciale_expires_on_20251215".
Getting Started with Local Deployment
For local deployment, the model architecture is identical to DeepSeek-V3.2-Exp. For optimal results, the suggested sampling parameters are temperature = 1.0 and top_p = 0.95.
Note for the Speciale Version: When performing a local deployment of the Speciale version, be aware that tool calling is not supported in the current release.
Key Takeaways
• DeepSeek-V3.2 models are designed for tackling complex reasoning problems effectively.
• Choose between DeepSeek-V3.2 for production and V3.2-Speciale for research applications.
• Explore the core innovations to enhance your AI Agent development process.