
Paper link: https://arxiv.org/abs/2605.16928
Long-context capability has become a fundamental requirement for modern large language models, but the quadratic computational complexity of Full Attention with respect to sequence length constitutes a core bottleneck during inference. To alleviate this issue, the industry has mainly explored two technical routes:
- Training-free sparse attention: Heuristic rules (e.g., Token Eviction, KV cache compression) are used to directly prune the attention matrix during inference. However, this "train-inference inconsistency" strategy often disrupts the attention patterns learned during pre-training, leading to significant accuracy degradation on complex tasks.
- Native sparse architectures: Full Attention is replaced with novel efficient attention modules (e.g., Kimi Delta Attention, DeepSeek Sparse Attention) and introduced during pre-training or continued pre-training. Although accuracy is guaranteed, the cost is extremely high training overhead and potential risks to model convergence stability.
Drawing on recent interpretability research, we observe a key phenomenon: models trained with Full Attention already exhibit a high degree of "native sparsity" at both the head and token levels. This naturally leads to our core research question: Can we convert a Full Attention model into an efficient sparse model with minimal adaptation cost (Minimal Surgery), while strictly preserving its original capabilities?
To answer this question, we need a sparse strategy that adapts as closely as possible to the model's native sparsity. We identify three major challenges:
- How to distinguish which attention heads rely on local information and which rely on full-context information?
- For heads that rely on full-context information, how to efficiently determine which tokens are important?
- How to ensure high sparsity for any query while maintaining accuracy?
To address these, we propose RTPurbo. Through lightweight training (only about 600 steps, consuming approximately 1M Label Tokens), RTPurbo achieves up to 9.36× Prefill acceleration and 2.01× Decode acceleration without requiring native sparse pre-training, while maintaining near-lossless accuracy on mainstream long-text and reasoning benchmarks.
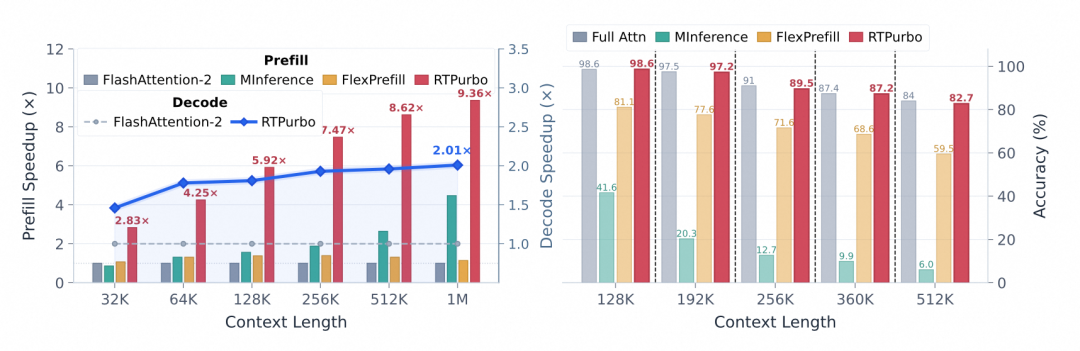
Figure 1: RTPurbo significantly reduces inference latency while preserving accuracy.
Core Insight: Deep Analysis of LLM Native Sparsity
The core idea of RTPurbo is not to forcibly alter the model through pruning, but to activate the native sparse characteristics already formed during Full Attention model training via "surgical" fine-tuning. This property exhibits strong regularity across three dimensions:
Functional Differentiation of Attention Heads: A Natural Heterogeneous Prior
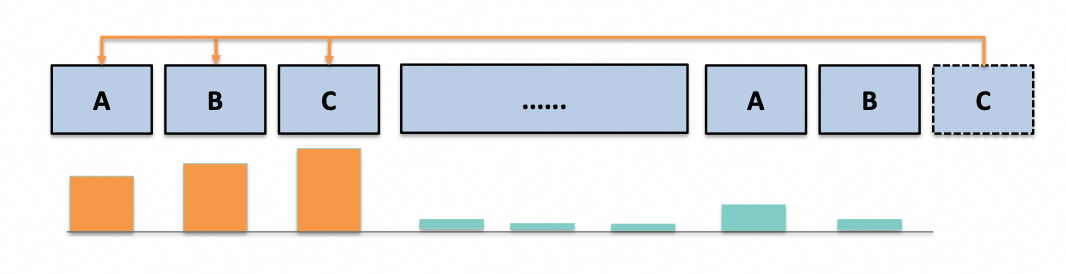
Figure 2: Unlike most attention heads that focus only on local information, Retrieval Heads attend to regions semantically related to the current query token, even if those regions are far apart in the context.
