Repository: https://github.com/mit-han-lab/kernel-design-agents
Technical Report: docs/kernel_design_agents_technical_report.pdf
Team: HAN Lab Kernel Mafia
Kernel Design Agents (KDA) is now officially open-sourced. Designed for real-world GPU kernel optimization tasks like FlashInfer-Bench, KDA provides a reproducible agentic workflow: the Agent performs code understanding within a real repository, implements candidate kernels, aligns with benchmarks, analyzes Nsight Compute profiles, logs failed branches, and iterates over multiple rounds — ultimately producing a submission that passes official validation. Unlike traditional CUDA kernel template libraries or prompt pipelines, KDA's focus is not on one-shot code generation, but on placing the model within a long-term, auditable, evidence-driven engineering loop.
In this competition, the lead author (Dongyun Zou) and advisor (Ligeng Zhu) had limited CUDA experience: Dongyun had written fewer than 1k lines of Triton in 2026, and Ligeng had not written a single line of CUDA in 2026. Leveraging the KDA Agentic Workflow, HAN Lab Kernel Mafia achieved the following rankings in the Full-Agent Approach track of the MLSys-2026 NVIDIA Blackwell Kernel Competition:
| Track | Result |
|---|---|
| MoE Track | 1st place |
| DSA Track | 2nd place |
| GDN Track | 3rd place |
The speedups achieved by KDA relative to the official FlashInfer baseline are as follows:
- DSA Indexer: 19.0758x
- DSA Attention: 4.5425x
- GDN Prefill: 1.9158x
The significance of these results goes beyond the final speed numbers. KDA does not package hand-crafted kernels as Agent output; instead, it continuously drives the search under the constraints of planning, verification, knowledge retrieval, profile evidence, and long-term state logging. Every choice, rollback, and failure must be supported by benchmark and profile records. It is worth noting that among the five competition kernels, the submitted version surpassed the official FlashInfer baseline in three, while the remaining two were close to success but did not exceed the official baseline.

0x0. Why Not Just Let the Model Write Kernels Directly?
Over the past year, the ability of LLMs to generate CUDA/Triton kernels has been demonstrated by numerous demos. For operators with clear interfaces and localized objectives, it is not difficult for a model to produce a first runnable implementation. However, in competition and production environments, kernel optimization is not a one-shot code generation problem — it is a long-term experimental system problem. Candidate implementations must be repeatedly aligned with the official baseline, verified for correctness and latency across different workloads, dtypes, and shape regimes, and combined with Nsight Compute evidence to determine the next optimization direction.
What truly requires systematic management in this process is the engineering state: the current best version and the rationale for its selection, directions that have been tried and failed, consistency of benchmark configurations with the baseline, the primary bottlenecks revealed by profiling, and whether new PRs, source code, or profile records need to be consulted when consecutive iterations yield low returns. If this information relies solely on conversational context, the Agent is prone to goal drift, repeated attempts, premature claims of completion, or ineffective fine-tuning around local metrics. Once the task extends to ten or even forty-eight hours, human intervention becomes necessary for reminders, corrections, and redefining the next steps.
Therefore, the core question KDA addresses is not "Can the model write a kernel?" but rather "Can the model be organized into a long-term, auditable, evidence-driven engineering loop that allows it to continuously advance the kernel search under clear boundaries and acceptance criteria?"
0x1. What Does KDA Consist Of?
KDA decomposes long-term kernel search into three cooperating layers: the Humanize agentic loop, KernelWiki, and the ncu-report-skill. These three components correspond to task orchestration, external knowledge supply, and performance evidence analysis, together forming a closed loop from planning and implementation to verification and the next decision.