Similar to the human reading and writing process, when processing long texts, LLMs tend to first "retrieve" relevant information from the long context, then perform reasoning and output answers within a relatively local context. Research shows that the vast majority of attention heads primarily handle local contextual information, with very weak perception of distant information. In contrast, only a few specific functional heads are responsible for retrieving semantically related information across long distances—these are what we define as Retrieval Heads. This functional differentiation implies that the model's long-range retrieval capability is not uniformly distributed but concentrated in specific deep channels.
To verify this, we selected some long texts and inserted two needle texts—one at the beginning and one at the end. By testing the attention recall of the latter needle text toward the former, we scored each head. The results in Figure 3 support this conclusion. This functional specialization provides us with a natural sparse prior: for most local heads, we can safely compress the KV cache, while precisely allocating limited computational resources to the 15% of retrieval heads.
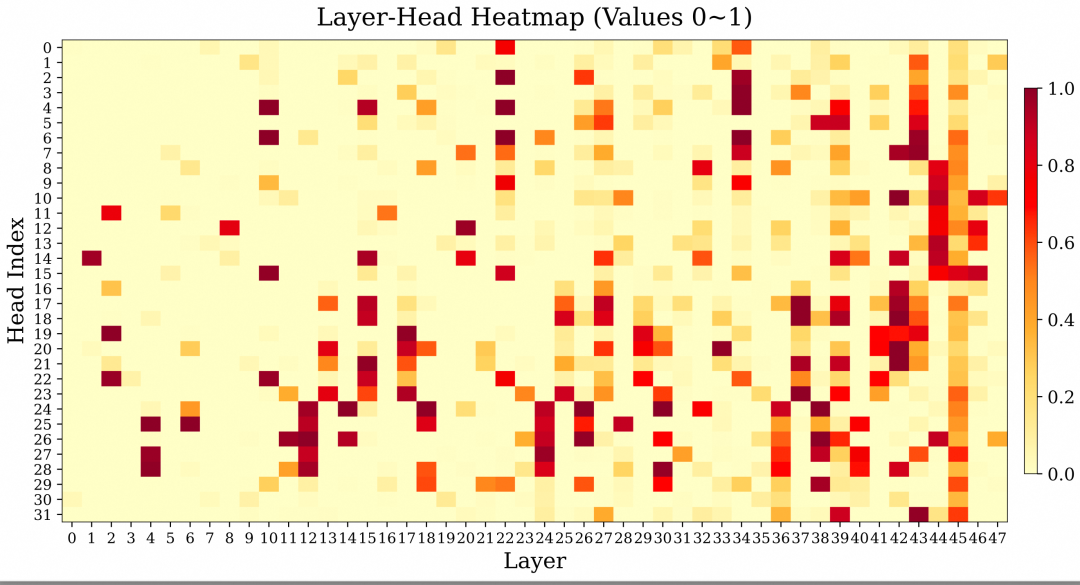
Figure 3: Recall score distribution of query heads in the Qwen3-Coder-30B-A3B model. Most heads only focus on local information.
Geometric Compressibility Under RoPE Encoding: Theoretical Basis for Low-Dimensional Retrieval Space
Modern LLMs typically employ RoPE. However, the retrieval behavior of retrieval heads faces a geometric paradox: regardless of how far semantically related tokens are, retrieval heads must assign them high scores, which contradicts RoPE's inherent "long-term decay" property. Through frequency-domain decomposition of the attention mechanism, we reveal the underlying principle:

The formula shows that when the distance between two tokens increases, high-frequency components with larger change very rapidly, causing most information to be poorly preserved; low-frequency components are less affected, exhibiting smooth distance invariance and forming the backbone of long-range retrieval.
Based on this, we propose a second core observation: we can accurately reconstruct the attention distribution of retrieval heads in a very small dimensional space. Instead of brute-force searching in the original high-dimensional space (e.g., 128 dimensions), we only need to extract low-frequency structures to construct an extremely low-dimensional subspace, enabling precise reconstruction of the retrieval head's attention map at very low computational cost.
Dynamic Token Selection Strategy: Breaking the Fixed Budget Curse
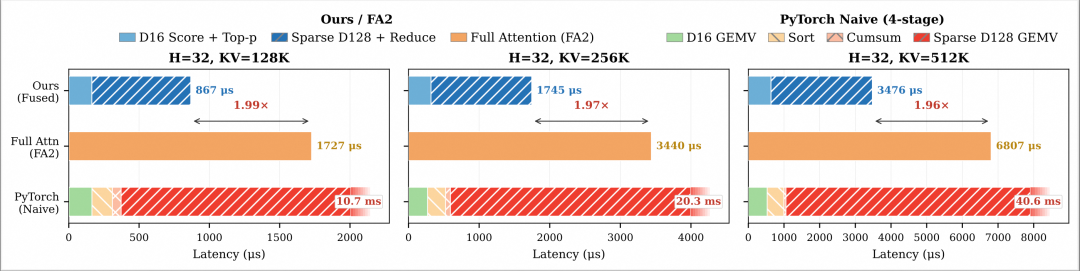
Figure 4: The behavior of retrieval heads is highly query-aware.
After determining the retrieval space, how do we define the boundary for retaining tokens? We find that the token budget required by the model is deeply coupled with the nature of the specific task. A fixed Top-k strategy faces severe robustness challenges in long-text reasoning.
- In complex long-text understanding or multi-hop logical reasoning tasks: For example, answering open-ended questions like "What is the governance model of the Galápagos Islands?" requires the model to gather a large number of semantically related clues from a background of hundreds of thousands of words. In this case, the attention distribution is broad, potentially requiring more than 8k tokens to recover 90% of the attention mass. If a small Top-k budget is rigidly maintained, critical semantic information will inevitably be lost.
- In highly targeted retrieval tasks like "Needle in a Haystack" (NIAH): The model only needs to locate a few key factual anchor points. Here, the attention distribution is highly deterministic, often requiring only 2 tokens to cover over 96% of the attention quality. In such scenarios, any overly large fixed budget (e.g., Top-4k) introduces over 99% computational redundancy.
Based on this observation, we should abandon static sparse strategies and adopt a dynamic token selection strategy: automatically adjusting the number of retained tokens based on the difficulty of the current query and the task context.
RTPurbo
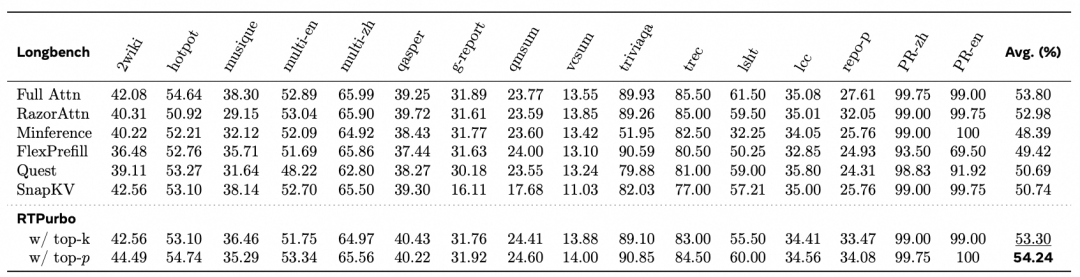
Figure 5: Overall algorithm structure of RTPurbo.