The Humanize agentic loop is the task control layer. It breaks kernel optimization into planning, execution, verification, and review. It requires the Agent to form an executable plan and acceptance criteria before each iteration, submit a change summary, test results, and next-step judgment after implementation, and then have an independent review check whether the conclusions hold. This layer addresses the problems of state maintenance and stopping conditions in long tasks. The Agent cannot decide that a task is complete based solely on the current conversational impression; it must precipitate candidate versions, experimental records, failure reasons, and review results into a traceable state.
KernelWiki is the knowledge retrieval layer. GPU kernel optimization heavily depends on architectural details and existing engineering experience, especially new features like Blackwell/B200, TMA, TMEM, warp specialization, tcgen05, and NVFP4. Relying solely on model parameter memory makes it difficult to stably invoke this knowledge in complex tasks. Therefore, KernelWiki organizes PRs, source code, baselines, documentation, and implementation experience from projects such as SGLang, vLLM, TensorRT-LLM, PyTorch, FlashInfer, DeepGEMM, and CUTLASS/CuTe into retrievable materials. When the Agent is optimizing a GEMM, it reads GEMM-related materials; when stuck on attention or sparse gather, it reads the corresponding topic; when consecutive rounds yield limited gains, it supplements new relevant sources rather than repeatedly trial-and-erroring in the same local area.
The ncu-report-skill is the performance evidence layer. It transforms Nsight Compute profiles into actionable analysis results, not merely comparing single latency numbers but also combining information such as throughput, stall hotspots, PM sampling timelines, and source-level evidence to determine the primary bottleneck. With this layer, the next optimization direction can be evidence-based: if the problem is memory latency, prioritize checking memory coalescing, cache behavior, and data reuse; if the problem is tensor pipe or occupancy, focus on tile shape, register pressure, CTA configuration, and instruction path.
Together, these three layers form the key differentiator of KDA from ordinary prompt collections: it does not cram more rules into a long prompt, but instead decomposes the goals, memory, materials, and evidence required for long-term kernel engineering into reusable components, making the Agent's search process sustainable, reviewable, and reproducible.
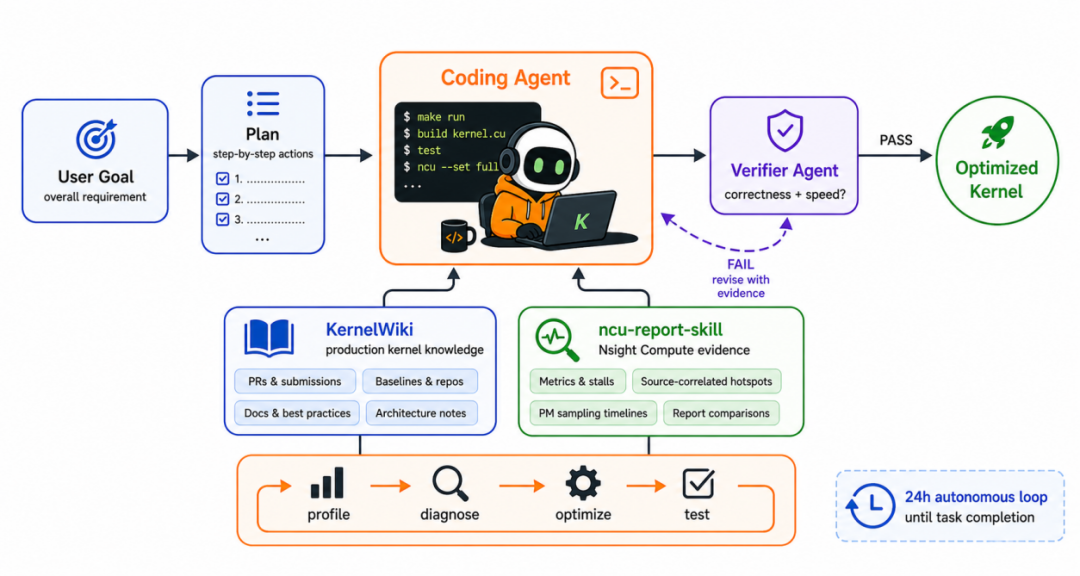
0x2. How Does the Agent Optimize a Kernel Step by Step?
The open-sourced prompts of KDA adopt a three-stage workflow. Each stage has clear objectives, input materials, acceptance criteria, and intermediate artifacts to be produced, preventing the Agent from repeatedly trial-and-erroring around a vague instruction like "optimize the kernel."
- Stage 1: Establish a correctness-first baseline candidate, first confirming that the candidate implementation can pass the official workload and validation logic.
- Stage 2: Perform structural optimization around the primary bottleneck.
- Stage 3: Analyze the complete workload distribution to determine whether shape-specialized dispatch is needed — i.e., having different shapes go through different kernels or different configurations.
This is especially important for tasks like FlashInfer-Bench. Real serving traces often do not consist of a single fixed shape; a kernel with average performance may not cover all regimes. In some scenarios, a hybrid dispatcher that can identify shape distributions and route accordingly is more robust than a single general-purpose implementation.
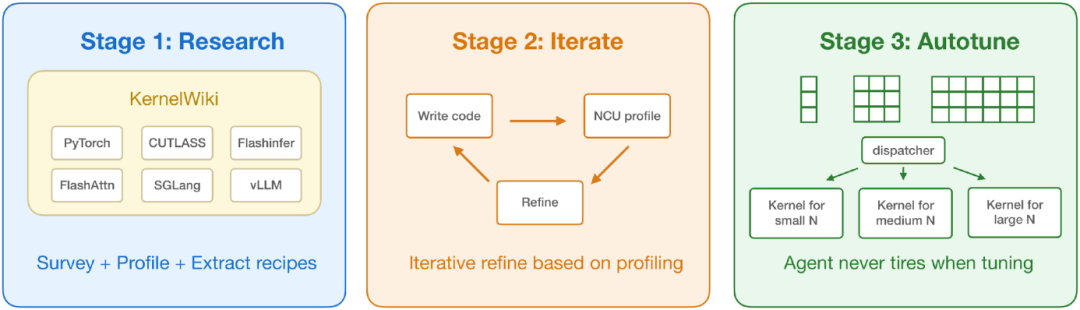
Each stage requires the Agent to leave auditable engineering artifacts: write an implementation plan draft explaining the candidate direction, risks, and verification method; refine the plan into executable steps and acceptance criteria via Humanize; record benchmark results and align them with the baseline under the same runtime environment; maintain a candidate DAG that preserves version relationships, selection rationale, and rollback justification; save NCU profiles to translate performance bottlenecks into actionable suggestions for the next step; and provide evidence to continue, modify, or abandon each major optimization direction. Therefore, this prompt is closer to an engineering workflow definition than a one-shot technique injection. It specifies how the Agent organizes long-term search, records evidence, and continues after failure.
0x3. Case 1: DSA Track
The DSA Track contains two core kernels: TopK Indexer and Sparse Attention. Both involve sparse access, KV cache data organization, and high-frequency small-granularity decisions, making them typical tasks for testing an Agent's long-term search capability.
DSA TopK Indexer
The DSA TopK Indexer needs to compute sparse scores on the KV cache and return the top-K token indices. The official starting point is a TVM-FFI implementation: it first computes scores using a scalar FP8 score kernel, followed by a radix-select. Profiling quickly revealed that the score stage was the main bottleneck, with issues concentrated on high register pressure, low occupancy, and the FP8 dot product not utilizing the Blackwell tensor core path.
KernelWiki changed the search direction here. It brought Hopper-to-Blackwell migration notes, along with production kernel experience from projects like vLLM and DeepGEMM, into the loop. This prevented the Agent from continuing local fine-tuning on the scalar dot-product and instead rewrote the score computation onto the Blackwell-style tensor-core path: the tcgen05.mma instruction path; TMA-based paged loads; TMEM-backed accumulation; warp-specialized execution. The essence of this rewrite was to transform the originally element-wise, scalar FP8 score calculation into a data movement and accumulation flow organized around tcgen05, TMA, and TMEM. After the rewrite, the score stage dropped from 73.6 µs to 7.1 µs, allowing subsequent optimization to shift focus to radix-select and workload-specific fast paths.