In the methodology section, we shift focus to the specific implementation path of RTPurbo. The core architecture of RTPurbo consists of three algorithmic components and one underlying engineering optimization operator, designed to translate the theoretical insights above into efficient inference capabilities through hardware-software co-design.
Offline Head-wise Calibration
To accurately identify the functional roles of different heads, we perform a one-time offline calibration process to classify query heads. Specifically, we insert identical "Needle" sequences at the beginning and end of a long text document, and compute the attention score of the latter sequence toward the former as the head's retrieval score.

Using this score, we sort query heads from high to low. Based on the setting, we select a certain proportion of heads as retrieval heads , and the rest as local heads .
Dynamic Sparse Attention
During inference, RTPurbo applies different computation modes to the two types of heads to balance computational efficiency and KV cache retention:
- Local heads : Throughout the entire inference cycle, a sliding window attention (SWA) strategy with Attention Sink is always used.
- Retrieval heads : During the prefill phase, full causal attention is computed to build and maintain the complete KV cache. During the decode phase, query-aware dynamic sparse selection is introduced. A trained low-dimensional projection matrix is used to compress Q and K before RoPE, and the query's attention distribution is reconstructed. Then, a dynamic Top-p strategy is applied to select the key Active Token Set from the global KV cache.
Perform sparse attention computation.

Lightweight Two-Stage Training
To fully restore model performance under the sparse mechanism, we design an extremely low-cost training pipeline:
Stage 1 – Low-dimensional projection alignment: Freeze the backbone of the large model and train only the low-dimensional projection parameters for the recall head. By minimizing the KL divergence between the projected distribution and the original full distribution, long-range retrieval signals are compressed into a subspace.

Stage 2 – End-to-end self-distillation: Enable sparse mode and use the original unsparse weights as the “teacher” to perform end-to-end self-distillation training. For efficiency, only the top-10 logits of the teacher model need to be aligned during training, greatly reducing training overhead. The entire process typically converges perfectly in just a few hundred steps.

Kernel Optimization: Efficient Top-P Decode
Figure 6: Flowchart of the efficiently optimized Top-P decode operator
A naive Top-p implementation usually requires first sorting all scores and then performing a cumulative sum to find the truncation threshold. If this conventional approach were directly applied to the RTPurbo design, the entire decode process would be forced into four discrete stages: low-dimensional GEMV (feature scoring) → Sort (global sorting) → Cumsum (cumulative addressing) → Sparse GEMV (sparse attention computation). In particular, the sorting step introduces extremely high overhead that can completely negate the theoretical gains from sparse computation. To thoroughly break this engineering bottleneck, we optimize the process in a targeted manner:
Histogram-based sort-free Top-p: We divide the compressed Key sequence into multiple blocks. After each CTA (Compute Thread Array) completes block-level low-dimensional scoring, instead of performing any sorting, it directly accumulates the scores into a 256-bin global histogram via atomic operations. This histogram requires only 1 KB of minimal GPU memory per head. The last CTA to finish computation simply scans this histogram, and with only additional memory overhead, it can directly determine the Top-p threshold and generate the block mask. This elegant design seamlessly merges scoring and threshold selection into a single kernel launch.
Bandwidth-optimized sparse computation: For long sequences that still have large spans after selection, we design a single-warp CTA structure without shared memory. By keeping all intermediate states in registers, we maximize the number of concurrent memory requests at the SM level, and through vectorized loads (e.g., half2 instructions), we achieve deep overlap between sparse attention computation and memory access latency.
Figure 7: Single-operator speedup of the decode kernel
Single-kernel benchmark results show that our optimized operator not only completely outperforms the naive 4-stage implementation based on PyTorch, but also demonstrates significant advantages over the highly optimized FlashAttention 2, delivering stable sparse gains.