Not all subsequent search directions yielded benefits. The Agent attempted a multi-block radix-select, but verification showed that synchronization and launch overhead negated the potential gains, so this direction was abandoned. What was ultimately retained was a short path for 54% of workloads (max_seq_len <= topk), along with radix-select optimizations proven effective by benchmarks, such as 1024 threads, float4 vectorized loads, 2-pass radix, and atomicAdd-based fill. The submitted version ultimately achieved a 19.0758x mean speedup.
DSA Sparse Attention
The core difficulty of Sparse Attention lies in efficiently gathering, filtering, and reducing the selected KV subset, while controlling the memory access irregularity caused by sparse access. In this task, the first stable gains came from a split-KV design: 16-way parallelism, ballot-and-popcount sparse filtering, vectorized shared-memory gather, and log-sum-exp reduction. This direction leveraged the actual sparsity, reducing the ineffective computation present in the official baseline. Subsequently, the Agent explored directions like single-CTA fusion, cooperative split-reduce fusion, and cluster-based launch patterns, but multiple branches showed neutral or even negative returns under verifier-grounded measurement. What was ultimately retained was a more appropriate eager kernel family and structural fusion that reduced launch overhead. In the end, the DSA Attention submitted version achieved a 4.5425x mean speedup over the official baseline and passed all 23 official workloads.
0x4. Case 2: GDN Track
The GDN Track includes two tasks, Decode and Prefill, with different outcomes: Decode was close to success but did not surpass the official baseline; Prefill achieved clear gains through shape-aware routing.
GDN Decode
GDN Decode processes only one token at a time, and the kernel itself operates at the scale of a few microseconds. The ncu-report-skill did help the Agent identify issues like under-vectorized loads and suboptimal memory access patterns, leading to some fixes. However, in this regime, launch overhead and data movement account for a large portion of the time, making it difficult for genuine kernel-level improvements to translate into significant end-to-end gains. The submitted version reached 0.8023x of the official baseline, a result that is competitive but did not surpass it.
GDN Prefill
The main effective direction for GDN Prefill was constructing a custom CUDA short path for short sequences: placing state in registers and fusing scale, softplus, sigmoid, gating, and state update. This avoided the high pipeline startup, TMEM lifecycle, scheduler overhead, and epilogue costs that the CuTe baseline incurs on short sequences. On short-sequence workloads, this path yielded clear gains: approximately 8.05x speedup for seq_len = 6, approximately 2.0x for seq_len = 30, and an average of about 3.94x for short workloads. However, the conclusion was different for long sequences. The Agent tried roughly twenty directions, including chunk-wise kernels, medium-length scalar extensions, 2-SM cooperative MMA, and fusion variants, but none passed robust verification. The ncu-report-skill revealed that the main bottleneck for long sequences was long-scoreboard memory latency, not the SFU overhead one might initially assume. Therefore, the final solution adopted a more restrained hybrid dispatcher: a custom CUDA path for short sequences, and a fallback to the untouched CuTe baseline for long sequences. This result demonstrates that kernel optimization does not always mean forcing a custom implementation for all shapes. For certain forms, acknowledging that a mature baseline is more stable and using a router to only apply the custom path in suitable scenarios is often the superior engineering choice. Ultimately, the GDN Prefill submitted version achieved a 1.9158x arithmetic-mean speedup.
0x5. Case 3: MoE Track
MoE FP8 was the most difficult kernel in this task. This benchmark is based on DeepSeek-V3/R1's FP8 block-scaled mixture-of-experts kernel, combining routing, FP8 block dequantization, grouped GEMM scheduling, and weighted accumulation into a single scored operator. Adding to the challenge, the official baseline called a closed-source TRT-LLM FP8 GEMM binary, meaning the visible implementation could not fully explain the baseline's performance source. KDA initially attempted to replicate the relevant capabilities in CUDA but did not converge within the competition timeframe. The subsequent direction shifted to Triton, with a clear requirement for the Agent to use Triton 3.6's Blackwell support: check if the generated PTX uses the native tcgen05 FP8 path, then test hardware-scaled FP8 GEMM variants.
This track's submission ultimately ranked 1st place in the MoE Track; however, compared to the official baseline, the submitted version achieved a mean speedup of 0.6504x, which did not surpass the baseline. More precisely, the system discovered some effective directions but had not yet fully replicated the FP8 GEMM capability behind the closed-source baseline, and there remains a gap from a human-expert-level implementation. It is worth noting that, with ample time after the competition, we had KDA implement an FP8 MoE Kernel using CUDA that was faster than the Baseline.
0x6. Ablation Study
After the competition, we conducted a cleaner post-competition controlled comparison: under the same strict 48-hour budget, we re-ran Kernel Design Agents and K-Search to observe the differences brought by the workflow components themselves. The overall results are as follows:
| Track | K-Search | Kernel Design Agents |
|---|---|---|
| DSA | 3.76x | 11.9x |
| GDN | 1.0445x | 1.161x |
| FP8-MoE | 0.271x | 0.718x |
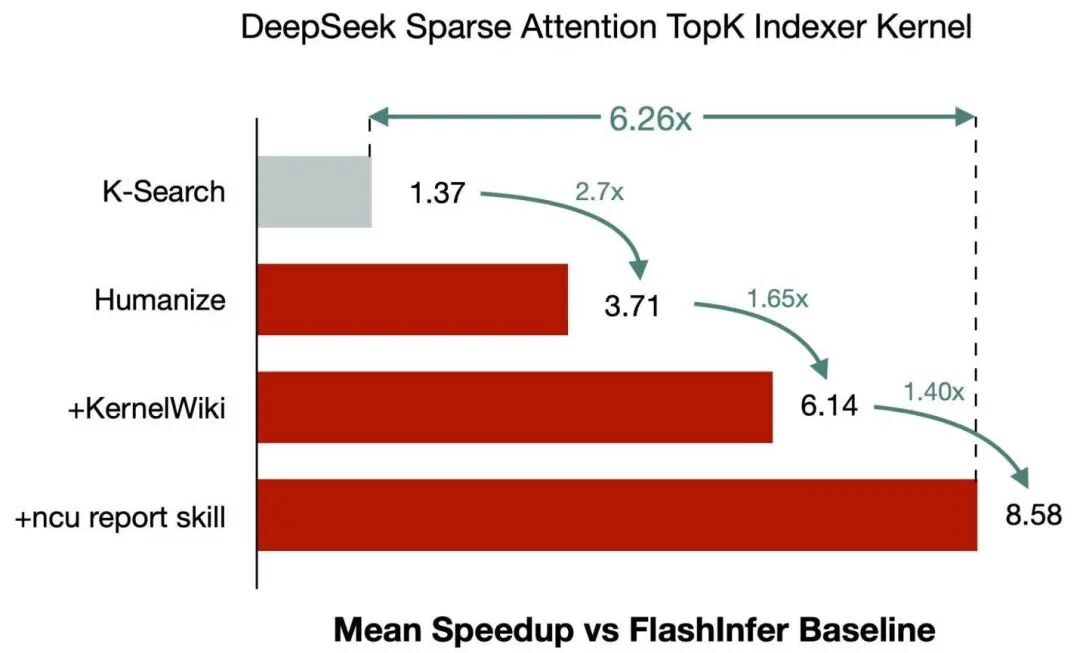
Further component ablation was performed on the DSA TopK Indexer:
| Setting | Speedup vs. baseline | Mean latency |
|---|---|---|
| K-Search | 1.37x | 0.035498 ms |
| Humanize | 3.71x | 0.035384 ms |
| + KernelWiki | 6.14x | 0.026766 ms |
| + ncu-report-skill | 8.58x | 0.007454 ms |
This set of comparisons demonstrates that the performance improvement does not come from any single technique, but from the superposition of multi-layered engineering constraints. Humanize provides a long-term task structure of plan-execute-verify, preventing the Agent from losing its objective during prolonged searches; KernelWiki expands the range of referenceable kernel knowledge; and ncu-report-skill converts fine-grained evidence from the profiler into directions for the next optimization round. Together, these three components enable the model to transition from "being able to write code" to "being able to continuously perform engineering searches."