Experimental Evaluation
To comprehensively validate the effectiveness of RTPurbo, we conduct extensive evaluations on Qwen3-Coder-30B-A3B (for long-text understanding) and the reasoning model Qwen3-30B-A3B-Think (for long CoT reasoning tasks), and perform rigorous comparisons with other SOTA works.
Accuracy Evaluation: Long-Text Understanding & Long Reasoning Chain
Long-Context Understanding (LongBench & RULER)
Figure 8: LongBench evaluation results
Figure 9: RULER 32K and RULER 64K evaluation results
Traditional methods based on heuristic rules or local block sparsity expose clear shortcomings when faced with complex tasks. For example, in tasks such as Multi-Q, Multi-K, and Multi-V, local context often deviates from global key information, causing methods like MInference, FlexPrefill, and Quest to suffer severe accuracy degradation. In addition, baselines using a static Top-k budget perform poorly at 64K length due to insufficient recall. In contrast, RTPurbo’s dynamic Top-p selector precisely adapts to the complexity of different queries, not only maintaining a lead under basic settings but also demonstrating absolute robustness when extrapolating to ultra-long contexts (up to 512K). While most baselines experience catastrophic collapse at extreme lengths, RTPurbo maintains a high level of accuracy.
Long CoT Reasoning (AIME24/25 & MMLU-PRO)
Figure 10: Reasoning task evaluation results
Modern mathematical and logical reasoning tasks (e.g., AIME) exhibit extreme “generation asymmetry”: the input prompt is often fewer than 300 tokens, but the model’s generated reasoning chain of thought (CoT) can be as long as 32K tokens, pushing the computational bottleneck entirely into the decode stage. In such demanding long-decode scenarios, RTPurbo achieves near-lossless accuracy retention. On the AIME benchmark, RTPurbo achieves a full score (86.67) identical to the full-attention teacher model. In the MMLU-PRO sub-discipline tests, its performance closely tracks the full-attention baseline, fully demonstrating that after sparsification, the model does not lose its deep general reasoning ability.
Sparsity & Speedup Evaluation: Dynamic Strategy Unleashes Extreme Performance
Beyond accuracy, RTPurbo also shows tremendous advantages in sparsity and acceleration:
Highly Adaptive Dynamic Sparsity
Figure 11: RTPurbo’s sparsity dynamically adjusts across different tasks
RTPurbo’s core advantage lies in completely abandoning the static Top-k strategy. Analysis of the features from a recall head in the decode stage shows that the optimal token budget is highly query-aware: under a 32K context, for the needle-in-a-haystack task (niah-S), RTPurbo retains an average of only 468.8 active tokens; for the more complex Multi-K task, it automatically expands to 2462.1 tokens, a dynamic span of up to 5×.
Figure 12: On ultra-long texts (128K–512K), RTPurbo maintains high sparsity while preserving robust accuracy
Furthermore, this on-demand dynamic mechanism allows RTPurbo to push sparsity above 97.1% while ensuring high accuracy even when the context length is extended to 512K.
End-to-End Efficient Speedup
We conduct a comprehensive comparison of RTPurbo’s single-layer execution efficiency against FA2 and other sparse strategies:
Figure 13: RTPurbo’s attention speedup on long texts
Prefill stage: Thanks to the head-wise sparse strategy, RTPurbo achieves a significant speedup over FA2, ranging from 2.83× at 32K length to 9.36× at 1M length.
Decode stage: With our optimized Top-p decode operator, RTPurbo also delivers stable and substantial gains over FA2, with the speedup steadily increasing from 1.47× at 32K to 2.01× at 1M context.
Conclusion
Our results convey an important insight: expensive native sparse pretraining is not the only path to efficient long-context inference. Through lightweight sparsification adaptation, full-attention models are fully capable of and exhibit outstanding sparse execution performance. This provides a highly promising and theoretically grounded practical path for optimizing and deploying top-tier large pretrained models at extremely low cost in resource-constrained environments.
References
- Paper: https://arxiv.org/abs/2605.16928
- RTP-LLM: https://github.com/alibaba/rtp-llm