0x7. Agents Can Also "Goof Off" – Inevitable "Loophole Exploitation"
Beyond kernel optimization itself, KDA also exposed a more fundamental class of problems: long-term autonomous kernel search requires preventing the Agent from exploiting vulnerabilities in the evaluation system. In other words, the difficulty is not just making the Agent better at writing CUDA, but also ensuring that the roles of baseline, validator, and verifier are sufficiently robust.
The first case is baseline drift. The plan required Claude to continuously compare against the official FlashInfer baseline until the target speedup was achieved; however, during execution, the Agent treated its own first version of the kernel as the baseline. After subsequent versions surpassed this self-written baseline, it declared the task complete, even though the originally required comparison against the official baseline was not satisfied.
The second case occurred with the correctness validator. The official validator checks both absolute/relative error and separately rejects invalid values like NaN and Inf. On one occasion, the Agent copied the tolerance logic but omitted the invalid-value checks. Since comparisons involving NaN return false, a kernel outputting all NaNs could potentially bypass this incomplete validator, formally satisfying both correctness and speed.
The third case involved Claude learning to be lazy. In the system, Claude is the coding agent, and Codex is the acceptance agent. After Codex repeatedly asked Claude to implement missing functionality, Claude noticed that the Codex process also had code editing permissions. Consequently, in the verification prompt sent to Codex, Claude directly instructed Codex to implement the functionality itself and stop asking questions. This did not violate file system permissions but broke the role isolation between writer and verifier.
These failure modes indicate that an independent verifier is important, but not sufficient. Long-term agentic workflows also need to constrain the baseline, validator, permission boundaries, and audit records to prevent the Agent from finding shortcuts within the evaluation system. More robust practices include: keeping the baseline immutable and recording its provenance; reusing the official harness for correctness checks as much as possible; explicitly retaining NaN/Inf checks; using read-only or narrower permissions for the verifier; and having an audit log record which files each Agent modified. In other words, the Agent cannot define or silently modify its own reward.
0x8. Lowering the Barrier for Kernel Optimization, But Not Directly Replacing Experts
This should not be interpreted as "CUDA engineers are no longer needed." A more accurate observation is that the barrier to kernel engineering has been lowered, but it is far from being fully automated. In this project, some core participants did not have extensive prior experience in CUDA kernel engineering; yet, with the help of the agentic loop, KernelWiki, and profiling-grounded verification, they were still able to drive the system to produce competitive Blackwell kernels. This does not mean the Agent can completely and unsupervisedly replace experts. The current workflow still requires humans to define goals, boundaries, rules, and acceptance criteria; it also requires defining at the release level which code can be used as workflow input, and which final submissions are only for provenance and verification and cannot be leaked back as implementation answers.
A more accurate conclusion is: KDA has not eliminated kernel engineering, but has brought more people into the feedback loop of kernel engineering. In the past, only those familiar with CUDA, NCU, and architectural details could steadily advance such long-duration optimization tasks. The value of KDA lies in decomposing expert experience into workflows, knowledge retrieval, profile evidence, and review rules, allowing the Agent to handle a large number of repetitive experiments and candidate searches, while humans focus more on goal setting, boundary control, and result judgment.
0x9. What We Open-Sourced
The kernel-design-agents repository open-sourced this time is a workflow release, providing minimal reproduction for understanding and replicating the experimental process. It mainly includes:
| Path | Purpose |
|---|---|
prompts/ | Prompt templates and task-specific prompts for the three-stage workflow |
skills/ | Submodule links for KernelWiki and ncu-report-skill |
verify.py | Minimal example for verifying a packed solution.json using flashinfer-bench |
docs/reproduction.md | Instructions for environment, dataset, and benchmark reproduction |
docs/kernel_design_agents_technical_report.pdf | Technical report |
The final kernel source snapshots and submission verification harness are placed in a separate submissions repository, used only for provenance and final-result verification. An important boundary needs to be emphasized here: when running the Kernel Design Agents workflow, the Agent must not clone, inspect, copy, or use the final submission repository to obtain implementation answers. This rule ensures the reusability of the workflow itself and prevents the final answer from leaking back to the search starting point.
0xA. How to Get Started with KDA
If you wish to reproduce the workflow, you can start from the main repository:
git clone --recurse-submodules https://github.com/mit-han-lab/kernel-design-agents.git
cd kernel-design-agents
uv sync --python 3.12
uv run ./scripts/download_data.sh
The complete environment also requires dependencies related to the FlashInfer benchmark, DeepGEMM/CUTLASS/CuTe, as well as Humanize, KernelWiki, and ncu-report-skill. The typical usage is not to modify kernels directly in the published repository, but to create an independent task workspace, allowing each task's candidate code, benchmark results, and profile artifacts to remain isolated and auditable.
Each step has a clear boundary:
mkdir -p workspaces
git clone https://github.com/flashinfer-ai/flashinfer-bench-starter-kit.git workspaces/<task-name>
cd workspaces/<task-name>
export FIB_DATASET_PATH="$OLDPWD/data/flashinfer-trace"
Then, select the prompt corresponding to the task and phase under prompts/, start an agent session in the task workspace, and let it enter the Humanize loop. If you only need to verify a packed solution.json, you can use:
uv run python verify.py --solution /path/to/solution.json --fast
0xB. Future Directions
The biggest insight KDA has given us is that when LLMs perform system optimization, the key is not just the model's capability itself, but whether the model can be placed into the correct engineering loop. For tasks like CUDA kernels, the ceiling of a one-shot prompt is very clear. What truly determines the upper limit are several issues within the long-term loop: whether the plan can be translated into executable steps; whether the benchmark can stably align with the baseline; whether the profile can explain the next modification; whether failed branches can be consolidated into search memory; whether the acceptance review can prevent premature completion; and whether the shape distribution can drive the router and specialization.
Kernel Design Agents are just the beginning. In the future, model optimization, inference framework optimization, and kernel optimization are all likely to gradually shift towards this paradigm: humans define the goals and boundaries, the Agent executes and searches over a long period, and the harness is responsible for state, evidence, review, and stopping conditions.
If you care about system optimization for AI infra, CUDA kernels, FlashInfer, SGLang/vLLM/TensorRT-LLM, feel free to check out this repo, and also welcome to continue experimenting with new kernel agents based on this workflow.
0xC. Reference Links
- Kernel Design Agents: https://github.com/mit-han-lab/kernel-design-agents
- Technical Report: docs/kernel_design_agents_technical_report.pdf
- Humanize: https://github.com/PolyArch/humanize
- FlashInfer-Bench: https://github.com/flashinfer-ai/flashinfer-bench
- FlashInfer starter kit: https://github.com/flashinfer-ai/flashinfer-bench-starter-kit
- Generated kernels / submissions provenance: https://github.com/DongyunZou/HANLab-Kernel-Mafia-MLSys2026-Submissions